這項研究受神經架構搜索(NAS)的啟發,提出將 Interstellar 作為一種處理關系路徑中信息的循環架構。此外,該研究中的新型混合搜索算法突破了 stand-alone 和 one-shot 搜索方法的局限,并且有希望應用于其他具有復雜搜索空間的領域。
視頻鏈接:https://v.qq.com/x/page/n3207ugke4j.html?start=6
知識圖譜嵌入(Knowledge Graph Embedding)目前在學習知識圖譜(KG)中的知識表達上具有很強的能力。在以往的研究中,很多工作主要針對單個三元組(triplet)建模,然而對 KG 而言,三元組間的長鏈依賴信息在一些任務上也很重要。
在第四范式、香港科技大學這篇被 NeurIPS 2020 會議接收的論文中,研究者基于由三元組組成的關系路徑(relational path)提出 Interstellar 模型,通過搜索一種遞歸神經網絡,來處理關系路徑中的短鏈、長鏈信息。

論文鏈接:https://arxiv.org/pdf/1911.07132.pdf
代碼鏈接:https://github.com/AutoML-4Paradigm/Interstellar
首先,該研究通過一組模擬實驗分析了用單一模型對不同任務中關系路徑建模的難度,并由此提出通過搜索的方式對不同任務針對性地建模。為了提高搜索效率,該研究提出了一種混合搜索算法(hybrid-search algorithm),在鏈接預測(link prediction)和結點匹配(entity alignment)任務上,能高效地搜索到具有更好效果的模型。
背景介紹
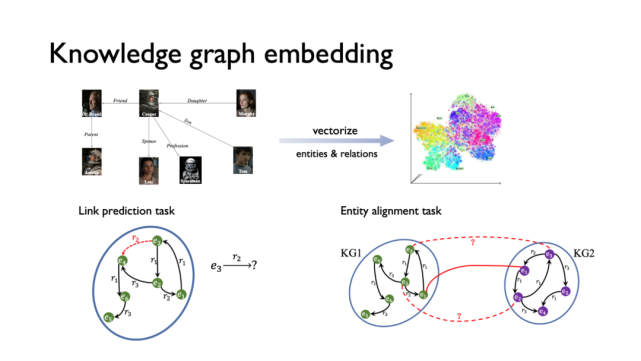
知識圖譜嵌入(KG Embedding)旨在把圖譜中的結點(entities)和關系(relations)映射到一個低維空間,同時保留圖中的重要性質。在目前學術領域,一些工作基于單個三元組(s,r,o)建模,如 TransE、RESCAL、DistMult、RotatE、ConvE、SimplE 等,它們在鏈接預測任務(即給定頭結點 s 和關系 r ,預測尾結點 o )上表現良好,而在結點匹配任務(即給定兩個 KG,預測哪些結點有相同含義)上性能一般。另一類基于關系路徑的工作,如 IPTransE、Chains、RSN 等則在結點匹配任務上表現更好。
研究人員觀察到,關系路徑包含多種重要信息,如單個三元組的短鏈信息、多個關系的復合、多個三元組之間的長鏈信息等等。基于此,該研究提出 Interstellar 模型,通過搜索的方式來根據不同任務,有針對性地對關系路徑進行建模。
動機
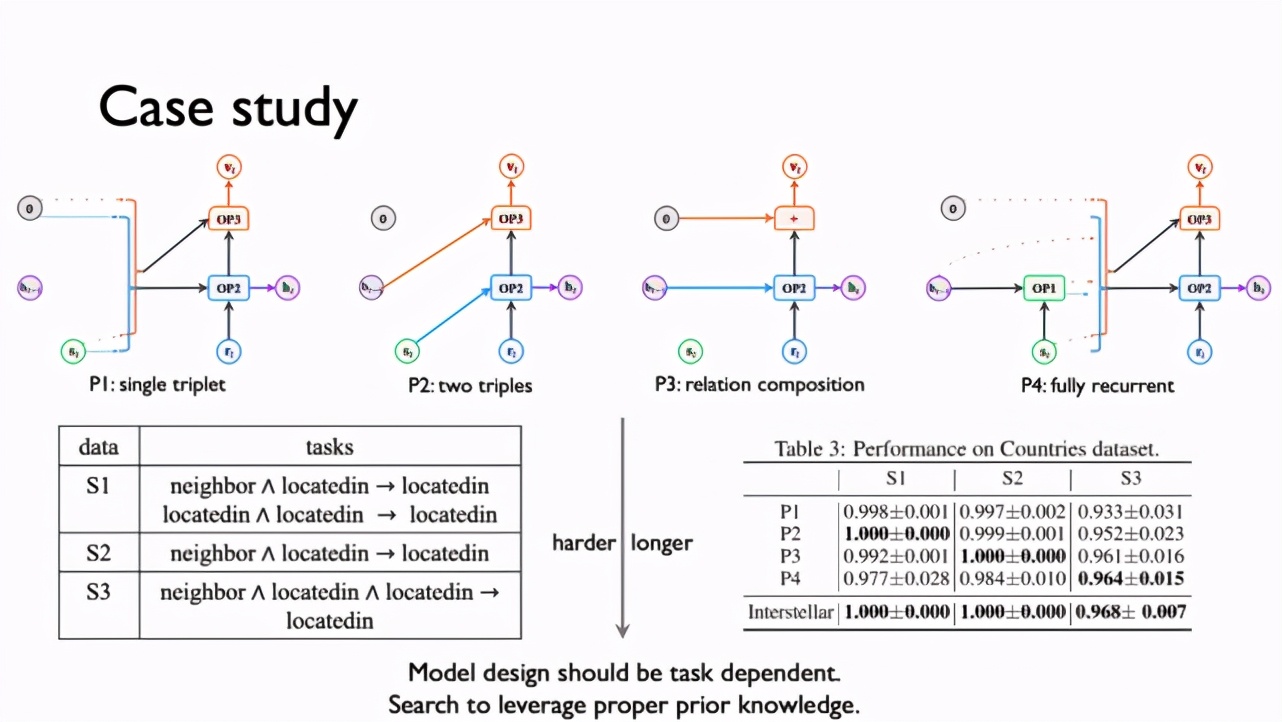
為了驗證不同模型對不同任務的擬合能力不同,研究人員設計了一組模擬實驗。Countries 數據集有 S1-S3 三個不同任務,預測難度逐一增大,需要模擬的預測路徑逐漸變長。為此研究者基于先驗知識(prior knowledge)設計了 4 類模式 P1-P4,分別用于建模單個三元組、連續的兩個三元組、多重關系的復合,以及全遞歸連接。直觀上看,P4 的建模能力更強,但在有限的樣本上,樣本復雜度同樣重要,選擇更能擬合數據規律的模型能夠獲得更好的效果。
如下表所示,在 S1 這個簡單任務上,基于單個或兩個三元組的模型 P1 和 P2 表現更好,在 S2 上 P1-P3 均優于 P4,而在 S3 上,遞歸模型 P4 由于能模擬更長路徑而勝出。由此我們可以得出,關系路徑上的建模應該是模型相關的,如果我們能夠通過搜索的方式把專家的先驗知識融入到建模能力中,那么針對不同任務,模型就可以自動地找到更優解。
問題定義與搜索空間
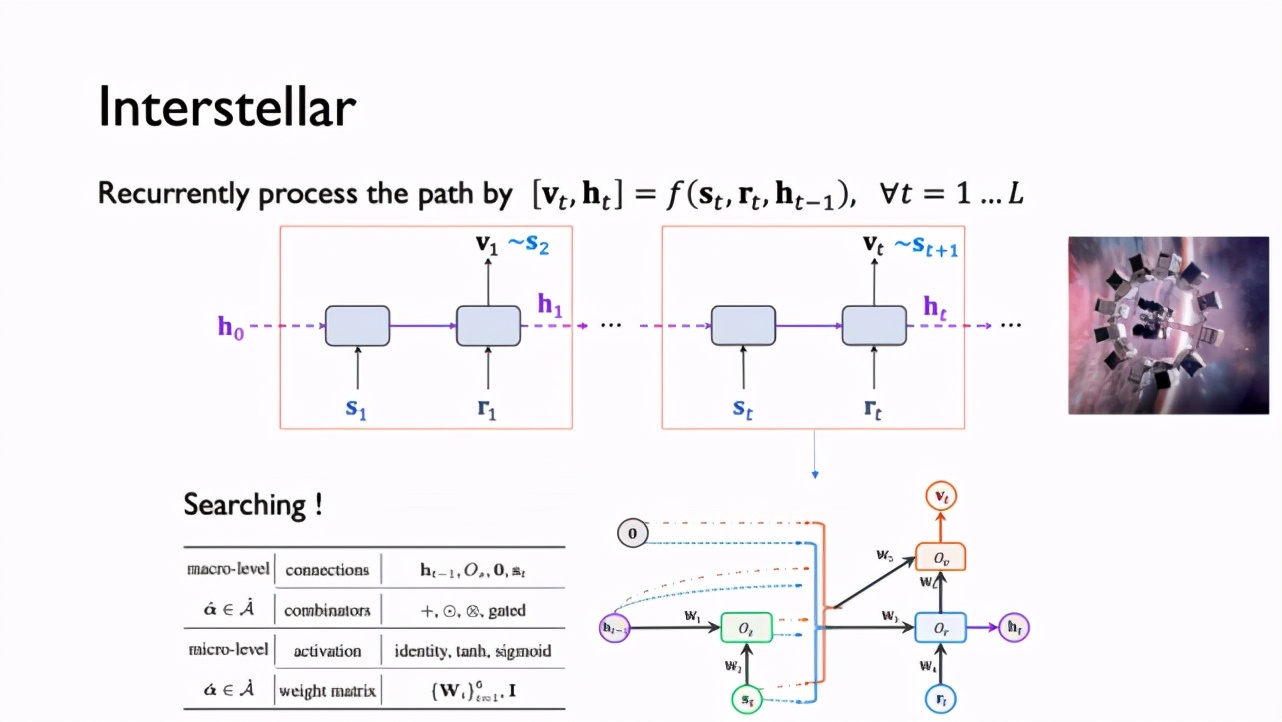
首先,研究者將 Interstellar 定義為一個遞歸式地處理關系路徑的模型,在每一個遞歸步中,模型關注到一個三元組,信息在三元組之內、之間以不同方式穿梭。與傳統 RNN 不同,這里的每一步有兩個輸入,同時由于需要考慮知識圖譜相關的領域知識,單純地使用 RNN 對其建模是不合適的。為了利用好知識圖譜領域的先驗知識,同時使模型可以適用于不同任務,受神經網絡搜索技術(Neural Architecture Search)的啟發,該研究把建模問題定義為搜索問題,來自適應地對不同任務建模。
通過對知識圖譜嵌入領域相關模型的總結,該研究提出上圖的搜索空間,利用運算單元 O_s 來處理結點嵌入 s_t ,用 O_r 來處理關系嵌入 r_t ,用 O_v 來輸出向量 v_t 從而預測下一個結點 s_t+1 。具體而言,該研究在 macro-level 搜索不同單元間的連接方式(connections)和復合方式(combinators),在 micro-level 搜索激活函數(activation)與權重矩陣(weight matrix)。
搜索算法
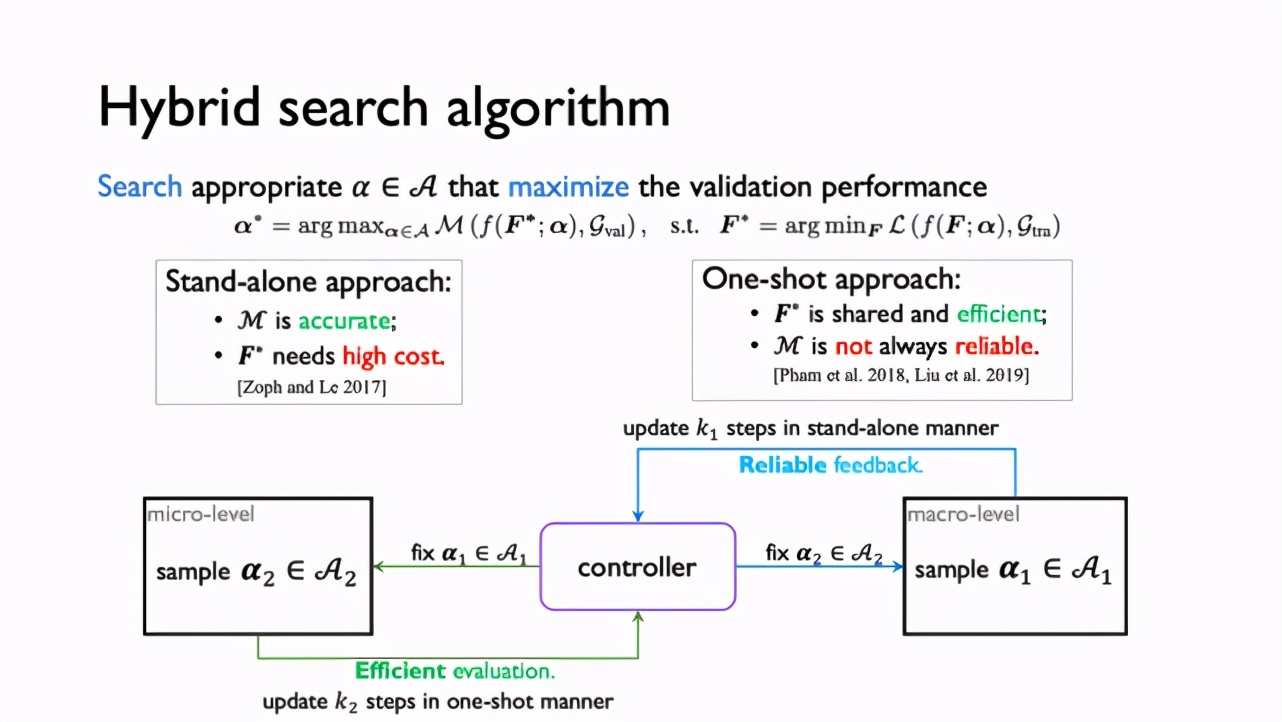
該研究的目標是更快地在搜索空間中找到能在驗證集上達到更好性能的模型,這可以通過 bi-level 優化方式來定義。為了求解這個優化問題,學術界目前有兩類方法。一類是 stand-alone 算法,對每個模型單獨訓練參數 F 至收斂,這樣可以得到準確的性能評估 Μ ,但訓練代價較高;另一類是 one-shot 算法,建立一個包含所有網絡的超網絡(supernet),不同模型在超網絡中采樣,同時可以參數共享,這樣的評估方式更高效,但不總能保證可靠性。研究人員觀察到在 Interstellar 的建模上,one-shot 方式并不可靠。
為了解決這些問題,該研究提出 Hybrid 搜索算法,在 macro-level 采用 stand-alone 方式,給定 α_2 ,從 Α_1 中采樣不同的 α_1 ,訓練模型參數至收斂,拿到對 α_1 的可靠評估;在 micro-level 采用 one-shot 方式,給定 α_1 ,從 Α_2 中采樣不同的 α_2 ,同時讓不同 α_2 對應的模型在超網絡中共享參數,加速訓練評估的過程。二者結合,即保證了搜索準確性,又保證了搜索效率。
實驗結果
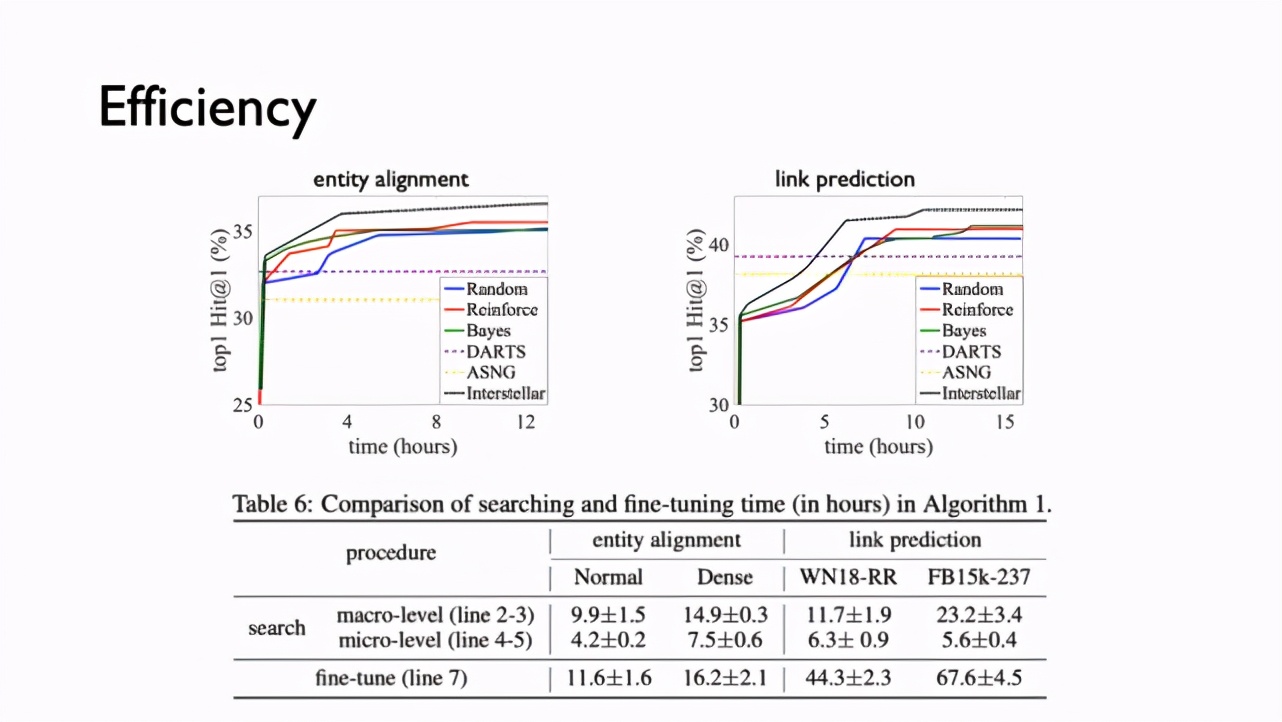
在搜索效果上,該方法在結點匹配和鏈接預測任務中,都能針對不同數據任務搜索到更好的模型,這得益于 Interstellar 上合理的搜索空間和高效的搜索算法。

在搜索效率上,Hybrid 算法能夠比隨機搜索(Random)、強化學習(Reinforce)、貝葉斯優化(Bayes)算法更快地得到更好的模型,同時下圖中的兩條虛線(表示單獨的 one-shot 算法)表明其在這個問題上性能并不好。在搜索時間上,Hybrid 算法和調參(如 learning rate、batch size 等參數)時間是相當的,說明這個搜索方法代價并不高。在新的問題中,先搜索模型再進行調參是一個不錯的選擇。