













我們如何做到不停機將ZooKeeper遷移到Kubernetes
最近,我們在不停機的情況下將數百個 ZooKeeper 實例遷移到了 Kubernetes。我們利用了強大的 Kubernetes 特性(例如端點)簡化了遷移過程,那些想要跟我們一樣進行 Zookeeper 遷移的人可以在這篇文章里找到答案。文章的末尾列出了進行遷移所需的網絡條件。
1. 傳統的 ZooKeeper 遷移方法
ZooKeeper 是很多分布式系統的基礎,它為這些系統提供了一個強大的平臺,讓它們可以聚在一起形成集群。它提供了一種比較基礎的方法來形成集群:每個服務器實例都有一個配置文件,文件里列出了集群成員的主機名和數字 ID,所有的服務器都有相同的集群成員列表,如下所示:
- server.1=host1:2888:3888
- server.2=host2:2888:3888
- server.3=host3:2888:3888
每臺服務器都有一個叫作 myid 的文件,用來指明它在列表中對應的是哪個數字 ID。
集群可以隨意添加和移除服務器,只要沒有違反這個關鍵規則:每臺服務器必須能夠與配置文件中列出的仲裁服務器通信。傳統的 ZooKeeper 服務器遷移步驟主要包括:
- 啟動一臺新主機,在服務器列表配置中加入“server.4=host:4…”;
- 更新已有主機上的配置文件,添加新的服務器條目,或刪除已退役的主機;
- 滾動重啟舊主機(3.4x 版本分支不提供動態服務器配置功能);
- 更新客戶端的連接串。
這種方法的缺點是需要修改大量的配置文件并進行滾動重啟,這種方式可能無法進行可靠的自動化。在將 ZooKeeper 遷移到 Kubernetes 之前,我們也考慮過這種方法,但后來找到了一種更簡單的方法。這種方法更為安全,因為根據我們的經驗,每一次新的首領選舉都存在一個小風險,就是有可能會讓依賴它們的系統崩潰。
2. 新的遷移方法
我們將已有的 ZooKeeper 服務器包裝成 Kubernetes 服務,然后使用相同的 ZooKeeper ID 進行從服務器到 Pod 的一對一替換。這只需要一次滾動重啟就可以重新配置現有的 ZooKeeper 實例,然后逐一關閉服務器。不過,我們不打算深入討論如何為 ZooKeeper 配置 Kubernetes 拓撲,也不打算深入討論底層的狀態就緒檢查機制,因為有很多方法可以實現這些操作。
我們將分五個步驟進行遷移:
- 確保為 ZooKeeper 集群的遷移做好準備;
- 在 Kubernetes 中創建 ClusterIP 服務,將 Zookeeper 包裝成服務;
- 修改 ZooKeeper 客戶端,讓它們連接到 ClusterIP 服務;
- 配置 ZooKeeper 服務器實例,讓它們可以基于 ClusterIP 服務地址執行點對點事務;
- 通過 Kubernetes Pod 運行 ZooKeeper 實例。
對于下面的每一個步驟,我們都將提供一個基礎設施拓撲關系圖。為了便于理解,這些圖只包含兩個 ZooKeeper 實例(在現實當中一般不會創建少于三個節點的集群)。
準備好先決條件
我們從一個可運行的 ZooKeeper 集群開始,確保主機上的服務能夠與 Kubernetes 集群通信。文末介紹了幾種方法。
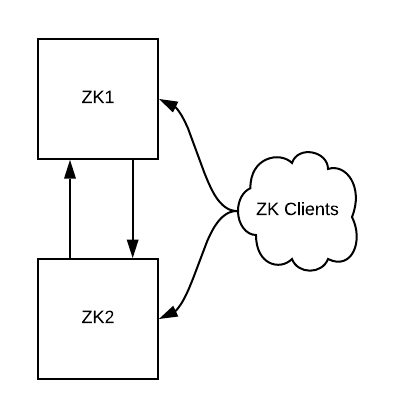
圖 1:初始狀態,一個包含兩個實例的 ZooKeeper 集群和一些客戶端
創建 ClusterIP 服務
為每個 ZooKeeper 服務器創建一個具有匹配端點的 ClusterIP 服務,可以讓客戶端端口(2181)和集群內部端口(2888、3888)通過。完成之后,就可以通過這些服務主機名連接到 ZooKeeper 集群。Kubernetes ClusterIP 服務在這個時候很有用,因為它們提供了可以作為后端 Pod 負載均衡器的靜態 IP 地址。我們用它們進行從服務到 Pod 的一對一映射,相當于為每個 Pod 提供了一個靜態的 IP 地址。
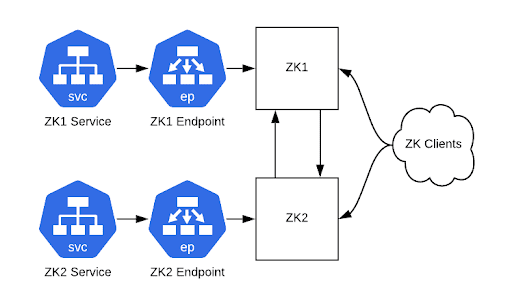
圖 2:可以通過 ClusterIP 服務訪問我們的集群(ZooKeeper 仍然運行在物理硬件上)
重新配置客戶端
在可以通過 Kubernetes ClusterIP 服務連接到 ZooKeeper 集群之后,接下來就可以重新配置客戶端了。如果你在 ZooKeeper 連接串中使用了 CNAME 記錄,那么請修改 DNS 記錄。如果客戶端在連接失敗時不會重新解析 DNS 條目,那么就重新啟動客戶端。如果沒有使用 CNAME 記錄,那么就需要使用新的連接串,并重新啟動客戶端。在這個時候,新舊連接串都可以使用。
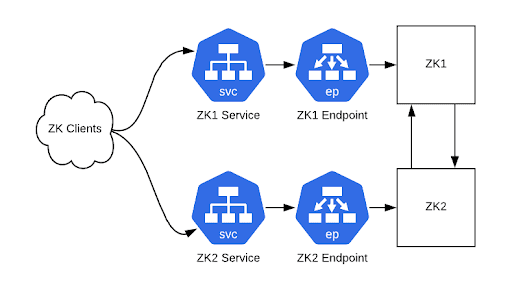
圖 3:客戶端現在通過 ClusterIP 服務實例與 ZooKeeper 集群通信
重新配置 ZooKeeper 實例
接下來,我們將讓 ZooKeeper 服務器通過 ClusterIP 服務進行點對點通信。為此,我們將結合 ClusterIP 服務的地址來修改配置文件。這里還需要配置 zk_quorum_listen_all_ips 標志,如果沒有這個,ZooKeeper 實例將無法成功綁定到主機接口上不存在的 IP 地址,因為它是一個 Kube 服務 IP。
- server.1=zk1-kube-svc-0:2888:3888
- server.2=zk2-kube-svc-1:2888:3888
- server.3=zk3-kube-svc-2:2888:3888
- zk_quorum_listen_all_ips: true
server.1=zk1-kube-svc-0:2888:3888server.2=zk2-kube-svc-1:2888:3888server.3=zk3-kube-svc-2:2888:3888zk_quorum_listen_all_ips: true
滾動重新啟動這些主機,后面就可以開始準備用 Pod 替換主機了。
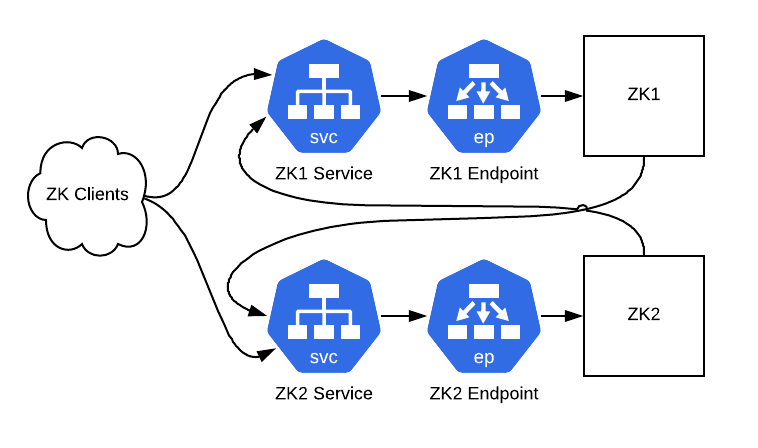
圖 4:ZooKeeper 實例現在通過 ClusterIP 服務與其他實例通信
使用 Pod 替代 ZooKeeper 主機
我們將進行以下這些步驟,每次操作一臺服務器:
- 選擇一臺 ZooKeeper 服務器及其相應的 ClusterIP 服務;
- 關閉服務器上的 ZooKeeper 進程;
- 使用與被關閉的 ZooKeeper 具有相同服務器列表配置和 myid 文件的 Pod;
- 等待,直到 Pod 中的 ZooKeeper 啟動,并與其他 ZooKeeper 節點的數據同步。
就這樣,ZooKeeper 集群現在運行在 Kubernetes 中,并帶有之前所有的數據。
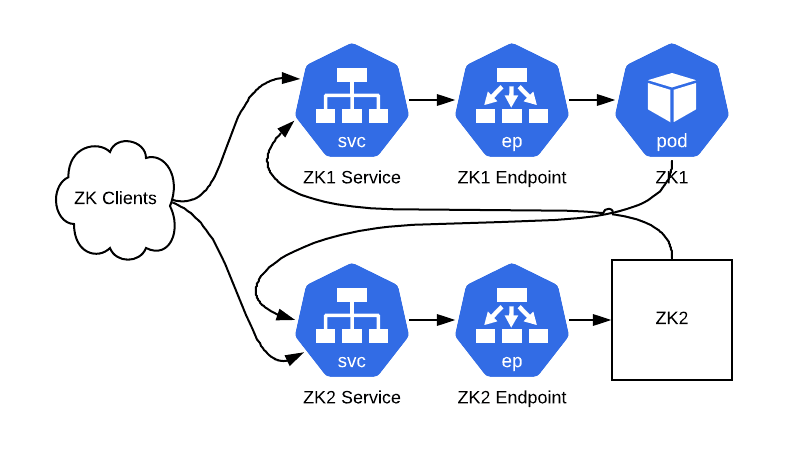
圖 5:經過替換后的集群。ZK1 運行在一個 Pod 中,而 ZK2 不需要知道發生了什么
網絡先決條件
要順利完成這些步驟,需要確保一些網絡設置符合條件。你需要確保:
- 可以從所有需要連接到 ZooKeeper 的服務器重新路由 Kubernetes Pod 的 IP 地址;
- 所有連接到 ZooKeeper 的服務器必須能夠解析 Kubernetes 服務主機名;
- 所有需要連接到 ZooKeeper 的服務器必須運行 kube-proxy,讓它們能夠訪問 ClusterIP 服務。
這些可以通過幾種方式來實現。我們使用了一個內部網絡插件,類似于 Lyft 的插件:
https://github.com/aws/amazon-vpc-cni-k8s
或者 AWS 插件:
https://github.com/lyft/cni-ipvlan-vpc-k8s
可以直接將 AWS VPC IP 地址分配給 Pod,而不是使用虛擬疊加網絡,所以可以從任意實例重新路由 Pod 的 IP。疊加網絡(如 flannel)也是可以的,只要所有的服務器都可以連接到疊加網絡。


















