微信也在用的Transformer加速推理工具,現在騰訊開源了
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
近年來,基于Transformer的模型,可以說是在NLP界殺出了一片天地。
雖然在提高模型模型精度上,Transformer發揮了不容小覷的作用,但與此同時,卻引入了更大的計算量。
那么,這個計算量有多大呢?
來看下數據。
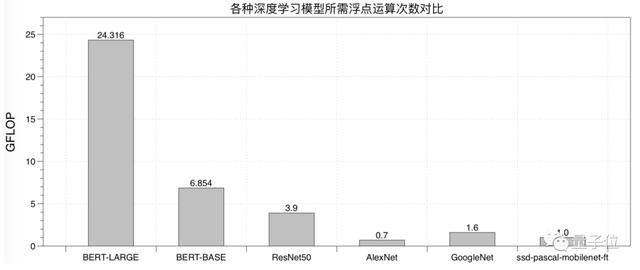
因此,實現一個能充分發揮CPU/GPU硬件計算能力的Transformer推理方法,就成了急需解決的問題。
近日,騰訊便開源了一個叫TurboTransformers的工具,對Transformer推理過程起到了加速作用,讓你的推理引擎變得更加強大。

這個工具已經在微信、騰訊云、QQ看點等產品中廣泛應用,在線上預測場景中可以說是“身經百戰”。
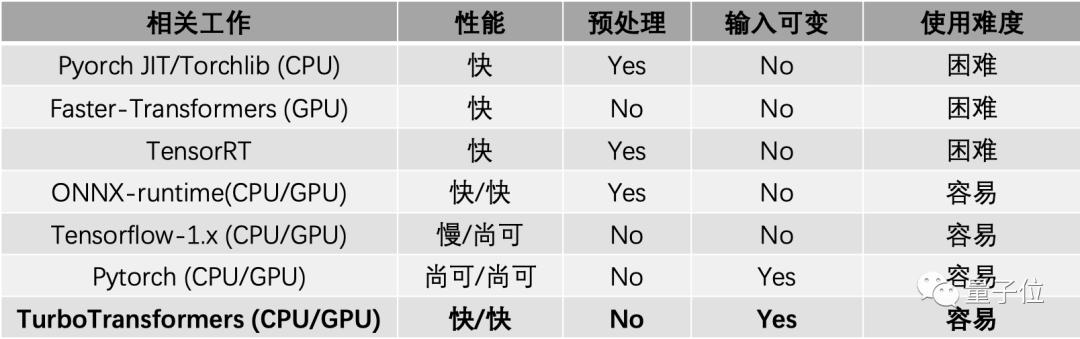
Turbo具有如下三大特性:
- 優異的CPU/GPU性能表現。
- 為NLP推理任務特點量身定制。
- 簡單的使用方式。
值得一提的是,TurboTransformers,是騰訊通過Github對外開源的第100個項目。
那么,具有如此“紀念意義”的開源工具,到底有多厲害?
接下來,我們將一一講解。
多項性能測試“摘桂冠”
Turbo在CPU/GPU性能上的表現可以說是非常優異。
在多種CPU和GPU硬件上獲得了超過pytorch/tensorflow和目前主流優化引擎的性能表現。
CPU上的測試結果
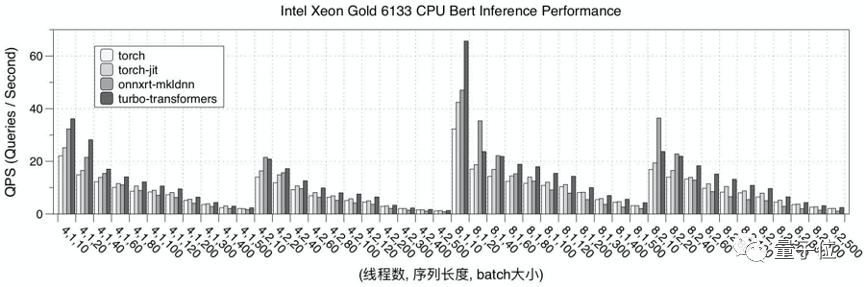
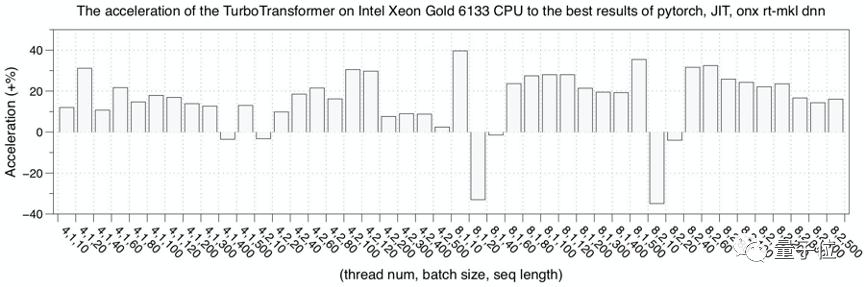
首先,是在CPU 硬件平臺上,測試了 TurboTransformers 的性能表現。
選擇 pytorch、pytorch-jit 和 onnxruntime-mkldnn 和 TensorRT 實現作為對比。
性能測試結果為迭代 150 次的均值。為了避免多次測試時,上次迭代的數據在 cache 中緩存的現象,每次測試采用隨機數據,并在計算后刷新的 cache 數據。
下圖是Intel Xeon 6133 CPU的性能測試結果。
GPU上的測試結果
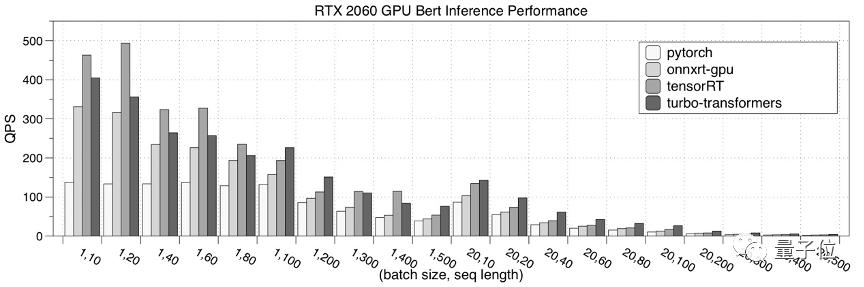
其次,是在GPU硬件平臺上,測試了 TurboTransformers 的性能表現。
選擇對比的對象分別是:pytorch、NVIDIA Faster Transformers、onnxruntime-gpuTensorRT。
性能測試結果為迭代 150 次的均值。
下圖是在NVIDIA RTX 2060 GPU的性能測試結果。
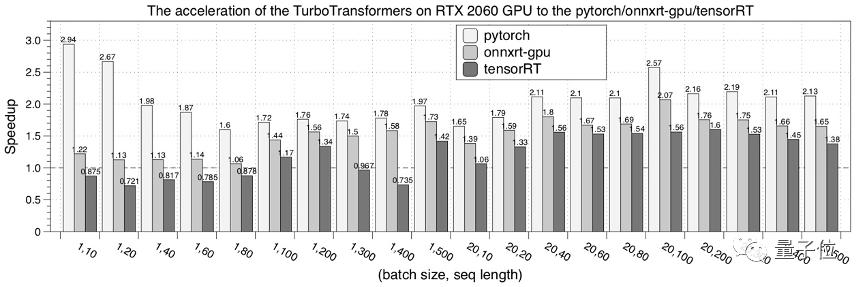
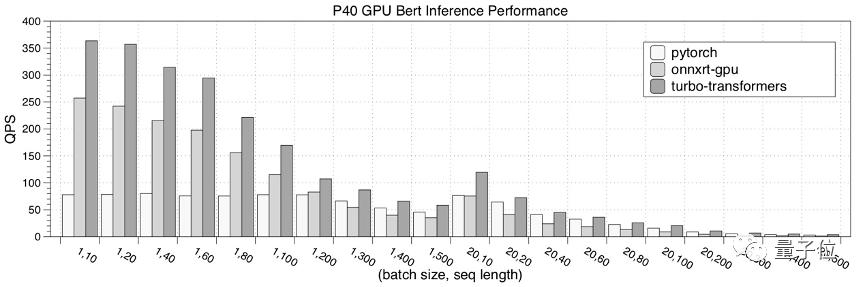
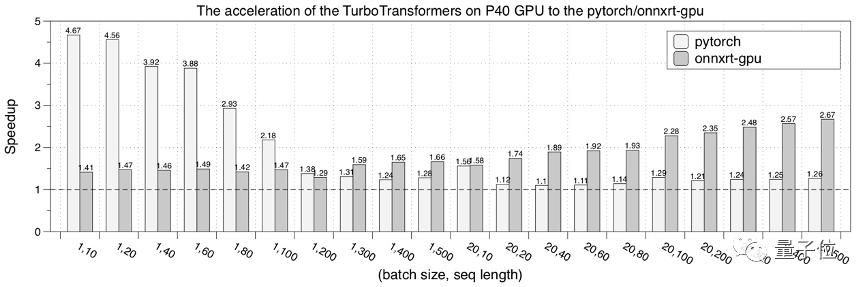
接下來,是在NVIDIA P40 GPU的性能測試結果。
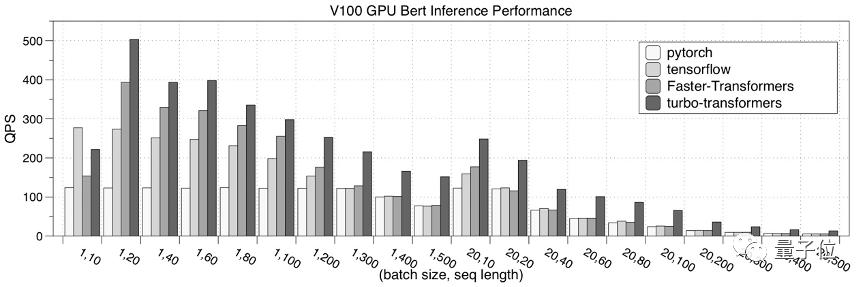
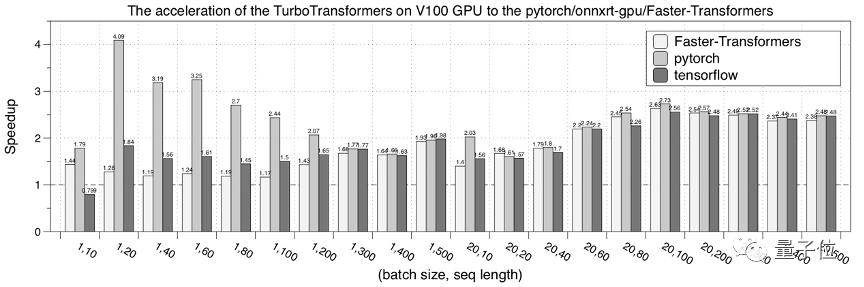
最后,是在NVIDIA V100 GPU的性能測試結果。
Turbo技術原理
能夠取得如此好的推理性能,這背后的計算原理又是什么呢?
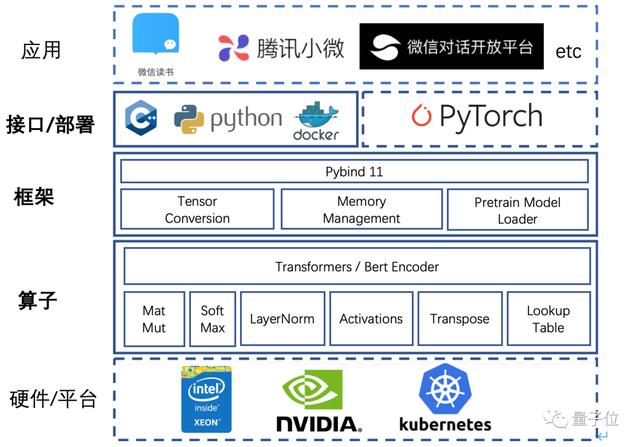
TurboTransformers的軟件架構如下圖,它讓微信內部眾多NLP線上應用能夠充分榨取底層硬件的計算能力,讓算法更好地服務的用戶。
具體來說TurboTransformers可以在算子優化、框架優化和接口部署方式簡化三個方面做了工作。
算子層優化
Transformer都包含了什么計算呢?
如下圖所示,圖(a)展示了論文Transformer結構示意圖,這里稱灰色方框內的結構為一個Transformer Cell,BERT encoder堆疊了Nx個這樣的Transformer Cell。
圖(b)將一個Cell的細節加以展開,每一個矩形都是一個獨立的計算核心。
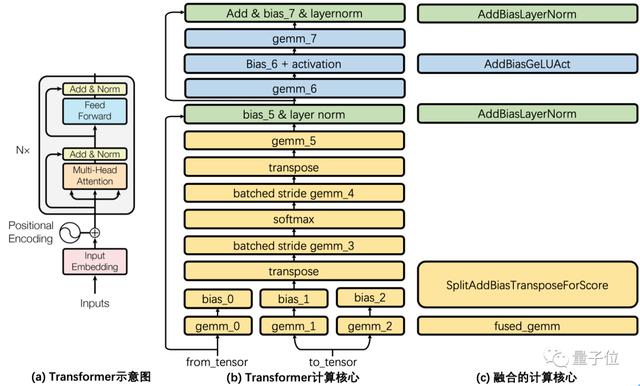
Transformer Cell計算包含了8個GEMM(通用矩陣乘法,General Matrix Multiplication)運算。通過調優Intel MKL和cuBLAS的GEMM調用方式來獲得最佳GEMM性能。
并且在硬件允許條件下,在GPU上使用tensor core方式進行GEMM運算。
類似NVIDIA FasterTransformers方案,將所有GEMM運算之間的計算融合成一個調用核心。融合會帶來兩個好處,一是減少了內存訪問開銷,二是減少多線程啟動開銷。
對于這些核心,在CPU上采用openmp進行并行,在GPU上使用CUDA進行優化實現。
對于比較復雜的LayerNorm和Softmax算子,它們包含了不適合GPU上并行的規約操作,TurboTransformers為它們設計了創新并行算法,極大降低了這些算子的延遲。
理論上Transformers推理延遲應該近似于矩陣乘法延遲。
框架層優化
TurboTransformers采用了一個有效的內存管理方式。
由于NLP的采用變長輸入特性,每次運算中間結果的大小其實并不相同。為了避免每次都分配釋放內存,研究人員通過Caching方式管理顯存。
為了能夠無縫支持pytorch/tensorflow訓練好的序列化模型,提供了一些腳本可以將二者的預訓練模型轉化為npz格式,供TurboTransformers讀入。
特別的,考慮到pytorch huggingface/transformers是目前最流行的transformers訓練方法,支持直接讀入huggingface/transformers預訓練模型。
應用部署
Turbo提供了C++和Python調用接口,可以嵌入到C++多線程后臺服務流程中,也可以加入到pytorch服務流程中。
研究人員建議TurboTransformers通過docker部署,一方面保證了編譯的可移植性,另一方面也可以無縫應用于K8S等線上部署平臺。
傳送門
GitHub項目地址:https://github.com/Tencent/TurboTransformers/blob/master/README_cn.md