大數據時代,且看新一代計算引擎Spark和Flink成王敗寇
前言
做大數據絕對躲不過的一個熱門話題就是實時流計算,而提到實時流計算,就不得不提 Spark 和 Flink。Spark 從 2014 年左右開始迅速流行,剛推出時除了在某些場景比 Hadoop MapReduce 帶來幾十到上百倍的性能提升外,還提出了用一個統一的引擎支持批處理、流處理、交互式查詢、機器學習等常見的數據處理場景。憑借高性能和全面的場景支持,Spark 早已成為眾多大數據開發者的最愛。
正在 Spark 如日中天高速發展的時候,2016 年左右 Flink 開始進入大眾的視野并逐漸廣為人知。由于Spark在數據流的實時處理中較弱,而Flink 憑借更優的流處理引擎,同時也支持各種處理場景,成為 Spark 的有力挑戰者。
本文對 Spark 和 Flink 進行了全面分析與對比,且看下一代大數據計算引擎之爭,誰主沉浮?
Spark簡介
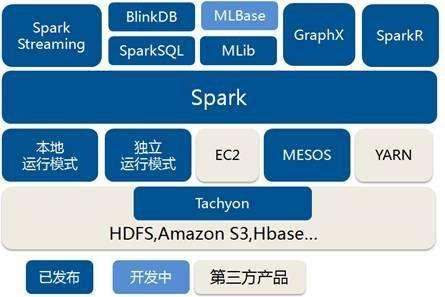
Spark是基于內存的計算框架,計算速度非常快。如果想要對接外部的數據,比如HDFS讀取數據,需要事先搭建一個Hadoop 集群。Apache Spark是一個開源集群運算框架,相對于Hadoop的MapReduce會在運行完工作后將中介數據存放到磁盤中,Spark使用了存儲器內運算技術,能在數據尚未寫入硬盤時即在存儲器內分析運算。
Flink簡介
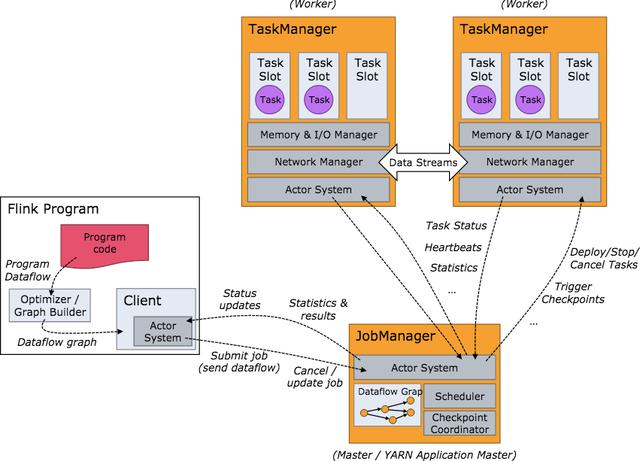
Flink 是一個針對流數據和批數據的分布式處理引擎。它主要是由 Java 代碼實現。目前主要還是依靠開源社區的貢獻而發展。對 Flink 而言,其所要處理的主要場景就是流數據,批數據只是流數據的一個極限特例而已。再換句話說,Flink 會把所有任務當成流來處理,這也是其最大的特點。Flink 可以支持本地的快速迭代,以及一些環形的迭代任務。
Flink 和 Spark 對比
Spark和Flink都支持批處理和流處理,接下來讓我們對這兩種流行的數據處理框架在各方面進行對比。首先,這兩個數據處理框架有很多相同點。
- 都基于內存計算;
- 都有統一的批處理和流處理APl,都支持類似SQL的編程接口;
- 都支持很多相同的轉換操作,編程都是用類似于Scala Collection APl的函數式編程模式;
- 都有完善的錯誤恢復機制;
- 都支持Exactly once的語義一致性。
當然,它們的不同點也是相當明顯,我們可以從4個不同的角度來看。
- 從流處理的角度來講,Spark基于微批量處理,把流數據看成是一個個小的批處理數據塊分別處理,所以延遲性只能做到秒級。而Flink基于每個事件處理,每當有新的數據輸入都會立刻處理,是真正的流式計算,支持毫秒級計算。由于相同的原因,Spark只支持基于時間的窗口操作(處理時間或者事件時間),而Flink支持的窗口操作則非常靈活,不僅支持時間窗口,還支持基于數據本身的窗口,開發者可以自由定義想要的窗口操作。
- 從SQL 功能的角度來講,Spark和Flink分別提供SparkSQL和Table APl提供SQL交互支持。兩者相比較,Spark對SQL支持更好,相應的優化、擴展和性能更好,而Flink在SQL支持方面還有很大提升空間。
- 從迭代計算的角度來講,Spark對機器學習的支持很好,因為可以在內存中緩存中間計算結果來加速機器學習算法的運行。但是大部分機器學習算法其實是一個有環的數據流,在Spark中,卻是用無環圖來表示。而Flink支持在運行時間中的有環數據流,從而可以更有效的對機器學習算法進行運算。
- 從相應的生態系統角度來講,Spark 的社區無疑更加活躍。Spark可以說有著Apache旗下最多的開源貢獻者,而且有很多不同的庫來用在不同場景。而Flink由于較新,現階段的開源社區不如Spark活躍,各種庫的功能也不如Spark全面。但是Flink還在不斷發展,各種功能也在逐漸完善。
如何選擇Spark和Flink
對于以下場景,你可以選擇 Spark。
- 數據量非常大而且邏輯復雜的批數據處理,并且對計算效率有較高要求(比如用大數據分析來構建推薦系統進行個性化推薦、廣告定點投放等);
- 基于歷史數據的交互式查詢,要求響應較快;
- 基于實時數據流的數據處理,延遲性要求在在數百毫秒到數秒之間。
結語
任何技術都不是孤立發展的,大數據技術更是如此。放眼未來,無論是Spark還是Flink,兩者的發展重點都將是數據科學和平臺API化,使其生態系統越來越完善。亦或許,會有更新的大數據處理引擎出現,誰知道呢。