讓夢露和龍媽學著你說話,只需一張靜態圖和一個視頻
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
想讓名人學著你說話,怎么辦?
很簡單,只要一張名人的照片,配上你說話的視頻,分分鐘就能搞定。
來看下效果:

無論你是擠眉弄眼,還是搖頭晃腦,照片里的名人們都能跟你神同步!
這就是來自意大利特倫托大學的一項研究:
利用一個一階運動模型 (First Order Motion Model),靜態圖也能動起來,換臉也不在話下。
當然,這么有意思的項目,已經開源了!
一個川普在說話,一群史塔克也有話說
其實,這項研究早在數月前便已發表。
當時用的輸入視頻是川建國同志,靜態照片用的是一組《冰與火之歌》史塔克家族及劇中其他人物圖片。
效果是這樣的:

可以看到,無論川建國同志是眨眼、晃頭,劇中的人物做到了神同步。
就連那張標志性的O型嘴,也“模仿”的惟妙惟肖。
而時隔幾個月,這項技術又在Reddit爆火了起來。
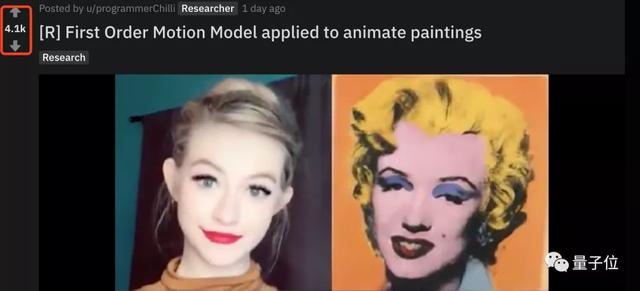
一個可能的原因是,這次輸入的視頻來自流行的短視頻平臺,也就是說我們自己錄一段視頻也能用。
加上效果的逼真、有趣,或許用不了多長時間,短視頻內容平臺可能就會推出這個功能了吧。
當然,這個模型的魔力不止于此。
輸入一個模特換pose的視頻,再配上多張靜態服飾照片,就能批量輸出動態展示服裝的視頻了。

換臉,也是小菜一碟。

不過,也要溫馨提醒一句:慎用靜態照片,不然出來的效果可能就不太像“陽間的東西”了……
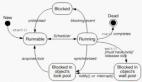
一階運動模型
在訓練階段,研究人員采用了大量的視頻序列集合,包含相同類別的對象。模型通過結合視頻中的單幀,和學習到的潛在運動表示,來訓練重構視頻。
在測試階段,研究人員將模型應用于由源圖像和驅動視頻的每一幀組成的對,并執行源對象的圖像動畫。
模型的框架就如下圖所示:
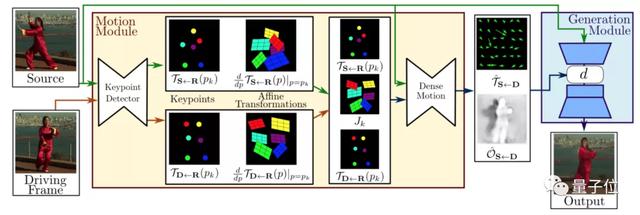
框架主要由2部分構成:運動估計模塊和圖像生成模塊。
運動估計模塊的目的,是預測一個密集的運動場。研究人員假設存在一個抽象的參考框架,并且獨立估計兩個變換,分別是「從參考到源」和「從參考到驅動」。這樣就能夠獨立處理源幀和驅動幀。
研究人員認為這個步驟是必要的,因為在測試時,模型會接收從不同視頻中采樣的源圖像和驅動幀對,它們在視覺上可能非常不同。
在第一步中,研究人員從稀疏軌跡集近似這兩種變換,通過使用以自監督方式學習的關鍵點來獲得。利用局部仿射變換對每個關鍵點附近的運動進行建模。
在第二步中,密集運動網絡結合局部近似得到密集運動場。除此之外,這個網絡還輸出遮擋的mask,指示哪些圖像的驅動部分可以通過源圖像的扭曲(warping)來重建,哪些部分應該被繪制(根據上下文推斷)。
在第三步中,生成模塊按照驅動視頻中,提供的源對象移動的圖像進行渲染。此處,研究人員使用一個生成器網絡,根據密集的運動對源圖像進行扭曲,并對源圖像中被遮擋的圖像部分進行著色。
最后,這個模型已經在GitHub上開源,我們在“傳送門”中已經奉上地址鏈接。
快去試試吧~
傳送門
GitHub項目地址:
https://github.com/AliaksandrSiarohin/first-order-model
論文地址:
https://arxiv.org/pdf/2003.00196.pdf