













機器學習必備:TensorFlow的11個使用技巧整理
TensorFlow2.x在構建模型和總體使用方面提供了很多便利。那么,在tf中有什么新功能?
- 使用Keras輕松進行模型構建;
- 在任何平臺上的生產中都可以進行穩健的模型部署;
- 強大的研究實驗;
- 通過清理不推薦使用的API來簡化各個步驟
在本文中,我們將探索TF 2.0的10個功能,這些功能讓TensorFlow的使用更加順暢,減少了代碼行并提高了效率,因為這些函數/類屬于TensorFlow API。
1.用于構建輸入管道的tf.data API
tf.data API提供了用于數據管道和相關操作的功能。 我們可以構建管道,映射預處理功能,洗牌或批量處理數據集等等。
利用張量構建管道
- >>> dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
- >>> iter(dataset).next().numpy()
- 8
洗牌和批量處理數據集
- # Shuffle
- >>> dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1]).shuffle(6)
- >>> iter(dataset).next().numpy()
- 0
- # Batch
- >>> dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1]).batch(2)
- >>> iter(dataset).next().numpy()
- array([8, 3], dtype=int32)
- # Shuffle and Batch
- >>> dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1]).shuffle(6).batch(2)
- >>> iter(dataset).next().numpy()
- array([3, 0], dtype=int32)
壓縮兩個數據集
- >>> dataset0 = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
- >>> dataset1 = tf.data.Dataset.from_tensor_slices([1, 2, 3, 4, 5, 6])
- >>> dataset = tf.data.Dataset.zip((dataset0, dataset1))
- >>> iter(dataset).next()
- (<tf.Tensor: shape=(), dtype=int32, numpy=8>, <tf.Tensor: shape=(), dtype=int32, numpy=1>)
映射外部函數
- def into_2(num):
- return num * 2
- >>> dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1]).map(into_2)
- >>> iter(dataset).next().numpy()
- 16
2.圖像數據生成器
這是tensorflow.keras API的最佳特性之一(在我看來)。圖像數據生成器能夠在批處理和預處理過程中生成數據集切片,并實時進行數據擴充。
生成器允許直接從目錄或數據幀進行數據流。
對圖像數據生成器中的數據擴充的一個誤解是,它向現有的數據集中添加了更多的數據。雖然這是數據增強的實際定義,但在圖像數據生成器中,數據集中的圖像在訓練過程中會在不同的步驟進行動態轉換,這樣模型就可以在沒有看到的噪聲數據上進行訓練。
- train_datagen = ImageDataGenerator(
- rescale=1./255,
- shear_range=0.2,
- zoom_range=0.2,
- horizontal_flip=True
- )
在這里,對所有樣本進行重新縮放(用于規格化),而其他參數則用于擴充。
- train_generator = train_datagen.flow_from_directory(
- 'data/train',
- target_size=(150, 150),
- batch_size=32,
- class_mode='binary'
- )
我們為實時數據流指定目錄,這也可以使用數據幀來完成。
- train_generator = flow_from_dataframe(
- dataframe,
- x_col='filename',
- y_col='class',
- class_mode='categorical',
- batch_size=32
- )
x_col參數定義圖像的完整路徑,而y_col參數定義用于分類的標簽列。
該模型可直接與生成器供電。盡管需要指定steps_per_epoch參數,實際上是采樣數/批量大小。
- model.fit(
- train_generator,
- validation_data=val_generator,
- epochs=EPOCHS,
- steps_per_epoch=(num_samples // batch_size),
- validation_steps=(num_val_samples // batch_size)
- )
3.使用tf.image進行數據擴充
數據擴充是必要的, 在數據不足的情況下,對數據進行更改并將其視為單獨的數據點是在較少數據下進行訓練的一種非常有效的方法。
tf.image API具有用于轉換圖像的工具,以后可以通過前面討論的tf.data API將其用于數據增強。
- flipped = tf.image.flip_left_right(image)
- visualise(image, flipped)

以上代碼的輸出結果
- saturated = tf.image.adjust_saturation(image, 5)
- visualise(image, saturated)

以上代碼的輸出結果
- rotated = tf.image.rot90(image)
- visualise(image, rotated)

以上代碼的輸出結果
- cropped = tf.image.central_crop(image, central_fraction=0.5)
- visualise(image, cropped)

以上代碼的輸出結果
4.TensorFlow數據集
- pip install tensorflow-datasets
- pip install tensorflow-datasets
這是一個非常有用的庫,因為它是轉儲來自Tensorflow收集的來自各個域的非常知名的數據集的唯一起點。
- import tensorflow_datasets as tfds
- mnist_data = tfds.load("mnist")
- mnist_train, mnist_test = mnist_data["train"], mnist_data["test"]
- assert isinstance(mnist_train, tf.data.Dataset)
tensorflow數據集可在下方鏈接中找到:
https://www.tensorflow.org/datasets/catalog/overview
音頻,圖像,圖像分類,對象檢測,結構化,摘要,文本,翻譯,視頻是tfds提供的類型。
5.基于預訓練模型的遷移學習
遷移學習是機器學習中的一個新熱點。如果一個基準模型已經被其他人訓練過,那對于我們來說這個模型就不再適用,也不切實際。遷移學習解決了這個問題,預先訓練的模型可以為給定的用例重新使用,也可以為不同的用例進行擴展。
TensorFlow提供了基準的預訓練模型,可以很容易地擴展到所需的用例。
- base_model = tf.keras.applications.MobileNetV2(
- input_shape=IMG_SHAPE,
- include_top=False,
- weights='imagenet'
- )
這個base_model可以輕松地通過附加層或不同模型進行擴展, 例如:
- model = tf.keras.Sequential([
- base_model,
- global_average_layer,
- prediction_layer
- ])
6.估算器
估算器是TensorFlow完整模型的高級表示,其設計目的是易于縮放和異步訓練--TensorFlow文檔
估算器是TensorFlow完整模型的高級表示,其設計目的是易于縮放和異步訓練--TensorFlow文檔
預制的估算器提供了非常高級的模型抽象,因此你可以直接專注于訓練模型,而不必擔心較低級別的復雜性。 例如:
- linear_est = tf.estimator.LinearClassifier(
- feature_columns=feature_columns
- )
- linear_est.train(train_input_fn)
- result = linear_est.evaluate(eval_input_fn)
這表明使用tf.estimator構建和訓練估算器非常容易, 估算器也可以自定義。
TensorFlow有許多預制的估算器,包括LinearRegressor,BoostedTreesClassifier等。可以去Tensorflow文檔了解完整內容。
7.自定義層
對于許多層深層網絡而言,神經網絡是眾所周知的,其中層可以是不同類型的。 TensorFlow包含許多預定義的層(例如Dense,LSTM等)。 但是對于更復雜的體系結構,層的邏輯要比主層復雜得多。 對于此類實例,TensorFlow允許構建自定義層。 這可以通過對tf.keras.layers.Layer類進行子類化來完成。
- class CustomDense(tf.keras.layers.Layer):
- def __init__(self, num_outputs):
- super(CustomDense, self).__init__()
- self.num_outputs = num_outputs
- def build(self, input_shape):
- self.kernel = self.add_weight(
- "kernel",
- shape=[int(input_shape[-1]),
- self.num_outputs]
- )
- def call(self, input):
- return tf.matmul(input, self.kernel)
如文檔中所述,實現自己的層的最佳方法是擴展tf.keras.Layer類并實現:
- __init__,您可以在其中進行所有與輸入無關的初始化。
- 構建,您可以在其中知道輸入張量的形狀,并可以進行其余的初始化。
- 調用,您可以在其中進行前向計算。
盡管可以在__init__本身中完成內核初始化,但最好在build中進行初始化,否則,你將必須在新圖層創建的每個實例上顯示指定input_shape。
8.定制化訓練
tf.keras序列和模型API使訓練模型更容易。 但是,大多數時候在訓練復雜模型時會使用自定義損失函數。 此外,模型訓練也可以與默認訓練不同(例如,將梯度分別應用于不同的模型組件)。
TensorFlow的自動微分有助于以有效的方式計算梯度,這些原語用于定義自定義訓練循環。
- def train(model, inputs, outputs, learning_rate):
- with tf.GradientTape() as t:
- # Computing Losses from Model Prediction
- current_loss = loss(outputs, model(inputs))
- # Gradients for Trainable Variables with Obtained Losses
- dW, db = t.gradient(current_loss, [model.W, model.b])
- # Applying Gradients to Weights
- model.W.assign_sub(learning_rate * dW)
- model.b.assign_sub(learning_rate * db)
可以針對多個時期重復此循環,并根據用例使用更自定義的設置。
9.檢查點
保存TensorFlow模型可以有兩種類型:
- SavedModel:保存模型的完整狀態以及所有參數。 這與源代碼無關。
- model.save_weights('checkpoint')
- 檢查點
檢查點捕獲模型使用的所有參數的精確值。 使用Sequential API或Model API構建的模型可以簡單地以SavedModel格式保存。
但是,對于自定義模型,需要檢查點。
檢查點不包含對模型定義的計算的任何描述,因此通常僅在將使用保存的參數值的源代碼可用時才有用。
保存檢查點
- checkpoint_path = “save_path”
- # Defining a Checkpoint
- ckpt = tf.train.Checkpoint(model=model, optimizer=optimizer)
- # Creating a CheckpointManager Object
- ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
- # Saving a Model
- ckpt_manager.save()
從檢查點加載
TensorFlow通過遍歷具有命名邊的有向圖,從加載的對象開始,將變量與檢查點值匹配。
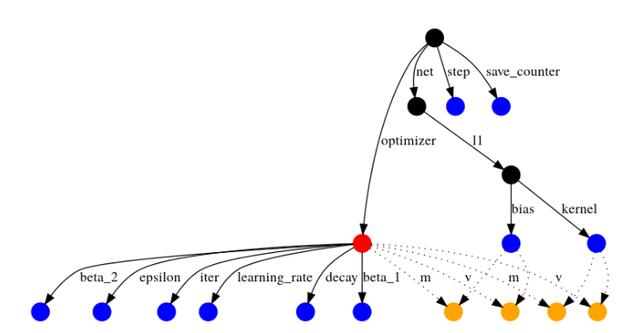
通過文檔進行模型恢復的依賴圖
- if ckpt_manager.latest_checkpoint:
- ckpt.restore(ckpt_manager.latest_checkpoint)
10. Keras Tuner
這是TensorFlow中的一個相當新的功能。
- !pip install keras-tuner
超參數調整(Hyper parameter tuning,Hypertuning)是對定義ML模型配置的參數進行篩選的過程。這些因素是特征工程和預處理后模型性能的決定因素。
- # model_builder is a function that builds a model and returns it
- tuner = kt.Hyperband(
- model_builder,
- objective='val_accuracy',
- max_epochs=10,
- factor=3,
- directory='my_dir',
- project_name='intro_to_kt'
- )
除了hyperand之外,bayesianomptimization和RandomSearch也可用于調整。
- tuner.search(
- img_train, label_train,
- epochs = 10,
- validation_data=(img_test,label_test),
- callbacks=[ClearTrainingOutput()]
- )
- # Get the optimal hyperparameters
- best_hps = tuner.get_best_hyperparameters(num_trials=1)[0]
此外,我們使用最佳超參數訓練模型:
- model = tuner.hypermodel.build(best_hps)
- model.fit(
- img_train,
- label_train,
- epochs=10,
- validation_data=(img_test, label_test)
- )
11.分布式訓練
如果你有多個GPU并且希望通過在多個GPU上分散訓練循環來優化訓練,TensorFlow的各種分布式訓練策略能夠優化GPU的使用并為你操縱GPU上的訓練。
MirroredStrategy是最常用的策略,它到底是怎么工作的?
- 所有變量和模型圖都復制到副本上。
- 輸入在副本中均勻分布。
- 每個副本計算它接收到的輸入的損失和梯度。
- 通過對所有副本進行求和,可以同步這些漸變。
- 同步之后,對每個副本上的變量副本進行相同的更新。
- strategy = tf.distribute.MirroredStrategy()
- with strategy.scope():
- model = tf.keras.Sequential([
- tf.keras.layers.Conv2D(
- 32, 3, activation='relu', input_shape=(28, 28, 1)
- ),
- tf.keras.layers.MaxPooling2D(),
- tf.keras.layers.Flatten(),
- tf.keras.layers.Dense(64, activation='relu'),
- tf.keras.layers.Dense(10)
- ])
- model.compile(
- loss="sparse_categorical_crossentropy",
- optimizer="adam",
- metrics=['accuracy']
- )
總結
TensorFlow足以構建機器學習中的所有組件。 本教程的主要內容是對TensorFlow提供的各種API的介紹,以及有關如何使用它們的快速操作指南。
Git代碼地址:https://github.com/rojagtap/tensorflow_tutorials



















