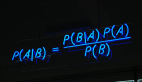教你輕松選擇合適的機器學習算法!
譯文【51CTO.com快譯】
這個問題沒有簡單明了的答案。答案取決于許多因素,比如問題陳述、預期的輸出類型、數據的類型和大小、可用的計算時間、特征數量以及數據中的觀測點等。
選擇算法時,有幾個重要因素要考慮。
1. 訓練數據的大小
通常建議收集大量數據以獲得可靠的預測。但很多時候,數據的可用性是個約束。因此,如果訓練數據較小,或者數據集的觀測點數量較少,而遺傳或文本數據等特征數量較多,應選擇具有高偏差/低方差的算法,比如線性回歸、樸素貝葉斯或線性SVM。
如果訓練數據足夠大,觀測點數量比特征數量多,可以采用低偏差/高方差算法,比如KNN、決策樹或內核SVM。
2. 輸出的準確性及/或可解釋性
模型的準確性意味著函數可預測特定觀測點的響應值,該響應值接近該觀測點的真實響應值。一種高度可解釋的算法(諸如線性回歸等限制性模型)意味著,人們可以輕松理解任何單個預測變量與響應有怎樣的關聯,而靈活的模型以低可解釋性換取更高的準確性。

圖1. 使用不同的統計學習方法來表示準確性和可解釋性之間的取舍。
一些算法名為“限制性”算法,因為它們會生成小范圍的映射函數形狀。比如說,線性回歸是一種限制性方法,因為它只能生成線性函數,例如直線。
一些算法被稱為靈活算法,因為它們可以生成更廣泛范圍的映射函數形狀。比如說,k = 1的KNN有高度靈活性,因為它會考慮每個輸入數據點以生成映射輸出函數。下圖顯示了靈活算法和限制性算法之間的取舍。
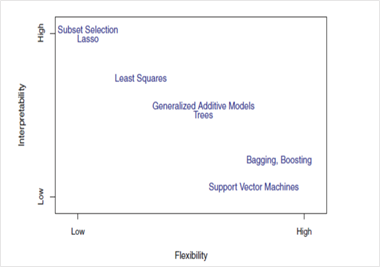
圖2. 使用不同的統計學習方法來表示靈活性和可解釋性之間的取舍。
現在,使用哪種算法取決于業務問題的目標。如果推理是目標,那么限制性模型更好,因為它們極容易解釋。如果更高的準確度是目標,靈活模型更好。隨著方法的靈活性提高,可解釋性通常隨之下降。
3. 速度或訓練時間
更高的準確度通常意味著更長的訓練時間。而且,算法需要更多時間來訓練龐大的訓練數據。在實際應用中,算法的選擇主要取決于這兩個因素。
樸素貝葉斯和線性與邏輯回歸等算法易于實現且運行迅速。像需要調整參數的SVM、收斂時間長的神經網絡和隨機森林這些算法需要大量時間來訓練數據。
4.線性度
許多算法都基于這一假設:類可以用直線(或其高維模擬)來分隔。例子包括邏輯回歸和支持向量機。線性回歸算法假設數據趨勢遵循一條直線。如果數據是線性的,則這些算法執行起來效果很好。
然而,數據并非總是線性的,因此我們需要其他能夠處理高維和復雜數據結構的算法。例子包括內核SVM、隨機森林和神經網絡。
找出線性度的最佳方法是擬合線性線,或者運行邏輯回歸或SVM以檢查殘差。較高的誤差意味著數據不是線性的,需要復雜的算法才能擬合。
5. 特征數量
數據集可能有大量的特征,這些特征可能并非全部相關且重要。對于某個類型的數據,比如遺傳或文本數據,特征的數量與數據點的數量相比可能非常大。
大量特征可能會使一些學習算法陷入困境,從而導致訓練時間過長。SVM更適合數據有龐大特征空間且觀測點較少的情況。應該使用PCA和特征選擇方法來減少維度,并選擇重要特征。
下面這個方便的速查表詳細介紹了可用于解決不同類型的機器學習問題的算法。
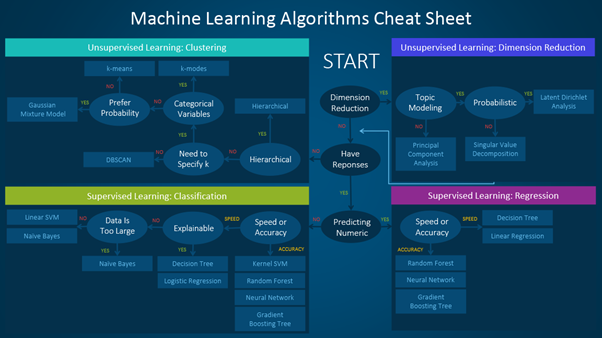
機器學習算法可以分為監督學習、無監督學習和強化學習。本文介紹如何使用該速查表的過程。
速查表主要分為兩種學習類型:
- 在訓練數據擁有與輸入變量相對應的輸出變量的情況下,采用監督學習算法。該算法分析輸入數據并學習函數,以映射輸入變量和輸出變量之間的關系。
監督學習可以進一步分為回歸、分類、預測和異常檢測。
- 訓練數據沒有響應變量時,使用無監督學習算法。這類算法試圖找到數據中的固有模式和隱藏結構。聚類和降維算法是無監督學習算法的兩種類型。
以下信息圖只解釋了回歸、分類、異常檢測和聚類,以及可以運用這每一種方法的例子。
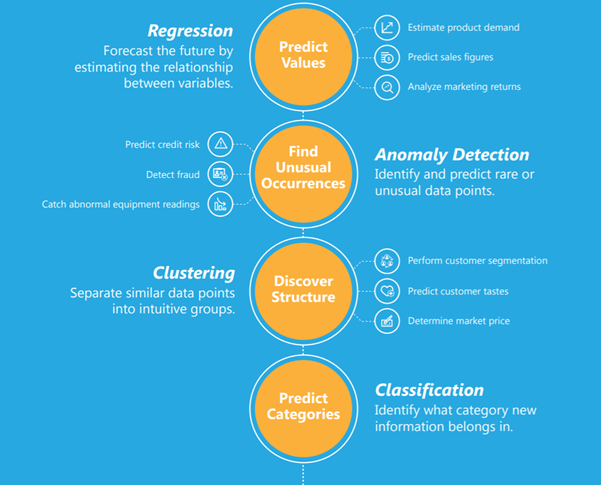
試圖解決新問題時要考慮的主要點是:
- 定義問題。問題的目的是什么?
- 探究數據并熟悉數據。
- 從基本模型入手以構建一個基準模型,然后嘗試更復雜的方法。
話雖如此,請記住:“更好的數據常常勝過更好的算法”。同樣重要的是設計良好的特征。嘗試一堆算法,并比較其性能,以選擇最適合您特定任務的算法。另外,請嘗試集成(ensemble)方法,因為它們通常提供極高的準確性。
原文標題:An easy guide to choose the right Machine Learning algorithm,作者:Yogita Kinha
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】