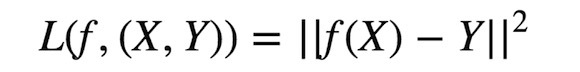機器學習入門之HelloWorld(Tensorflow)
源碼下載地址:https://share.weiyun.com/a0c1664d334c4c67ed51fc5e0ac5f2b2
初學機器學習,寫篇文章mark一下,希望能為將入坑者解點惑。本文介紹一些機器學習的入門知識,從安裝環境到跑通機器學習入門程序MNIST demo。
內容提綱:
- 環境搭建
- 了解Tensorflow運行機制
- MNIST(手寫數字識別 ) softmax性線回歸
- MNIST 深度卷積神經網絡(CNN)
- tools 工具類
- CPU & GPU & multi GPU
- 學習資料
1 環境搭建 (Windows)
- 安裝虛擬環境 Anaconda,方便python包管理和環境隔離。
Anaconda3 4.2 https://www.anaconda.com/downloads,自帶python 3.5。
- 創建tensorflow隔離環境。打開Anaconda安裝后的終端Anaconda Prompt,執行下面命令
- conda create -n tensorflow python=3.5 #創建名為tensorflow,python版本為3.5的虛擬環境
- activate tensorflow #激活這個環境
- deactivate #退出當前虛擬環境。這個不用執行
CPU 版本
- pip install tensorflow #通過包管理來安裝
- pip install whl-file #通過下載 whl 文件安裝,tensorflow-cpu安裝包:http://mirrors.oa.com/tensorflow/windows/cpu/tensorflow-1.2.1-cp35-cp35m-win_amd64.whl, cp35是指python3.5
GPU 版本。我的筆記本是技持NVIDIA顯卡的,可以安裝cuda,GPU比CPU快很多,不過筆記本的顯存不大,小模型還可以跑,大模型建議在本地用CPU跑通,到Tesla平臺上訓練。

注意點:選擇正確的 CUDA 和 cuDNN 版本搭配,不要只安裝最新版本,tensorflow可能不支持。
目前Tensorflow已支持到CUDA 9 & cuDNN 7,之前本人安裝只支持CUDA 8 & cuDNN 6,所以用是的:
CUDA8.1 https://developer.nvidia.com/cuda-80-ga2-download-archive
cudnn 6 https://developer.nvidia.com/cudnn ,將cudnn包解壓,把文件放到cuda安裝的對應目錄中,C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0,bin對應bin,include對應include,再添加bin目錄到環境變量path中。
- pip install tensorflow-gpu #通過包管理來安裝
- pip install whl-file #http://mirrors.oa.com/tensorflow/windows/gpu/tensorflow_gpu-1.2.1-cp35-cp35m-win_amd64.whl
一些python工具包安裝。用到啥安啥就行, pip install,不行就找源碼編譯安裝
- (tensorflow) D:\> pip install opencv-python #opencv, tensoflow 虛擬環境中
- (tensorflow) D:\> pip install scipy #圖片讀取寫入,scipy.misc.imread
- (tensorflow) D:\> pip install Pillow #PIL/Pillow,這里有個坑,壓縮過的PNG圖,在1.x版本解析會出現透明通道質量下降,升級
2 了解Tensorflow運行機制
- 上代碼。注意注釋說明
- import tensorflow as tf
- hello_world = tf.constant('Hello World!', dtype=tf.string) #常量tensor
- print(hello_world) #這時hello_world是一個tensor,代表一個運算的輸出
- #out: Tensor("Const:0", shape=(), dtype=string)
- hello = tf.placeholder(dtype=tf.string, shape=[None])#占位符tensor,在sess.run時賦值
- world = tf.placeholder(dtype=tf.string, shape=[None])
- hello_world2 = hello+world #加法運算tensor
- print(hello_world2)
- #out: Tensor("add:0", shape=(?,), dtype=string)
- #math
- x = tf.Variable([1.0, 2.0]) #變量tensor,可變。
- y = tf.constant([3.0, 3.0])
- mul = tf.multiply(x, y) #點乘運算tensor
- #logical
- rgb = tf.constant([[[255], [0], [126]]], dtype=tf.float32)
- logical = tf.logical_or(tf.greater(rgb,250.), tf.less(rgb, 5.))#邏輯運算,rgb中>250 or <5的位置被標為True,其它False
- where = tf.where(logical, tf.fill(tf.shape(rgb),1.), tf.fill(tf.shape(rgb),5.))#True的位置賦值1,False位置賦值5
- # 啟動默認圖.
- # sess = tf.Session()
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())#變量初始化
- result = sess.run(hello_world) #Fetch, 獲取tensor運算結果
- print(result, result.decode(), hello_world.eval())#`t.eval()` is a shortcut for calling `tf.get_default_session().run(t)`.
- #out: b'Hello World!' Hello World! b'Hello World!' #前輟'b'表示bytestring格式,decode解成string格式
- print(sess.run(hello, feed_dict={hello: ['Hello']}))
- #out: ['Hello']
- print(sess.run(hello_world2, feed_dict={hello: ['Hello'], world: [' World!']}))#Feed,占位符賦值
- #out: [b'Hello World!']
- print(sess.run(mul))
- #out: [ 3. 6.]
- print(sess.run(logical))
- #out: [[[ True] [ True] [False]]] #rgb中>250 or <5的位置被標為True,其它False
- print(sess.run(where))
- #out: [[[ 1.] [ 1.] [ 5.]]] #True的位置賦值1,False位置賦值5
- #sess.close()#sess如果不是用with方式定義,需要close
- Tensor。是一個句柄,代表一個運算的輸出,但并沒有存儲運算輸出的結果,需要通過tf.Session.run(Tensor)或者Tensor.eval()執行運算過程后,才能得到輸出結果。A Tensor is a symbolic handle to one of the outputs of an Operation,It does not hold the values of that operation's output, but instead provides a means of computing those values in a TensorFlow.
- Tensorflow運行過程:定義計算邏輯,構建圖(Graph) => 通過會話(Session),獲取結果數據。基本用法參見鏈接。
3 MNIST(手寫數字識別 ) softmax性線回歸
- 分析
MNIST是一個入門級的計算機視覺數據集,它包含各種手寫數字圖片:
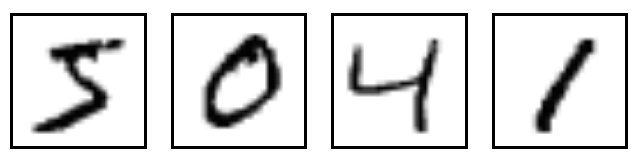
它也包含每一張圖片對應的標簽,告訴我們這個是數字幾。比如,上面這四張圖片的標簽分別是5,0,4,1。
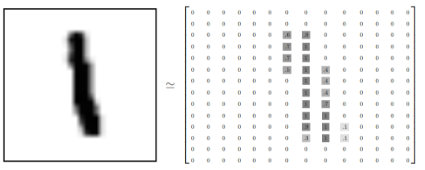
數據集圖片大小28x28,單通道灰度圖。存儲樣式如下:
MNIST手寫數字識別的目的是輸入這樣的包含手寫數字的28x28的圖片,預測出圖片中包含的數字。
softmax線性回歸認為圖片中數字是N可能性由圖像中每個像素點用

表示是 數字 i 的可能性,計算出所有數字(0-9)的可能性,也就是所有數字置信度,然后把可能性最高的數字作為預測值。
evidence的計算方式如下:
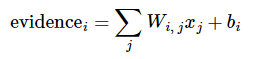
其中
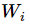
代表權重,

代表數字 i 類的偏置量,j 代表給定圖片 x 的像素索引(0~28x28=784),用于像素求和。即圖片每個像素值x權重之和,再加上一個偏置b,得到可能性值。
引入softmax的目的是對可能性值做歸一化normalize,讓所有可能性之和為1。這樣可以把這些可能性轉換成概率 y:
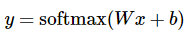
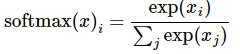
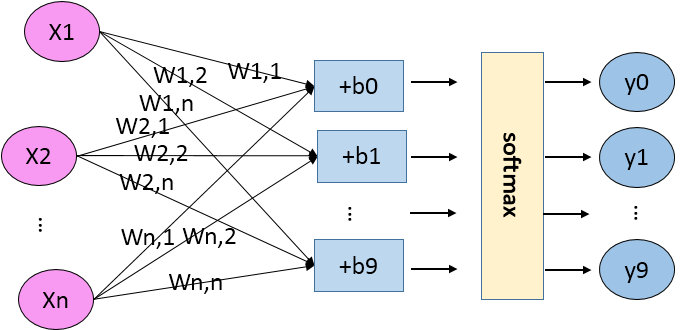
- 開始實現
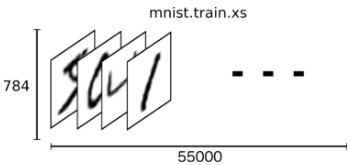
數據
X樣本 size 28x28 = 784
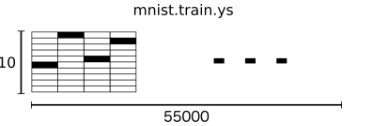
Y樣本 ,樣式如
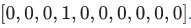
讀取
- from tensorflow.examples.tutorials.mnist import input_data
- mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True) #total 55000,one_hot方式,圖片x格式為1維數組,大小784
- batch_xs, batch_ys = mnist.train.next_batch(batch_size) #分batch讀取
構建圖(Graph)
Inference推理,由輸入 x 到輸出預測值 y 的推理過程
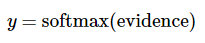

- x = tf.placeholder(tf.float32, [None, 784], name="input")#None表示batch size待定
- with tf.variable_scope("inference"):#定義作用域,名子inference
- W = tf.Variable(tf.zeros([784, 10])) #初值為0,size 784x10
- b = tf.Variable(tf.zeros([10])) #初值為0 size 10
- y = tf.matmul(x, W) + b #矩陣相乘
Loss 損失函數,分類一般采用交叉熵,這里用的是softmax交交叉熵。交叉熵是用來度量兩個概率分布間的差異性信息,交叉熵公式如下:
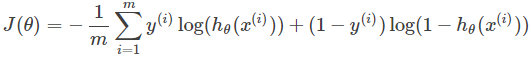
- with tf.variable_scope("loss"):
- loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y), name="loss")
- #softmax交叉熵公式: z * -log(softmax(x)) + (1 - z) * -log(1 - softmax (x)) # x: logits, z: label
計算loss的方法有很多種,常見的還有L1 loss 、L2 loss、sigmoid 交叉熵、聯合loss、自定義loss...
Accuracy 準確率,預測值與真實值相同的概率。矩陣相乘輸出y值是一個數組,tf.argmax函數可能從數據中找出最大元素下標,預測值的最大值下標和真值的最大值下標一致即為正確。
- with tf.variable_scope("accuracy"):
- accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)), tf.float32), name="accuracy")
Training 訓練,訓練的目的是讓Loss接近最小化,預測值接近真值,Tensorflow通過優化器Optimizers來實現。在y = Wx+b中,W、b在訓練之初會賦初值(隨機 or 0),經過Optimizer不短優化,Loss逼近最小值,使W、b不斷接近理想值。W、b一起共784x10+10個參數。
- train_step = tf.train.GradientDescentOptimizer(FLAGS.learning_rate).minimize(loss)
minimize函數:更新參數,讓Loss最小化,包含兩個步驟:計算梯度;更新參數。
- grad_var = compute_gradients(loss) # return (gradient, variable) pairs
- apply_gradients(grad_var) #沿著參數的梯度反方向更新參數,讓Loss變小
GradientDescentOptimizer:梯度下降算法優化器, Tensorflow實現的是SGD(隨機梯度下降)。其缺點是依賴當前batch,波動較大。
其它一些增強版Optimizers:參考鏈接。 MomentumOptimizer、AdadeltaOptimizer、AdamOptimizer、RMSPropOptimizer、AdadeltaOptimizer ...
Session:Tensorflow需要通過Session(會話)來執行推理運算,有兩種創建方式,兩者差別在于InteractiveSession會將自己設置為默認session,有了默認session,tensor.eval()才能執行。
- sess = tf.Session()
- sess = tf.InteractiveSession()
也可以通過下設置默認session:
- with sess.as_default(): xx.eval()
- with tf.Session() as sess: xx.eval()
配置gpu相關session參數:
- sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)#允許沒有gpu或者gpu不足時用軟件模擬
- sess_config.gpu_options.allow_growth = True #動態申請顯存。不加會申請全部,導致其他訓練程序不能運行
- #sess_config.gpu_options.per_process_gpu_memory_fraction = 0.8 #按比例申請顯存
- sess = tf.InteractiveSession(config=sess_config)
一個網絡的訓練過程是一個不斷迭代(前向+反向)的過程。前向算法由前向后計算網絡各層輸出,反向算法由后向前計算參數梯度,優化參數,減小Loss。流程如圖:
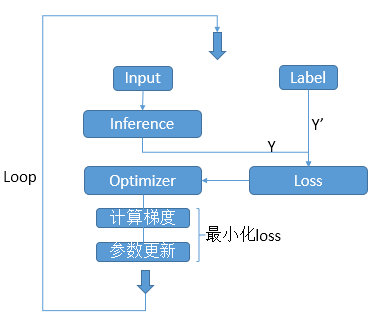
注意:每隔一段時間輸出一下網絡Loss和Accuracy,查看效果。每隔一段時間緩存一下網絡參數,防止被突然中斷,可再恢復。
模型參數的保存與恢復:
check point:默認保存方式。
pb:mobile使用。
npz:字典保存方式,{name: value}, numpy的一種保存方式。對參數按名保存,按名恢復。save和restore方法自己控制,可以選擇性保存和恢復。參見附近代碼中【tools.py】save_npz_dict & load_and_assign_npz_dict方法。
- saver = tf.train.Saver(max_to_keep = 3, write_version = 2)
- save_path = saver.save(sess, FLAGS.out_model_dir+'/model.ckpt')# check point方式
- output_graph_def = tf.graph_util.convert_variables_to_constants(sess, sess.graph_def, output_node_names=['output'])#指定輸出節點名稱,這個需要在網絡中定義
- with tf.gfile.FastGFile(FLAGS.out_model_dir+'/mobile-model.pb', mode='wb') as f:
- f.write(output_graph_def.SerializeToString()) #pb方式
- tools.save_npz_dict(save_list=tf.global_variables(), name=FLAGS.out_model_dir+'/model.npz', sess=sess) #pnz方式
恢復:
- #check point
- saver = tf.train.Saver(max_to_keep = 3, write_version = 2)
- model_file=tf.train.latest_checkpoint(FLAGS.log_dir)
- if model_file:
- saver.restore(sess, model_file)
- #npz
- tools.load_and_assign_npz_dict(name=FLAGS.log_dir+'/model.npz', sess=sess))打印網絡中各參數信息:方便查看網絡參數是否正確。
- def print_all_variables(train_only=False):
- if train_only:
- t_vars = tf.trainable_variables()
- print(" [*] printing trainable variables")
- else:
- t_vars = tf.global_variables()
- print(" [*] printing global variables")
- for idx, v in enumerate(t_vars):
- print(" var {:3}: {:15} {}".format(idx, str(v.get_shape()), v.name))
- 可視化。Tensorflow提供tensorboard可視化工具,通過命令打開web服務,由瀏覽器查看,輸入網址http://localhost:6006
- tensorboard --logdir=your-log-path #path中不要出現中文
- # 需要在訓練過程指定相應log路徑,寫入相關信息
- # 參考附件【sample.py】中summary、writer相關關鍵字代碼。
Graph可視化:

訓練過程可視化:
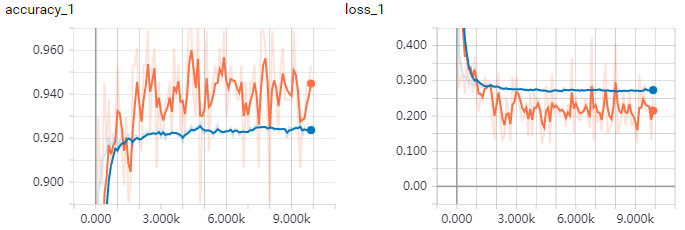
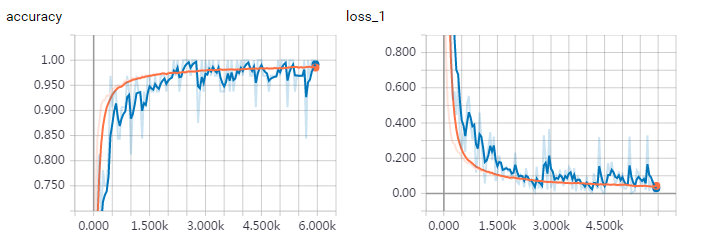
batch size = 128, 訓練集,驗證集。可以看到loss在收斂,accuracy在提高。由于訓練集曲線反應的是當前batch的loss和accuracy,batch size相對不高,抖動較大。而驗證集是全部圖片進行測試,曲線較平滑。
4 MNIST深度卷積神經網絡(CNN)
Softmax性線回歸網絡中,輸出y是輸入x的線性組合,即y = Wx+b,這是線性關系。在很多問題中其解法并非線性關系能完成的,在深度學習,能過能多層卷積神經網絡組合非線性激活函數來模擬更復雜的非線性關系,效果往往比單一的線性關系更好。先看深度卷積神經網絡(CNN,Convolutional Neural Network)構建的MNIST預測模型,再逐一介紹各網絡層。
- MNIST CNN Inference推理圖。從輸入到輸出中間包含多個網絡層:reshape、conv卷積、pool池化、fc全鏈接、dropout。自底向上輸入原始圖片數據x經過各層串行處理,得到各數字分類概率預測輸出y。Inference的結果轉給loss用作迭代訓練,圖中的

可以看出用的是AdamOptimizer優化器。
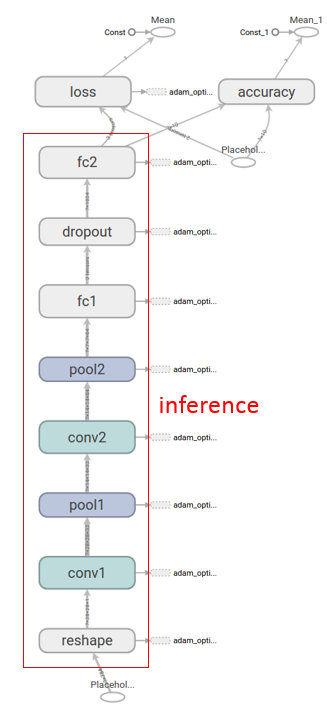
- reshape 變形,對數據的邏輯結構進行改變,如二維變四維:[1, 784] => [1, 28, 28, 1],數據存儲內容未發生改變。這里由于輸入數據存儲的手寫圖片是一維數據,轉成[batch_size, height, width, channels]格式
- with tf.name_scope('reshape'): #scope
- inputs = tf.reshape(inputs, [-1, 28, 28, 1])
- #[batch_size, height, width, channels], batch size=-1表示由inputs決定,
- #batch_size=inputs_size/(28x28x1)
- conv2d 卷積, 卷積核(yellow)與Image元(green)素相乘,累加得到輸出元素值(red)。Image的每個Channel(通道)都對應一個不同的卷積核,Channel內卷積核參數共享。所有輸入channel與其kernel相乘累加多層得到輸出的一個channel值。輸出如有多個channel,則會重復多次,kernel也是不同的。所以會有input_channel_count * output_channel_count個卷積核。在卷積層中訓練的是卷積核。
- def conv2d(x, W): #W: filter [kernel[0], kernel[1], in_channels, out_channels]
- return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
tf.nn.conv2d:
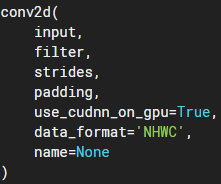
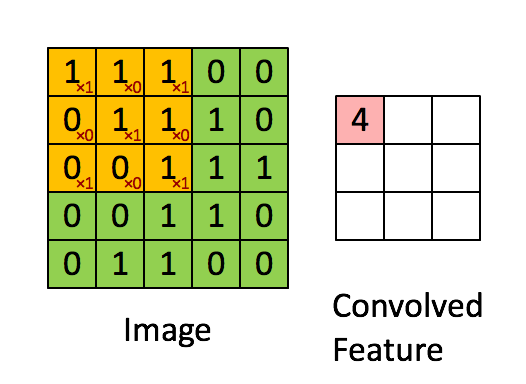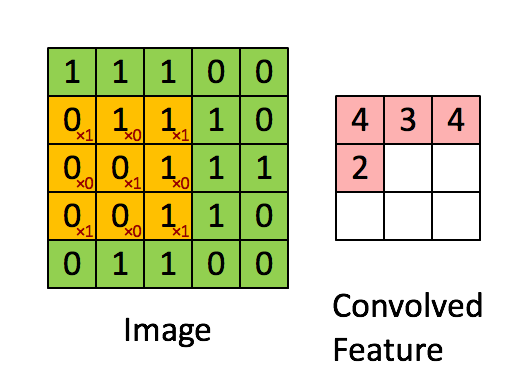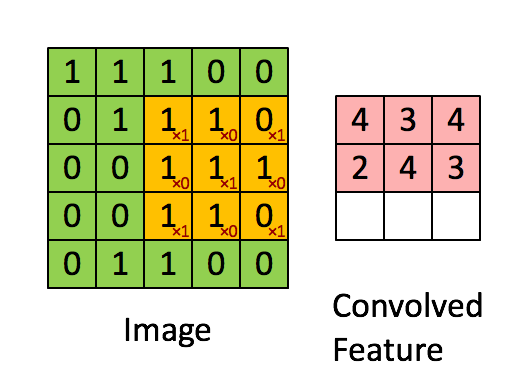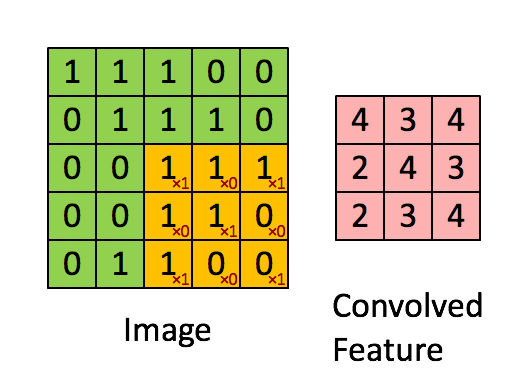
data_format: input和output數據的邏輯結構,NHWC : batch height width channel。NCHW: batch channel height width。常用的是NHWC格式;在一些輸入數據中各通道數據分開存放,這種更適合NCHW。
input:輸入,data_format=NHWC時,shape為batch, in_height, in_width, in_channels,Tensor。
filter:卷積核,shape為filter_height, filter_width, in_channels, out_channels,共有in_channels*out_channels個filter_height, filter_width的卷積核,輸入輸出channel越多,計算量越大。
strides: 步長,shape為1, stride_h, stride_w, 1,通常stride_h和stride_w相等,表示卷積核延縱橫方向上每次前進的步數。上gif圖stride為1。
padding:卷積計算時數據不對齊時填充方式,VALID:丟棄多余;SAME:兩端補0,讓多余部分可被計算。

output:輸出,shape為batch, out_height, out_width, out_channels
- output[b, i, j, k] =
- sum_{di, dj, q} input[b, strides[1] * i + di, strides[2] * j + dj, q] *
- filter[di, dj, q, k]
- 激活函數,與卷積搭配使用。激活函數不是真的要去激活什么,在神經網絡中,激活函數的作用是能夠給神經網絡加入一些非線性因素,使得神經網絡可以更好地解決較為復雜的問題。
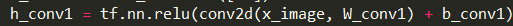
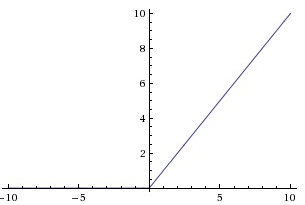
tf.nn.relu即是激活函數,對卷積輸出作非線性處理,其函數如下:
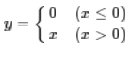
其它還有如sigmoid:
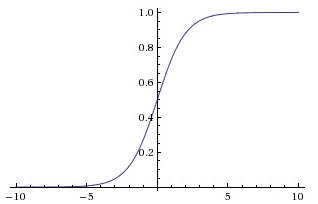
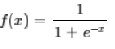
tanh:

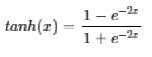
- Pool池化,有最大池化和平均值池化,計算與卷積計算類似,但無卷積核,求核所覆蓋范圍的最大值或平均值,輸入channel對應輸出channel,沒有多層累加情況。輸入與輸出 channel數相同,輸出height、width取決于strides。
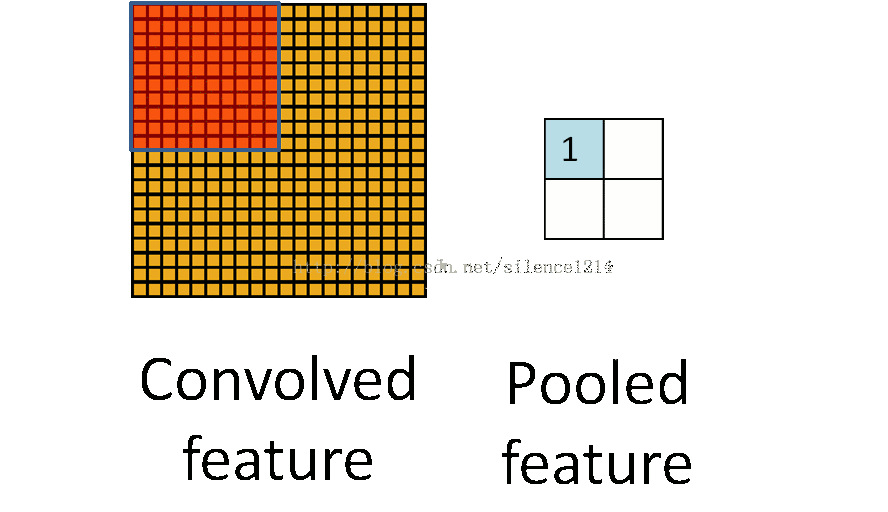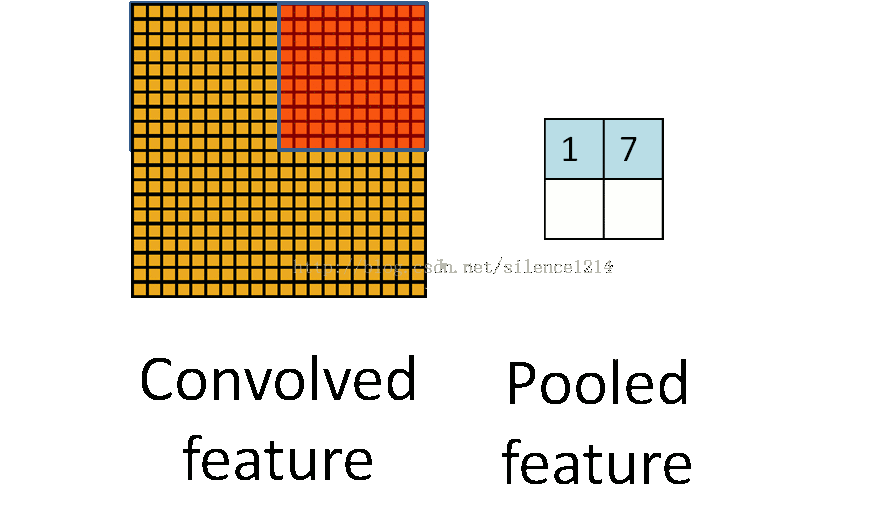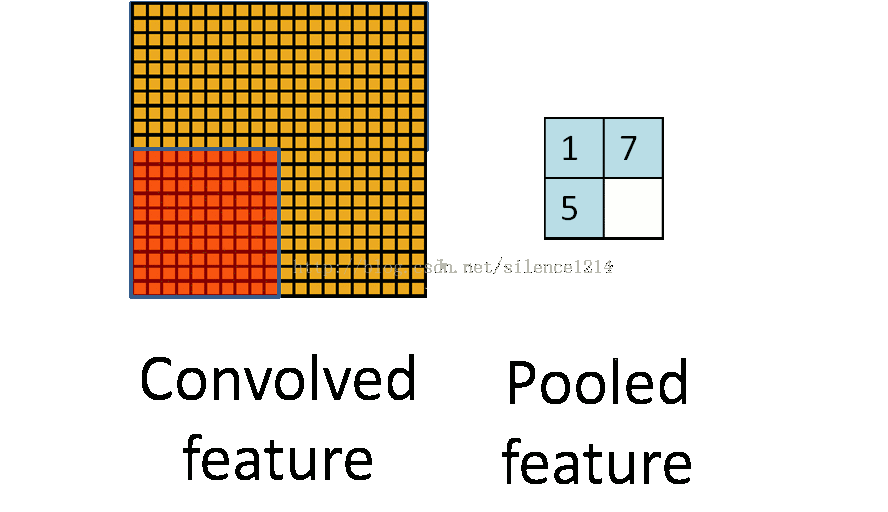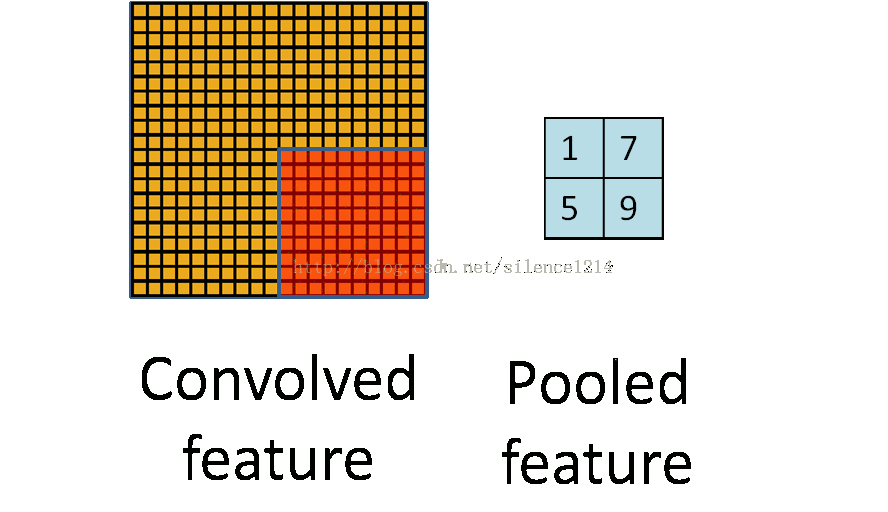
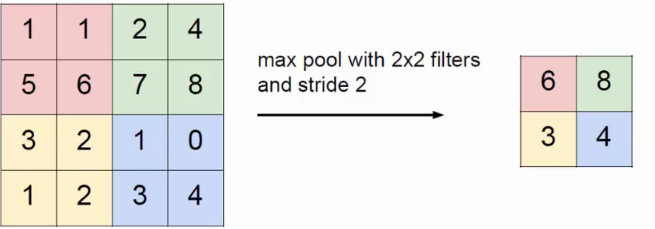
- if is_max_pool:
- x = tf.nn.max_pool(x, [1,kernel[0],kernel[1],1], strides=[1,stride[0],stride[1],1], padding=padding, name='pool')
- else:
- x = tf.nn.avg_pool(x, [1,kernel[0],kernel[1],1], strides=[1,stride[0],stride[1],1], padding=padding, name='pool')
- Dropout,隨機刪除一些數據,讓網絡在這些刪除的數據上也能訓練出準確的結果,讓網絡有更強的適應性,減少過擬合。
- x = tf.nn.dropout(x, keep_prob) #keep_prob 保留比例,keep_prob=1.0表示無dropout
- BN(batch normalize),批規范化。Inference中未標出,demo中未使用,但也是網絡中很常用的一層。BN常作用在非線性映射前,即對Conv結果做規范化。一般的順序是 卷積-> BN -> 激活函數。
BN好處:提升訓練速度,加快loss收斂,增加網絡適應性,一定程序的解決反向傳播過程中的梯度消失和爆炸問題。詳細請戳。
- FC(Full Connection)全連接,核心是矩陣相乘
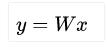
,softmax性線回歸就是一個FC。在CNN中全連接常出現在最后幾層,用于對前面設計的特征做加權和。Tensorflow提供了相應函數tf.layers.dense。
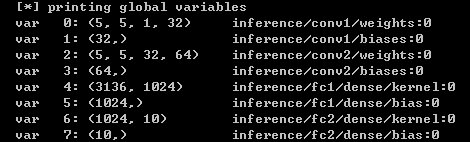
- 日志,下圖打印了模型中需要訓練的參數的shape 和 各層輸出數據的shape(batch_size=1時),附件【tool.py】中有相關代碼。目的是方便觀自己搭的網絡結構是否符合預期。
數據由[1x784] -reshape-> [1x28x28x1](batch_size, height, width, channels) -conv-> [1x28x28x32] -pool-> [1x14x14x32] -conv-> [1x14x14x64] -pool-> [1x7x7x64] -fc-> [1x1024] -fc-> [1x10](每類數字的概率)
- 訓練效果,詳細代碼參考附件【cnn.py】
- 一個網上的可視化手寫識別DEMO,http://scs.ryerson.ca/~aharley/vis/conv/flat.html
- CNN家族經典網絡,如LeNet,AlexNet,VGG-Net,GoogLeNet,ResNet、U-Net、FPN。它們也都是由基本網絡層元素(上述介紹)堆疊而成,像搭積木一樣。
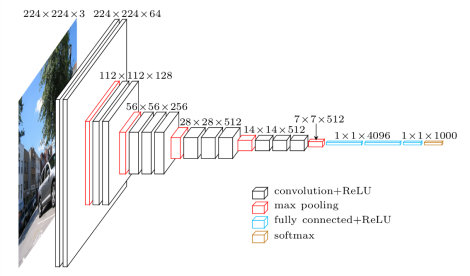
VGG,如下圖,非常有名的特征提取和分類網絡。由多層卷積池化層組成,最后用FC做特征融合實現分類,很多網絡基于其前幾層卷積池化層做特征提取,再發展自己的業務。
5 tool工具類
【tool.py】是一個自己基于tensorflow二次封裝的工具類,位于附件中。好處是以后編程更方便,代碼結構更好看。網上也有現成的開源庫,如TensorLayer、Keras、Tflearn,自己封裝的目的是更好的理解tensorflow API,自己造可控性也更強一些,如果控制是參數是否被訓練、log打印。
下圖是MNIST CNN網絡的Inference推理代碼:

6 CPU & GPU & multi GPU
- CPU, Tensorflow默認所有cpu都是/cpu:0,默認占所有cpu,可以通過代碼指定占用數。
- sess_config = tf.ConfigProto(device_count={"CPU": 14}, allow_soft_placement=True, log_device_placement=False)
- sess_config.intra_op_parallelism_threads = 56
- sess_config.inter_op_parallelism_threads = 56
- sess = tf.InteractiveSession(config=sess_config)
- GPU,Tensorflow默認占用/gpu:0, 可通過指定device來確定代碼運行在哪個gpu。下面
- with tf.device('/device:GPU:2'):
- a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
- b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
- c = tf.matmul(a, b)
- #下面的代碼配置可以避免GPU被占滿,用多少內存占多少
- sess_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
- sess_config.gpu_options.allow_growth = True
- sess_config.gpu_options.per_process_gpu_memory_fraction = 0.8
- sess = tf.InteractiveSession(config=sess_config)
多塊GPU時,可以通過在終端運行下面指令來設置CUDA可見GPU塊來控制程序使用哪些GPU。
- export CUDA_VISIBLE_DEVICES=2,3
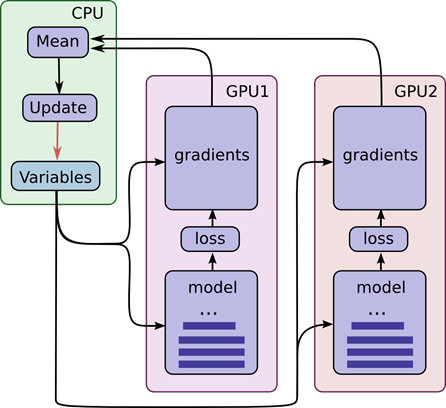
- 多GPU使用,在Tensorflow中多GPU編程比較尷尬,資料較好,代碼寫起比較復雜,這一點不如Caffe。
在Tensorflow中你需要自己寫代碼控制多GPU的loss和gradient的合并,這里有個官方例子請戳。自己也寫過多GPU的工程,附件代碼【tmp-main-gpus-不可用.py】可做參考,但此處不可用,來自它工程。
7 學習資料
收藏了一些機器學習相關資料,分享一下。自己也只看過很小一部分,仍在學習中....
Google最近出的機器學習速成課程 https://developers.google.cn/machine-learning/crash-course/ml-intro
斯坦福大學公開課 :機器學習課程 Andrew Ng吳恩達 http://open.163.com/special/opencourse/machinelearning.html
我愛機器學習博客 https://www.52ml.net/
曉雷機器學習筆記 https://zhuanlan.zhihu.com/xiaoleimlnote
lilicao博客 http://www.cnblogs.com/lillylin/
貓狗大戰知乎專欄 https://zhuanlan.zhihu.com/alpha-smart-dog
計算機視覺,機器學習相關領域源代碼大集合 https://zhuanlan.zhihu.com/p/26691794
物體檢測大集合 https://handong1587.github.io/deep_learning/2015/10/09/object-detection.html#r-cnn
機器學習筆記 https://feisky.xyz/machine-learning/
原文鏈接:https://cloud.tencent.com/developer/article/1058521
【本文是51CTO專欄作者“云加社區”的原創稿件,轉載請通過51CTO聯系原作者獲取授權】