













一文全覽,ICLR 2020 上的知識圖譜研究
本文轉(zhuǎn)自雷鋒網(wǎng),如需轉(zhuǎn)載請至雷鋒網(wǎng)官網(wǎng)申請授權(quán)。
ICLR 2020 正在進行,但總結(jié)筆記卻相繼出爐。我們曾對 ICLR 2020 上的圖機器學(xué)習(xí)趨勢進行介紹,本文考慮的主題為知識圖譜。
作者做波恩大學(xué)2018級博士生 Michael Galkin,研究方向為知識圖和對話人工智能。在AAAI 2020 舉辦之際,他也曾對發(fā)表在AAAI 2020上知識圖譜相關(guān)的文章做了全方位的分析,具體可見「知識圖譜@AAAI2020」。
本文從五個角度,分別介紹了 ICLR 2020上知識圖譜相關(guān)的 14 篇論文。五個角度分別為:
1)在復(fù)雜QA中利用知識圖譜進行神經(jīng)推理(Neural Reasoning for Complex QA with KGs)
2)知識圖譜增強的語言模型(KG-augmented Language Models)
3)知識圖譜嵌入:循序推理和歸納推理(KG Embeddings: Temporal and Inductive Inference)
4)用GNN做實體匹配(Entity Matching with GNNs)
5)角色扮演游戲中的知識圖譜(Bonus: KGs in Text RPGs!)
話不多說,我們來看具體內(nèi)容。
注:文中涉及論文,可關(guān)注「AI科技評論」微信公眾號,并后臺回復(fù)「知識圖譜@ICLR2020」打包下載。
一、在復(fù)雜QA中利用知識圖譜進行神經(jīng)推理
今年ICLR2020中,在復(fù)雜QA和推理任務(wù)中看到越來越多的研究和數(shù)據(jù)集,very good。去年我們只看到一系列關(guān)于multi-hop閱讀理解數(shù)據(jù)集的工作,而今年則有大量論文致力于研究語義合成性(compositionality)和邏輯復(fù)雜性(logical complexity)——在這些方面,知識圖譜能夠幫上大忙。
1、Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
文章鏈接:https://openreview.net/pdf?id=SygcCnNKwr
Keysers等人研究了如何測量QA模型的成分泛化,即訓(xùn)練和測試 split 對同一組實體(廣泛地來講,邏輯原子)進行操作,但是這些原子的成分不同。作者設(shè)計了一個新的大型KGQA數(shù)據(jù)集 CFQ(組合式 Freebase 問題),其中包含約240k 個問題和35K SPARQL查詢模式。
Intuition behind the construction process of CFQ. Source: Google blog
這里比較有意思的觀點包括:1)用EL Description Logic 來注釋問題(在2005年前后,DL的意思是Description Logic,而不是Deep Learning );2)由于數(shù)據(jù)集指向語義解析,因此所有問題都鏈接到了Freebase ID(URI),因此您無需插入自己喜歡的實體鏈接系統(tǒng)(例如ElasticSearch)。于是模型就可以更專注于推斷關(guān)系及其組成;3)問題可以具有多個級別的復(fù)雜性(主要對應(yīng)于基本圖模式的大小和SPARQL查詢的過濾器)。
作者將LSTM和Transformers基線應(yīng)用到該任務(wù),發(fā)現(xiàn)它們都沒有遵循通用標(biāo)準(zhǔn)(并相應(yīng)地建立訓(xùn)練/驗證/測試拆分):準(zhǔn)確性低于20%!對于KGQA愛好者來說,這是一個巨大的挑戰(zhàn),因此我們需要新的想法。
2、Scalable Neural Methods for Reasoning With a Symbolic Knowledge Base
文章鏈接:https://openreview.net/pdf?id=BJlguT4YPr
Cohen等人延續(xù)了神經(jīng)查詢語言(Neural Query Language,NQL)和可微分知識庫議程的研究,并提出了一種在大規(guī)模知識庫中進行神經(jīng)推理的方法。
作者引入了Reified KB。其中事實以稀疏矩陣(例如COO格式)表示,方式則是對事實進行編碼需要六個整數(shù)和三個浮點數(shù)(比典型的200浮點KG嵌入要少得多)。然后,作者在適用于多跳推理的鄰域上定義矩陣運算。
這種有效的表示方式允許將巨大的KG直接存儲在GPU內(nèi)存中,例如,包含1300萬實體和4300萬事實(facts)的WebQuestionsSP 的 Freebase轉(zhuǎn)儲,可以放到三個12-Gb 的 GPU中。而且,在進行QA時可以對整個圖譜進行推理,而不是生成候選對象(通常這是外部不可微操作)。
作者在文章中對ReifiedKB進行了一些KGQA任務(wù)以及鏈接預(yù)測任務(wù)的評估。與這些任務(wù)當(dāng)前的SOTA方法相比,它的執(zhí)行效果非常好。
事實上,這項工作作為一個案例,也說明SOTA不應(yīng)該成為一篇論文是否被接收的衡量標(biāo)準(zhǔn),否則我們就錯失了這些新的概念和方法。
3、Differentiable Reasoning over a Virtual Knowledge Base
文章鏈接:https://openreview.net/pdf?id=SJxstlHFPH
Dhingra等人的工作在概念礦建上與上面Cohen等人的工作類似。他們提出了DrKIT,這是一種能用于在索引文本知識庫上進行差分推理的方法。
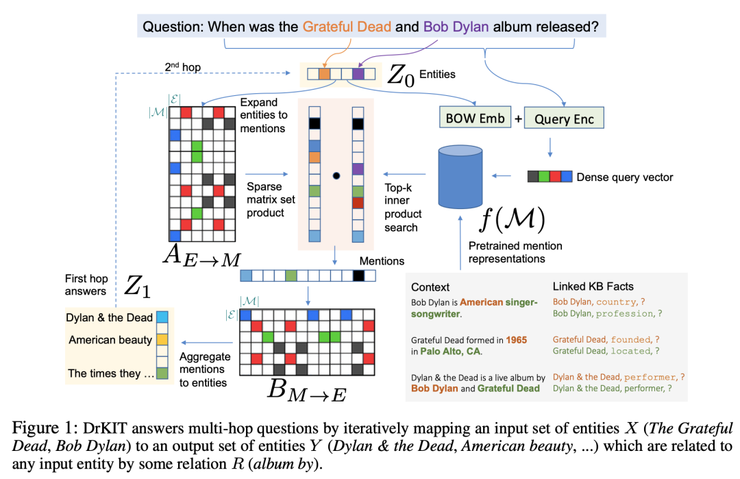
DrKIT intuition. Source: Dhingra et al
這個框架看起來可能會有些復(fù)雜,我們接下來將它分成幾個步驟來說明。
1)首先,給定一個question(可能需要多跳推理),實體鏈接器會生成一組 entities(下圖中的Z0)。
2)使用預(yù)先計算的索引(例如TF-IDF)將一組實體擴展為一組mentions(表示為稀疏矩陣A)。
3)在右側(cè),question 會通過一個類似BERT的編碼器,從而形成一個緊密向量。
4)所有mentions 也通過一個類似BERT的編碼器進行編碼。
5)使用MIPS(Maximum Inner Product Search)算法計算scoring function(用來衡量mentions, entities 和 question相關(guān)分?jǐn)?shù)),從而得到Top-k向量。
6)矩陣A乘以Top-K 選項;
7)結(jié)果乘以另一個稀疏的共指矩陣B(映射到一個實體)。
這構(gòu)成了單跳推理步驟,并且等效于在虛擬KB中沿著其關(guān)系跟蹤提取的實體。輸出可以在下一次迭代中進一步使用,因此對N跳任務(wù)會重復(fù)N次!
此外,作者介紹了一個基于Wikidata的新的插槽填充數(shù)據(jù)集(采用SLING解析器構(gòu)造數(shù)據(jù)集),并在MetaQA、HotpotQA上評估了 DrKIT,總體來說結(jié)果非常棒。
4、Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering
文章鏈接:https://openreview.net/pdf?id=SJgVHkrYDH
Asai等人的工作專注于HotpotQA,他們提出了Recurrent Retriever的結(jié)構(gòu),這是一種開放域QA的體系結(jié)構(gòu),能夠以可區(qū)分的方式學(xué)習(xí)檢索推理路徑(段落鏈)。
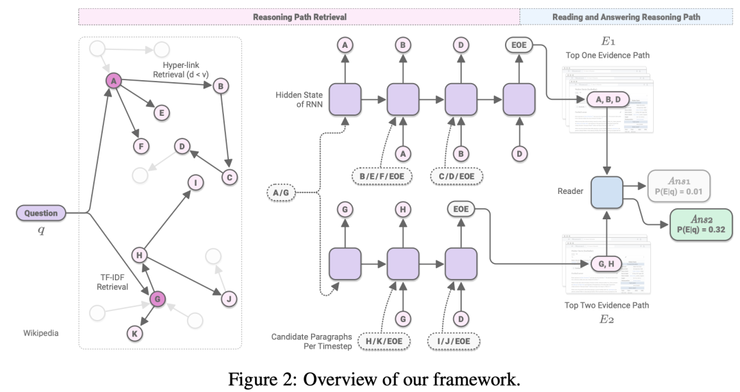
Recurrent Retrieval architecture. Source: Asai et al
傳統(tǒng)上,RC模型會采用一些現(xiàn)成的檢索模型來獲取可能的候選者,然后才執(zhí)行神經(jīng)讀取pipeline。這篇工作則希望讓檢索具有差異性,從而將整個系統(tǒng)編程端到端的可訓(xùn)練模型。
1)整個Wikipedia(英語)都以圖譜的形式組織,其邊表示段落和目標(biāo)頁面之間的超鏈接。例如對于Natural Questions,大小約為3300萬個節(jié)點,邊有2.05億個。
2)檢索部分采用的RNN,初始化為一個隱狀態(tài)h0,這是對問題 q 和候選段落p編碼后獲得的。這些候選段落首先通過TF-IDF生成,然后通過圖譜中的鏈接生成。(上圖中最左側(cè))
3)編碼(q,p)對的BERT [CLS]令牌會被送到RNN中,RNN會預(yù)測下一個相關(guān)的段落。
4)一旦RNN產(chǎn)生一個特殊的[EOE]令牌,讀取器模塊就會獲取路徑,對其重新排序并應(yīng)用典型的提取例程。
作者采用波束搜索和負(fù)采樣來增強對嘈雜路徑的魯棒性,并很好地突出了路徑中的相關(guān)段落。重復(fù)檢索(Recurrent Retrieval )在HotpotQA的 full Wiki測試設(shè)置上的F1分?jǐn)?shù)獲得了驚人的73分。這篇工作的代碼已發(fā)布。
5、Neural Symbolic Reader: Scalable Integration of Distributed and Symbolic Representations for Reading Comprehension
文章鏈接:https://openreview.net/pdf?id=ryxjnREFwH
6、Neural Module Networks for Reasoning over Text
文章鏈接:https://openreview.net/pdf?id=SygWvAVFPr
我們接下來談兩篇復(fù)雜數(shù)字推理的工作。
在數(shù)字推理中,你需要對給定的段落執(zhí)行數(shù)學(xué)運算(例如計數(shù)、排序、算術(shù)運算等)才能回答問題。例如:
文本:“……美洲虎隊的射手喬什·斯科比成功地射入了48碼的射門得分……而內(nèi)特·凱丁的射手得到了23碼的射門得分……”問題:“誰踢出最遠(yuǎn)的射門得分?”
目前為止,關(guān)于這個任務(wù)只有兩個數(shù)據(jù)集,DROP(SQuAD樣式,段落中至少包含20個數(shù)字)和MathQA(問題較短,需要較長的計算鏈、原理和答案選項)。因此,這個任務(wù)的知識圖譜并不很多。盡管如此,這仍然是一個有趣的語義解析任務(wù)。
在ICLR 2020 上,有兩篇這方面的工作。一篇是是Chen 等人的工作,提出了一個神經(jīng)符號讀取器NeRd(Neural Symbolic Reader);另一篇是Gupta等人在神經(jīng)模塊網(wǎng)絡(luò)NMN(Neural Module Networks)上的工作。
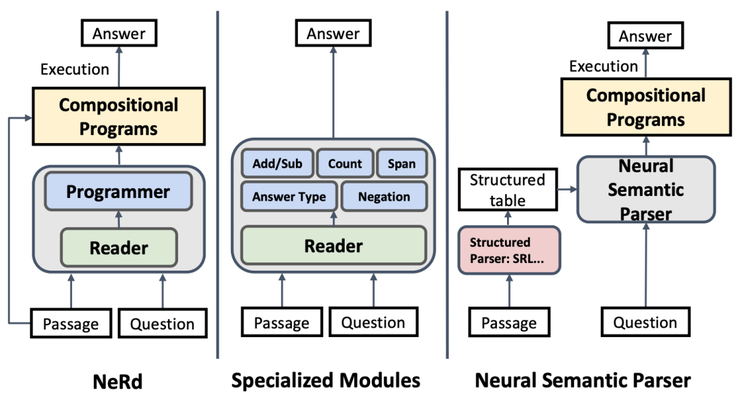
NeRd vs other approaches. Source: Chen et al
兩項工作都是由讀取器和基于RNN的解碼器組成,從預(yù)定義的域特定語言(DSL,Domain Specific Language)生成操作(操作符)。從性能上相比,NeRd更勝一籌,原因在于其算符的表達能力更強,解碼器在構(gòu)建組合程序上也更簡單。另一方面,NMN使用張量交互對每個運算符進行建模,于是你需要手工制定更多的自定義模塊來完成具體任務(wù)。
此外,NeRd的作者做了許多努力,為弱監(jiān)督訓(xùn)練建立了可能的程序集,并采用了帶有閾值的Hard EM 算法來過濾掉虛假程序(能夠基于錯誤的程序給出正確答案)。NeRd 在DROP測試集上獲得了81.7 的F1 分?jǐn)?shù),以及78.3 的EM分?jǐn)?shù)。
對NMN進行評估,其中月有25%的DROP數(shù)據(jù)可通過其模塊來回答,在DROP dev測試中獲得了77.4 的F1 分?jǐn)?shù) 和74 的EM 分?jǐn)?shù)。
二、知識圖譜增強的語言模型
將知識融入語言模型,目前已是大勢所趨。
7、Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model
文章鏈接:https://openreview.net/pdf?id=BJlzm64tDH
今年的ICLR上,Xiong等人在預(yù)測[MASK] token之外,提出了一個新的訓(xùn)練目標(biāo):需要一個模型來預(yù)測entity是否已經(jīng)被置換。
作者對預(yù)訓(xùn)練Wikipedia語料庫進行處理,基于超鏈接,將Wiki的entity表面形式(標(biāo)簽)替換為相同類型的另一個entity。基于P31的「instance of」關(guān)系,從wikidata中獲取類型信息。如下圖所示,在有關(guān)Spider-Man的段落中,實體 Marvel Comics 可以替換為 DC Comics。
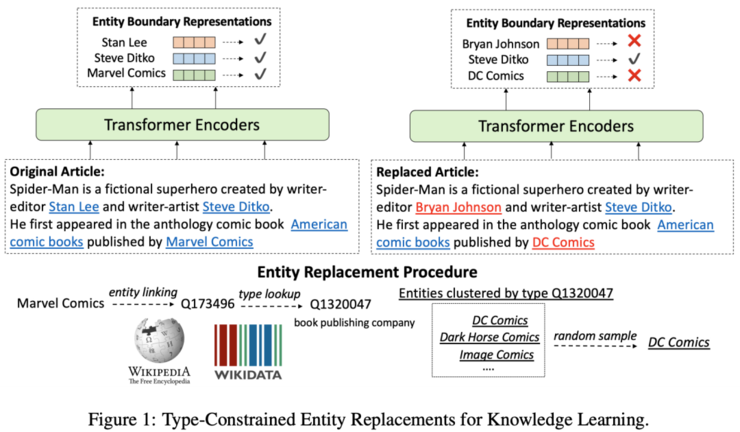
Pre-training objective of WKLM. Source: Xiong et al
模型的任務(wù)是預(yù)測實體是否被替換掉了。
WKLM(Weakly Supervised Knowledge-Pretrained Languge Model)使用MLM目標(biāo)(掩蔽率為5%,而不是BERT的15%)進行預(yù)訓(xùn)練,每個數(shù)據(jù)點使用10個負(fù)樣本,類似于TransE的訓(xùn)練過程。
作者評估了10個Wikidata關(guān)系中的WKLM事實完成性能(fact completion performance),發(fā)現(xiàn)其達到了約29 Hits@10的速率,而BERT-large和GPT-2約為16。
隨后,作者在性能優(yōu)于基準(zhǔn)的WebQuestions,TriviaQA,Quasar-T和Search-QA數(shù)據(jù)集上對WKLM進行了微調(diào)和評估。
總結(jié)一句話,這是一個新穎的、簡單的,但卻有實質(zhì)性意義的想法,有大量的實驗,也有充分的消融分析。
三、知識圖譜嵌入:循序推理和歸納推理
像Wikidata這樣的大型知識圖譜永遠(yuǎn)不會是靜態(tài)的,社區(qū)每天都會更新數(shù)千個事實(facts),或者是有些事實已經(jīng)過時,或者是新的事實需要創(chuàng)建新實體。
循序推理。說到時間,如果要列出美國總統(tǒng),顯然triple-base的知識圖譜,會把亞當(dāng)斯和特朗普都列出來。如果不考慮時間的話,是否意味著美國同時有45位總統(tǒng)呢?為了避免這種歧義,你必須繞過純RDF的限制,要么采用具體化的方式(針對每個具體的歧義進行消除),要么采用更具表現(xiàn)力的模型。例如Wikidata狀態(tài)模型(Wikidata Statement Model)允許在每個statement中添加限定符,以總統(tǒng)為例,可以將在限定符處放上總統(tǒng)任期的開始時間和結(jié)束時間,通過這種方式來表示給定斷言為真的時間段。循序知識圖譜嵌入算法(Temporal KG Embeddings algorithms)的目標(biāo)就是夠條件這樣一個時間感知(time-aware)的知識圖譜表示。在知識圖譜嵌入中時間維度事實上,只是嵌入字(例如身高、長度、年齡以及其他具有數(shù)字或字符串值的關(guān)系)的一部分。
歸納推理。大多數(shù)現(xiàn)有的知識圖譜嵌入算法都在已知所有實體的靜態(tài)圖上運行——所謂的轉(zhuǎn)導(dǎo)設(shè)置。當(dāng)你添加新的節(jié)點和邊時,就需要從頭開始重新計算整個嵌入;但對于具有數(shù)百萬個節(jié)點的大型圖來說,這顯然不是一個明智的方法。在歸納設(shè)置(inductive setup)中,先前看不見的節(jié)點可以根據(jù)他們之間的關(guān)系和鄰域進行嵌入。針對這個主題的研究現(xiàn)在不斷增加,ICLR 2020 上也有幾篇有趣的文章。
8、Tensor Decompositions for Temporal Knowledge Base Completion
文章鏈接:https://openreview.net/pdf?id=rke2P1BFwS
Lacroix等人使用新的正則化組件擴展了ComplEx嵌入模型,這些正則化組件考慮了嵌入模型中的時間維度。
這項工作非常深刻,具體表現(xiàn)在以下幾個方面:1)想法是將連續(xù)的時間戳(如年,日及其數(shù)值屬性)注入到正則化器中;2)作者提出TComplEx,其中所有謂詞都具有time屬性;提出TNTCompEx,其中對諸如「born in」這樣“永久”的屬性進行區(qū)別對待。實驗表明,TNTCompEx的性能更好;3)作者介紹了一個新的大型數(shù)據(jù)集,該數(shù)據(jù)集基于Wikidata Statements,但帶有開始時間和結(jié)束時間限定符,該數(shù)據(jù)集包含約40萬個實體和700萬個事實。
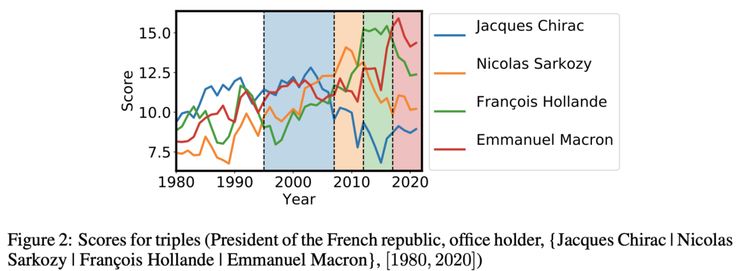
Time-aware ComplEx (TNTComplEx) scores. Source: Lacroix et al
上圖中,你可以看到這個模型如何對描述法國總統(tǒng)的事實的可能性進行評分:自2017年以來,伊曼紐爾·馬克龍的得分更高,而弗朗索瓦·奧朗德在2012–2017年的得分更高。
9、Inductive representation learning on temporal graphs
文章鏈接:https://openreview.net/pdf?id=rJeW1yHYwH
再進一步,Xu等人提出了臨時圖注意力機制TGAT(temporal graph attention),用于建模隨時間變化的圖,包括可以將新的先前未見的節(jié)點與新邊添加在一起時的歸納設(shè)置。其思想是基于經(jīng)典和聲分析中的Bochner定理,時間維度可以用傅里葉變換的時間核來近似。時間嵌入與標(biāo)準(zhǔn)嵌入(例如節(jié)點嵌入)串聯(lián)在一起,并且全部輸入到自注意力模塊中。
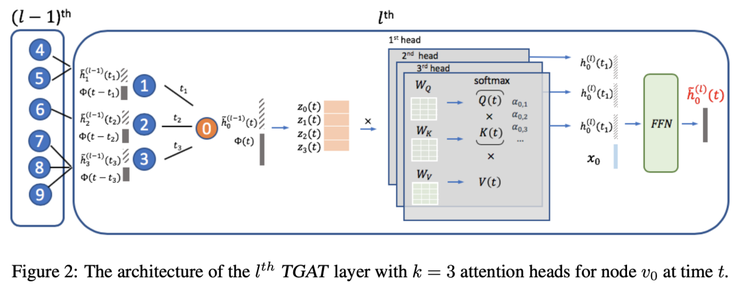
Source: Xu et al
作者將TGAT在具有單關(guān)系圖(不是KG的多關(guān)系圖)的標(biāo)準(zhǔn)轉(zhuǎn)導(dǎo)與歸納GNN任務(wù)上進行了評估,TGAT顯示出了很好的性能提升。個人認(rèn)為,這個理論應(yīng)該可以進一步擴展到支持多關(guān)系KG。
再回到傳統(tǒng)的感應(yīng)式KG嵌入設(shè)置(transductive KG embedding setup):
— GNN?是的!— Multi-多關(guān)系?是的!— 建立關(guān)系的嵌入?是的!— 適合知識圖譜嗎?是的!— 適用于節(jié)點/圖形分類任務(wù)嗎?是的。
10、Composition-based Multi-Relational Graph Convolutional Networks
文章鏈接:https://openreview.net/pdf?id=BylA_C4tPr
Vashishth 等人提出的 CompGCN體系結(jié)構(gòu)為你帶來了所有這些優(yōu)點。標(biāo)準(zhǔn)的圖卷積網(wǎng)絡(luò)以及消息傳遞框架在考慮圖時,通常認(rèn)為邊是沒有類型的,并且通常不會構(gòu)建邊的嵌入。
知識圖譜是多關(guān)系圖,邊的表示對鏈接預(yù)測任務(wù)至關(guān)重要。對于(Berlin,?,Germany) 的query,你顯然是要預(yù)測capitalOf,而不是childOf。
在CompGCN中,首先會為輸入的 KG 填充反關(guān)系(最近已普遍使用)和自循環(huán)關(guān)系(用來實現(xiàn)GCN的穩(wěn)定性)。CompGCN采用編碼-解碼方法,其中圖編碼器構(gòu)建節(jié)點和邊的表示形式,然后解碼器生成某些下游任務(wù)(如鏈接預(yù)測或節(jié)點分類)的分?jǐn)?shù)。
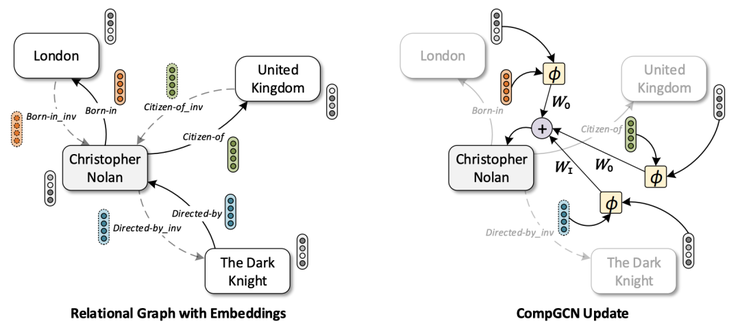
CompGCN intuition. Source: Vashishth et al
節(jié)點表示是通過聚集來自相鄰節(jié)點的消息而獲得的,這些消息對傳入和傳出的邊(圖中的Wi,Wo以及那些自循環(huán))進行計數(shù),其中交互函數(shù)對 (subject, predicate)進行建模。
作者嘗試了加法(TransE-style),乘法(DistMult-style)和圓相關(guān)(HolE-style)的交互。在匯總節(jié)點消息之后,邊的表示將通過線性層進行更新。你幾乎可以選擇任何你喜歡的解碼器,作者選擇的是 TransE,DistMult 和 ConvE 解碼器。CompGCN在鏈接預(yù)測和節(jié)點分類任務(wù)方面都比R-GCN要好,并且在性能上與其他SOTA模型相當(dāng)。性能最好的CompGCN是使用帶有ConvE解碼器的基于循環(huán)相關(guān)的編碼器。
11、Probability Calibration for Knowledge Graph Embedding Models
文章鏈接:https://openreview.net/pdf?id=S1g8K1BFwS
Last, but not least,Tabacoff和Costabello考慮了KGE模型的概率校準(zhǔn)。簡單來說,如果你的模型以90%的置信度預(yù)測某個事實是正確的,則意味著該模型必須在90%的時間里都是正確的。但是,通常情況并非如此,例如,在下圖中,表明TransE傾向于返回較小的概率(有點“悲觀”)。
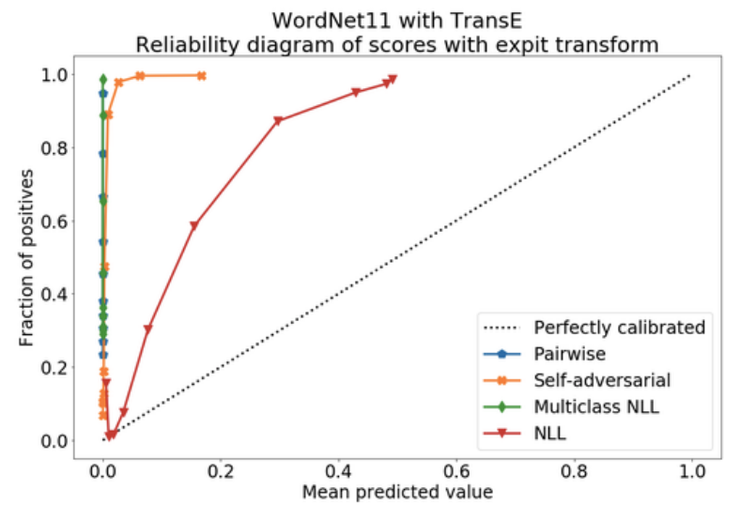
Source: Tabacoff and Costabello
作者采用Brier評分來測量校準(zhǔn),采用Platt縮放和等滲回歸來優(yōu)化校準(zhǔn)評分,并提出了在沒有給出“hard negatives”的典型鏈接預(yù)測方案中對負(fù)樣本進行采樣的策略。于是,你可以校準(zhǔn)KGE模型,并確保它會返回可靠的結(jié)果。這是一個非常好的分析,結(jié)果表明在一些工業(yè)任務(wù)上,你可以用KGE模型來提升你對自己算法/產(chǎn)品的信心。
四、用GNN做實體匹配
不同的知識圖譜都有他們自己的實體建模的模式,換句話說,不同的屬性集合可能只有部分重疊,甚至URLs完全不重疊。例如在Wikidata中Berlin的URL是https://www.wikidata.org/entity/Q64,而DBpedia中Berlin的URL是http://dbpedia.org/resource/Berlin。
如果你有一個由這些異質(zhì)URL組成的知識圖譜,盡管它們兩個都是在描述同一個真實的Berlin,但知識圖譜中卻會將它們視為各自獨自的實體;當(dāng)然你也可以編寫/查找自定義映射,以顯式的方式將這些URL進行匹配成對,例如開放域知識圖譜中經(jīng)常使用的owl:sameAs謂詞。維護大規(guī)模知識圖譜的映射問題是一個相當(dāng)繁瑣的任務(wù)。以前,基于本體的對齊工具主要依賴于這種映射來定義實體之間的相似性。但現(xiàn)在,我們有GNNs來自動學(xué)習(xí)這樣的映射,因此只需要一個小的訓(xùn)練集即可。
我們在「知識圖譜@AAAI2020」的文章中簡要討論了實體匹配的問題。而在ICLR 2020 中這方面的研究有了新的進展。
12、Deep Graph Matching Consensus
文章鏈接:https://openreview.net/pdf?id=HyeJf1HKvS
Fey 等人推出了DGMC框架(深度圖匹配共識,Deep Graph Matching Consensus),這個框架包括兩大階段:
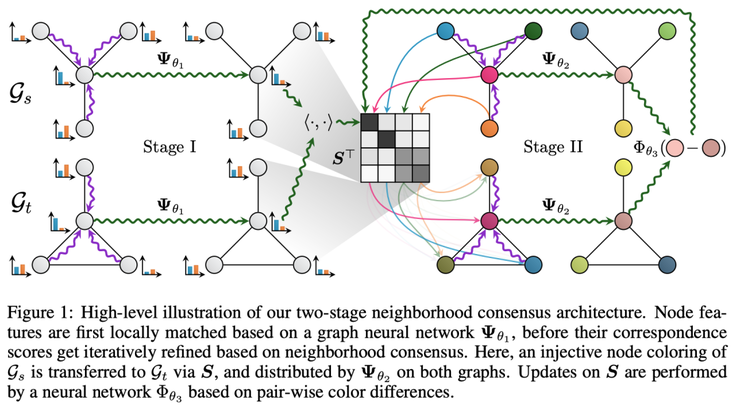
Deep Graph Matching Consensus intuition. Source: Fey et al
1)兩個圖,源圖(Gs)和目標(biāo)圖(Gt),通過相同的GNN(具有相同的參數(shù),表示為ψ_θ1)獲得初始節(jié)點嵌入。然后通過乘以節(jié)點嵌入,并應(yīng)用Sinkhorn歸一化來獲得軟對應(yīng)矩陣S(soft correspondences matrix S)。這里可以使用任何最適合任務(wù)的GNN編碼器。
2)隨后將消息傳遞(也可以看做是圖形著色)應(yīng)用到鄰域(標(biāo)注為ψ_θ2的網(wǎng)絡(luò)),最后計算出源節(jié)點和目標(biāo)節(jié)點之間的距離(ψ_θ3),這個距離表示鄰域共識。
作者對DGMC進行了廣泛的任務(wù)評估——匹配隨機圖、匹配目標(biāo)檢測任務(wù)的圖,以及匹配英、漢、日、法版的DBpedia。有意思的是,DGMC在刪除關(guān)系類型時,卻能產(chǎn)生很好的結(jié)果,這說明源KG和目標(biāo)KG之間基本上是單一關(guān)系。
于是引入這樣一條疑惑:如果在Hits@10我們已經(jīng)做到90+%了,真的還需要考慮所有屬性類型以及限制語義嗎?
13、Learning deep graph matching with channel-independent embedding and Hungarian attention
文章鏈接:https://openreview.net/pdf?id=rJgBd2NYPH
Yu 等人介紹了他們的深度匹配框架,這個框架具有兩個比較鮮明的特征:聚焦在聚合邊緣嵌入、引入一個新的匈牙利注意力(Hungarian attention)。匈牙利算法是解決分配問題的經(jīng)典方法,但它不是可微分的。
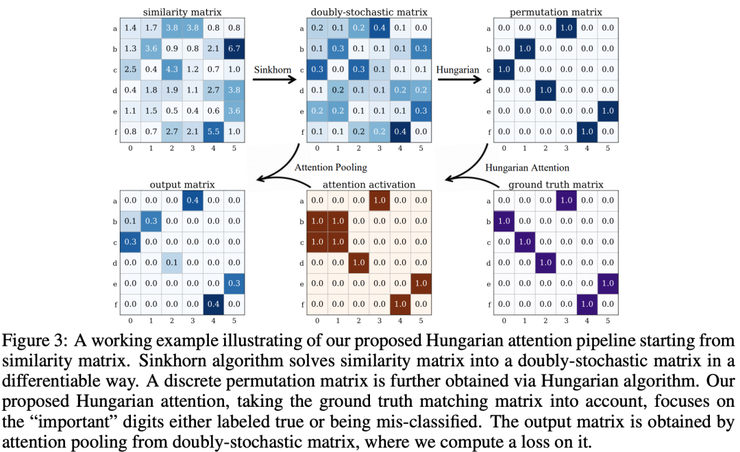
作者利用一個黑箱(帶有匈牙利注意力)的輸出來生成網(wǎng)絡(luò)結(jié)構(gòu),然后把這個流進一步地傳播。匈牙利注意力的方法,直觀來理解一下:
1)初始步驟類似于DGMC,一些圖編碼器生成節(jié)點和邊嵌入,且相似矩陣通過Sinkhorn規(guī)范化來傳遞;
2)不同的是,生成矩陣被返回到匈牙利黑箱(而不是像DGMC中那樣傳遞迭代消息),從而生成離散矩陣;
3)通過注意力機制與基準(zhǔn)進行比較,獲得激活圖,然后對其進行處理,從而獲得loss。
作者僅在CV基準(zhǔn)上進行了評估,但由于匈牙利算法的時間復(fù)雜度是O(n³),所以如果能把runtime 也放出來,可能會更有趣。
五、角色扮演游戲中的知識圖譜
互動小說游戲(Interactive Fiction games,例如RPG Zork文字游戲)非常有趣,尤其是你探索完世界,然后輸入一段話,等待游戲反饋的時候。
14、Graph Constrained Reinforcement Learning for Natural Language Action Spaces
文章鏈接:https://openreview.net/pdf?id=B1x6w0EtwH
Ammanabrolu 和 Hausknecht 提出了一項有關(guān) IF 游戲中強化學(xué)習(xí)的新工作。這個工作中使用了 知識圖譜來建模狀態(tài)空間和用戶交互。
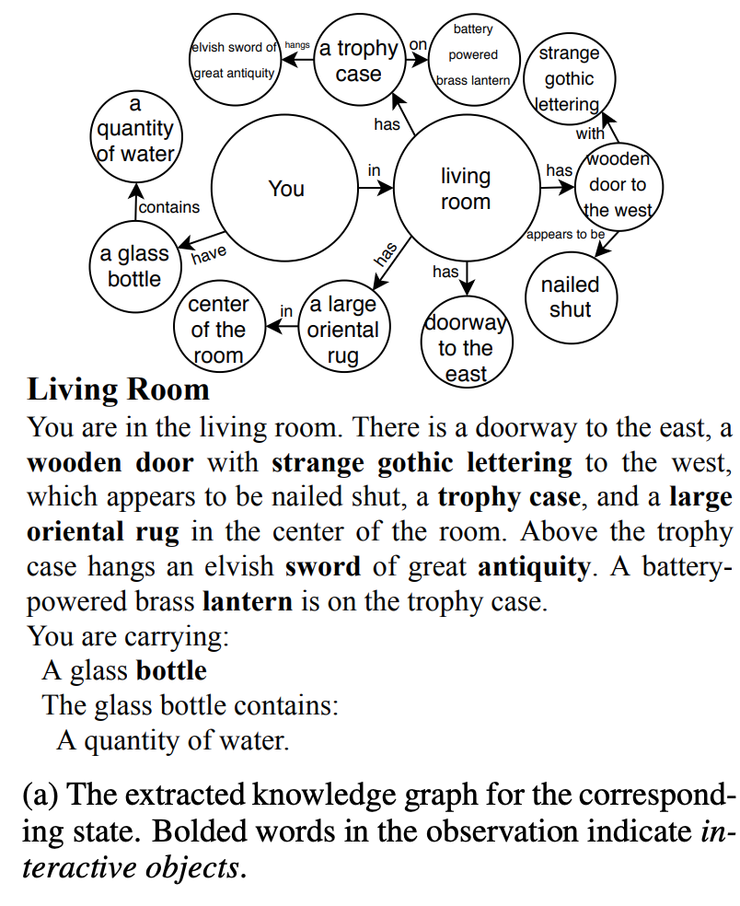
Source: Ammanabrolu and Hausknecht
例如,詞匯表中有數(shù)十個模板和數(shù)百個單詞。嘗試所有可能的排列是不可行的。但當(dāng)你維護一個可見實體的知識圖譜時,agent的可選項就會大幅度減少,于是便可以更快地推進游戲。
在他們提出的編碼-解碼模型 KG-A2C(Knowledge Graph Advantage Actor Critic)中,編碼器采用GRU進行文本輸入,并使用圖注意力網(wǎng)絡(luò)構(gòu)建圖嵌入。此外,在解碼器階段使用可見對象的圖遮掩(graph mask)。在基準(zhǔn)測試中,KG-A2C可以玩28個游戲!
Soon they will play computer games better than us meatbags.
很快,電子游戲上,他們將比我們這些菜包子們打的更好了。
6、Conclusion
目前我們看到,知識圖譜已經(jīng)越來越多地應(yīng)用到 AI的各個領(lǐng)域,特別是NLP領(lǐng)域。
ICML 和ACL 隨后也將到來,屆時我們再見。


























