













糗大了!CPU一味求快出事兒了......
我叫阿 Q,是 CPU 一號車間里的員工,我所在的這個 CPU 足足有 8 個核,就有 8 個車間,干起活來杠杠滴。
圖片來自 Pexels
01.CPU 一味求快出事兒了
我所在的一號車間里,除了負責執行指令的我,還有負責取指令的小 A,負責分析指令的小胖和負責結果回寫的老 K。
CPU 的每個車間都有一堆箱子,人們把這些箱子叫做寄存器,我所在的一號車間也不例外,我們每天的工作就是不斷執行指令,然后折騰這些箱子,往里面存東西取東西。
由于我們四個人的出色工作,一號車間業績突出,在年會上還多次獲得了最佳 CPU 核心獎呢。
緩存
我們每天都需要跟內存打交道,不過由于內存這家伙實在太慢了,我們浪費了很多時間等待他給我們數據傳輸。
終于有一天,上面給我們下了命令,說競爭對手 CPU 的速度快趕上我們了,讓我們想辦法提升工作效率。
這一下可難倒了我們,我們平時干活絕沒有偷懶,要怪只能怪內存那家伙,是他拖了我們后腿。
一天晚上,我們哥四個在一起聚餐,討論起上面的這道命令來,大家都紛紛嘆氣。
就在一籌莫展之際,老 K 提出了一個想法:“兄弟們,我發現了一個現象,咱們和內存打交道的時候,如果訪問了某個地址的數據,它周圍的數據隨后也大概率會被訪問到”,說到這里,老 K 停頓了一下。
我一邊聽一邊想著,小 A 倒是先開口:“然后呢?你想表達什么意思?”
老 K 繼續說道:“咱每次數據都找內存要,太慢了,我尋思在咱們車間劃一塊區域,結合我發現的那個現象,以后讓內存一次性把目標區域附近的數據一起給我們,我們存在這塊區域,后面在需要用到的時候就先去這里找,找不到再去找內存要,豈不省事?”
聽老 K 這么一描述,感覺靠譜,我也趕緊附和:“好辦法!你們看啊,這內存老是拖咱后退,但是這家伙一時半會也快不起來,要不咱先用這招試試,看看能不能加快一點工作效率,給上面也有個交代。”
說干就干,我們很快就付諸實踐了,我們還給這技術取了個名字叫緩存,效果居然出奇的好。
后來為了進一步優化,我們還把緩存分為了兩塊,一塊離寄存器很近叫一級緩存,剩下的叫二級緩存。一級緩存中進一步分了指令緩存和數據緩存兩塊。

我們車間的工作效率那是飛速提升,但不知道是誰走漏了風聲,其他幾個車間也知道了這項技術,紛紛效仿。
這天,為了業績,我們決定再加第三級緩存,這次把空間弄大點,不過咱們車間地盤有點局促,放不下,我們偷偷給上面領導反饋了這事兒,想讓領導幫我們協調一下。
領導倒是同意了,不過告訴我們他得一碗水端平,平衡各車間的利益。但是咱廠里空間也有限,不可能給每個車間都分配那么大的空間,于是決定由廠里統一安排一塊大的區域,讓各個車間來共享。沒有辦法,我們也只好同意了。
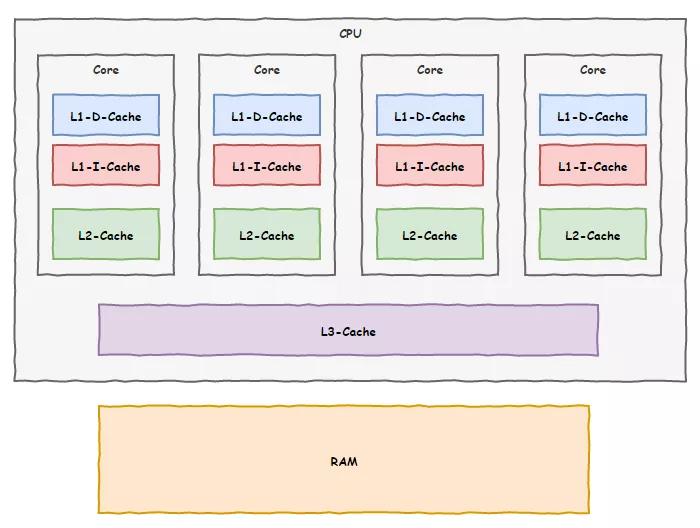
現在,我們用上了三級緩存技術,內存那家伙拖后腿的現象緩解了不少,相當部分時間我們都能從這三級緩存里面找到我們需要的數據。
亂序執行
隨著技術的發展,咱們 CPU 工廠的工作性能也是不斷攀升,慢慢的,我們幾個又開始閑下來了,因為我們實在太快了,盡管有了緩存,但我們還是有了不少閑暇時間。
這天我還是像往常一樣,小 A 取指令去了,我們知道這得要點時間,于是我和小胖還有老 K 我們仨斗起了地主。

打了好幾把,小 A 才氣喘吁吁的回來,“小胖,該你去指令分析了,你起來讓我來打幾把”。小胖趕緊起身干活,換上了小 A 上桌。
就這樣我們幾個輪流工作,一直保持著三個人的斗地主牌桌。
沒想到的是,沒過多久,廠里領導過來視察了,正好撞見我們幾個打牌,狠狠的訓斥了我們一頓。
“你們幾個上班時間玩得挺嗨啊”,領導的臉拉的老長。
“領導,我們沒有偷懶,這取指令、譯碼、執行、回寫幾個步驟都得分步執行,但是我們工作太快,存儲器跟不上我們,我們等得無聊打發時間嘛”,我上前解釋到。
“干等著你們也可以提前做一些后面的準備工作嘛,不要浪費時間,讓生產效率更上一層樓”,領導說完就離開了,留下我們幾個面面相覷。
不過領導的一番話倒是如一記重錘敲在我的頭上,對啊,我們有這打牌的時間不如提前把后續指令的準備工作先做了,肯定能提升不少效率呢!
我開始組織兄弟幾個商討方案,“兄弟們,我們最主要的時間都浪費在等待內存數據上了,如果我們能在等待的時間里把后續指令需要的數據提前準備到緩存中來,那可就節約不少時間了,不用每次都等那么久。”
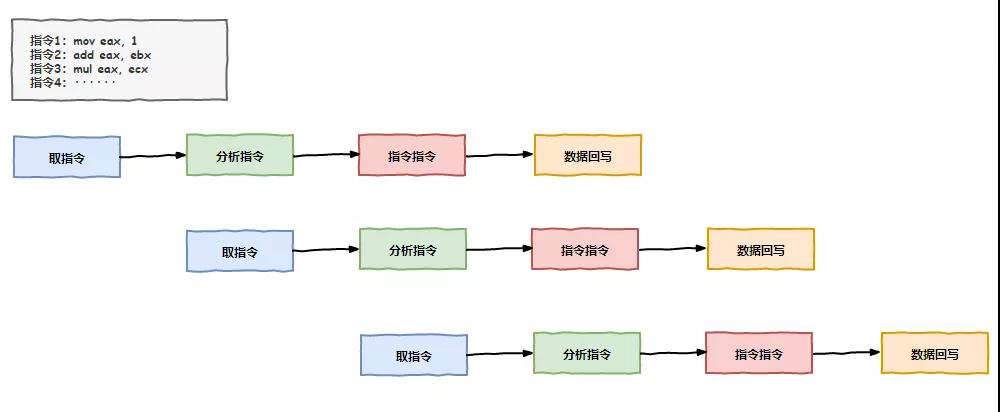
老 K 聽后很贊賞我的思路,并補充到:“不僅是準備工作,像有些指令,比如加法,如果參與加法的數據不依賴前面指令的結果,咱們完全可以提前把這加法指令執行了嘛,把結果保存在緩存中,等真正輪到這條指令執行的時候,再把緩存中的結果寫到內存中,這不也是節約了時間嗎?”
大家開始頭腦風暴起來,原來可以做的事情還這么多,之前光想著等靠要,現在要主動出擊了,因為打亂了順序提前會執行后面的指令,我們把這個技術叫做亂序執行。
“這次大家要保密哦,不能讓隔壁車間知道咱們的這次討論內容”,會議結束前,我提醒大家。
分支預測
按照這次會議討論的結果,咱們第二天準備實行,不過剛一開始,就遇到了麻煩。
按照計劃,我們在空閑時間里,會提前把后續要執行的指令能做的工作先做了,但麻煩的是我們遇到了一條判斷指令。
因為不知道最終結果是 true 還是 false,我們沒法知道后續是應該執行分支 A 的指令還是分支 B 的指令。不敢輕舉妄動,怕一會做了無用功。
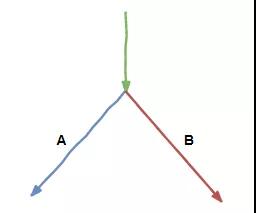
大家只好放棄了提前做準備工作的想法,還是一步步來。
不過很快我們發現,我們經常執行到這個判斷指令,而且每次結果都是去執行 A 分支,從沒有去過 B 分支。

于是我們幾個又商量,發明了一種叫分支預測的技術,遇到分支跳轉時,按照之前的經驗,如果某個分支經常被執行,那后續再去這個分支的概率一定很大。
那這樣咱們預測后面會去到這個分支,就提前把這個分支后面指令能做的工作先做了。
果然,用上了分支預測和亂序執行后,我們車間的效率又狠狠的提升了一把,在工廠的集體大會上又一次表揚了我們,并且把我們的先進技術向全廠推廣,在我們 8 個 CPU 核心車間都鋪開了,性能甩開競爭對手 CPU 幾條街。
然而幸福的日子沒過太長,我們就因為這兩項技術闖下了彌天大禍。
02.CPU 成了黑客的幫兇
那天,我們還是如往常一般工作,可不久發現我們的分支預測頻頻出錯,提前做的準備工作也屢屢白費,很快,我們發現出事兒了......

事情還得從不久前的一個晚上說起。
神秘代碼
這天晚上,我們一號車間遇到了這樣一段代碼:
- uint8_t array1[160] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
- uint8_t array2[256 * 512];
- uint8_t temp = 0;
- void bad_guy(int x) {
- if (x < 16) {
- temp &= array2[array1[x] * 512];
- }
- }
不到一會兒功夫,我們就執行了這個 bad_guy() 函數很多次,這不,又來了。
負責取指令的小 A 向內存那家伙打了一通電話,讓內存把參數 x 的內容傳輸過來,我們知道,以內存那蝸牛的速度,估計得讓我們好等。
這時,負責指令譯碼的小胖忍不住說了:“你們看,我們這都執行這個函數好多次了,每次的參數 x 都是小于 16 的,這一次估計也差不多,要不咱們啟動分支預測功能,先把小于 16 分支里的指令先提前做一些?大家看怎么樣”
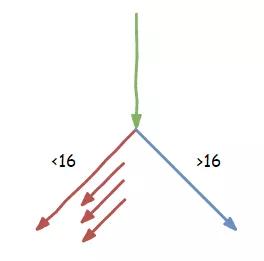
我和負責數據回寫的老 K 互相看了一眼,都點頭表示同意。
于是,就在等待的間隙,我們又給內存那家伙打了電話,讓他把 array1[x] 的內容也傳過來。
等了一會兒,數據總算傳了過來:
- x: 2
- array1[x]: 3
拿到結果之后,我們開始一邊執行 x<16 的比較指令,一邊繼續打電話給內存索要 array2[3] 的內容。
比較指令執行的結果不出所料,果然是 true,接下來就要走入我們預測的分支,而我們提前已經將需要的數據準備到緩存中,省去了不少時間。
就這樣,我們成功的預測了后續的路線,我們真是一群機智的小伙伴。
遭遇滑鐵盧
天有不測風云,不久,事情發生了變化。
“呀!比較結果是 false,這一次的 x 比 16 大了”,我執行完結果后發現和我們預期的有了出入。
小 A 聞訊而來,“額,咱們提前執行了不該執行的指令不會有問題吧?”
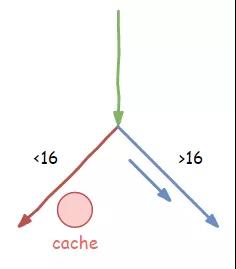
老 K 安慰道:“沒事兒,咱們只是提前把數據讀到了我們的緩存中,沒問題的,放心好啦”
我想了想也對,大不了我們提前做的準備工作白費了,沒有多想就繼續去執行>16 的分支指令了。
隨后,同樣的事情也時有發生,漸漸的我們就習慣了。
災難降臨
夜越來越深,我們都有點犯困了,突然,領導來了一通電話,讓我們放下手里的工作火速去他辦公室。
我們幾個不敢耽誤,趕緊出發。
來到領導的辦公室,里面多了兩個陌生人,其中一個還被綁著,領導眉頭緊鎖,氣氛很是緊張。
“阿 Q 啊,你知不知道你們新發明的亂序執行和分支預測技術闖了大禍了?”
我們幾個一聽傻眼了,“領導,這是從何說起啊?”
領導從椅子上站了起來,指著旁邊的陌生人說到:“給你們介紹一下,這是操作系統那邊過來的安全員,讓他告訴你們從何說起吧!”
這位安全員向大家點了點頭,指著被捆綁那人說道:“大家好,我們抓到這個線程在讀取系統內核空間的數據,經過我們的初審,他交代了是通過你們 CPU 的亂序執行和分支預測功能實現的這一目的。”
我和小 A 幾個一聽都是滿臉問號,我們這兩個提升工作效率的技術怎么就能泄漏系統內核數據呢?
真相大白
安全員顯然看出了我們的疑惑,指著被捆綁的那個線程說道:“你把之前交代的再說一遍”
“幾位大爺,你們之前是不是遇到了分支預測失敗的情況?”,那人抬頭看著我們。
“有啊,跟這有什么關系?失敗了很正常嘛,既然是預測那就不能 100% 打包票能預測正確啊”,我回答道。
“您說的沒錯,不過如果這個失敗是我故意策劃的呢?”
聽他這么一說,我的心一下懸了起來,“納尼,你干的?”
“是的,就是我,我先故意給你連續多次小于 16 的參數,誤導你們,誤以為后面的參數還是小于 16 的,然后突然來一個特意構造的大于 16 的參數,你們果然上鉤了,預測失敗,提前執行了一些本不該執行的指令。”
“那又如何呢?我們只是把后面需要的數據提前準備到了緩存中,并沒有進一步做什么啊”,我還是不太明白。
“這就夠了!”
“你小子都被捆上了,就別吊胃口了,一次把話說清楚”,一旁急性子的老 K 忍不住了。
“好好好,我這就交代。你們把數據提前準備到了緩存中,我后面去訪問這部分數據的時候,發現比訪問其他內存快了很多”
“那可不,我們的緩存技術可不是吹牛的!哎等等,怎么又扯到緩存上去了?”,老 K 繼續問道。
那人繼續說道:“如果我想知道某個地址單元內的值,我就以它作為數組的偏移,去訪問一片內存區域。利用你們會提前預測執行而且會把數據緩存的機制。你們雖然預測失敗了,但對應的那一塊數據已經在緩存中了,接著,我依次去訪問那一片內存,看看誰的訪問時間明顯比其他部分短,那就知道哪一塊被緩存了,再接著反推就能知道作為偏移的數值是多少了,按照這個思路我可以知道每一個地址單元的內容。”
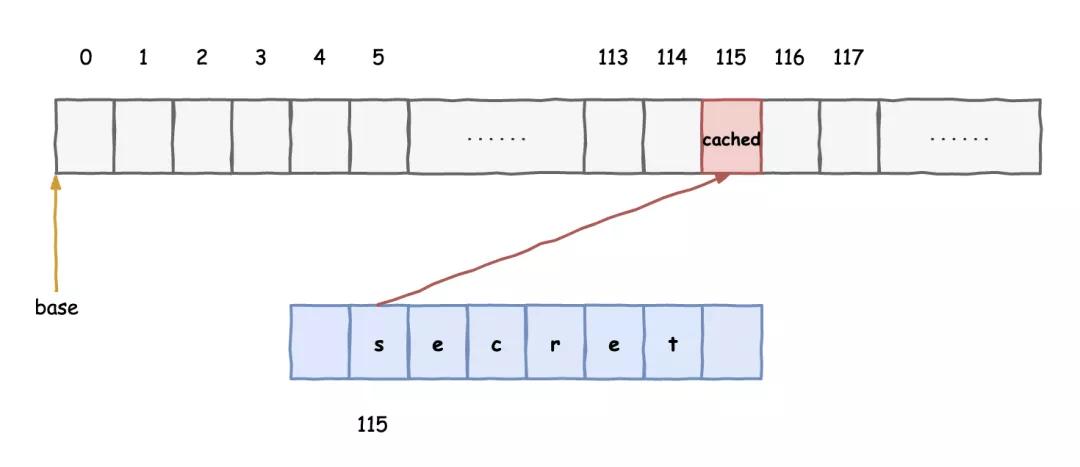
我們幾個一邊聽著一邊想著,琢磨了好一會兒總算弄清楚了這家伙的套路,老 K 氣得火冒三丈,差點就想動手修理那人。
“好你個家伙,倒是挺聰明的,可惜都不用在正途上!好好的加速優化機制竟然成為了你們的幫兇”,我心中也有一團火氣。
亡羊補牢
事情的真相總算弄清楚了,我們幾個此刻已經汗流浹背。
經過和安全員的協商,操作系統那邊推出了全新的 KPTI 技術來解決這個問題,也就是內核頁表隔離。
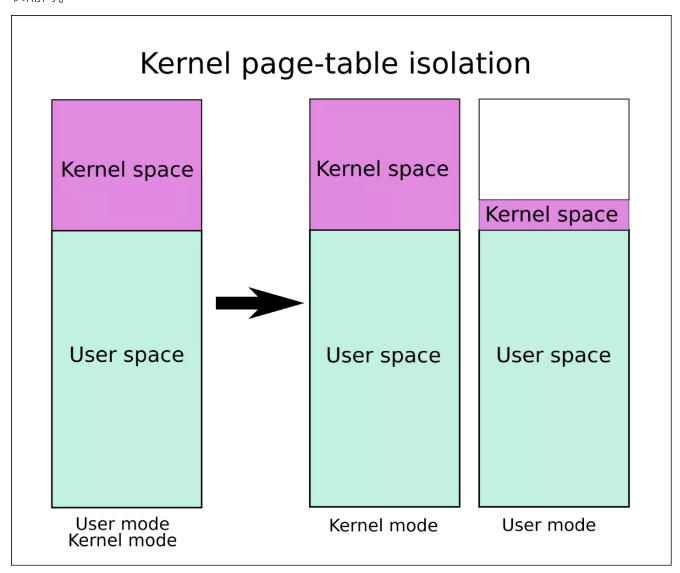
以前的時候,線程執行在用戶態和內核態時用的是同一本地址翻譯手冊,也就是人們說的頁表,通過這本手冊,我們 CPU 就能通過虛擬地址找到真實的內存頁面。
現在好了,讓線程運行在用戶態和內核態時使用不同的手冊,用戶態線程的手冊中,內核地址空間部分是一片空白,來一招釜底抽薪!
本以為我們可以回去了,沒想到領導卻給我們出了難題,“這禍是你們闖下的,人家操作系統那邊雖然做了保護,你們是不是也該拿出點辦法來呢,要不然以后我們 CPU 還怎么抬得起頭來?”
你有什么好辦法嗎,幫幫我們吧!
幕后
本節描述的是兩年前爆發的大名鼎鼎的 CPU 的熔斷與幽靈漏洞。
亂序執行與分支預測是現代處理器普遍采用的優化機制。和傳統軟件漏洞不同,硬件級別的漏洞影響更大更深也更難以修復。
通過判斷內存的訪問速度來獲知是否有被緩存,這類技術有一個專門的術語叫側信道,即通過一些場外信息來分析得出重要結論,進而達成正常途徑無法達成的目的。
03.CPU 瞞著內存竟干出這種事
今天忙里偷閑,來到廠里地址翻譯部門轉轉,負責這項工作的小黑正忙得滿頭大汗。
看到我的到來,小黑指著旁邊的座椅示意讓我坐下。
坐了好一會兒,小黑才從工位上忙完轉過身來,“實在不好意思阿 Q,今天活太多,沒來得及招待你”
“剛忙什么呢,看你滿頭大汗的”,我問道。
“嗨,別提了,老是發現內存頁面錯誤,不停地要通知操作系統那邊去處理,真是懷念以前啊,沒有這么多破事兒要管”,小黑嘆了口氣。
我一聽來了興趣,“小黑你給我說說你們的工作唄,地址翻譯是怎么一回事兒,為什么懷念以前呢?”
小黑調整了下坐姿,咕嚕咕嚕喝了幾口水說道,“這話說來可就話長了”
接下來小黑開始給我講起了歷史故事......
8086
原來咱們的祖先叫 8086,小黑還給我看了他的照片:

那是一個純真質樸的年代,雖然工作性能不高,不過那個年代的程序都很簡單,我們的祖先一問世就成為了明星,稱得上那個時代的頂流了。
看到照片中的那些金屬針腳了嗎?那是我們 CPU 和外界打交道的觸角,每一根都有不同的作用。
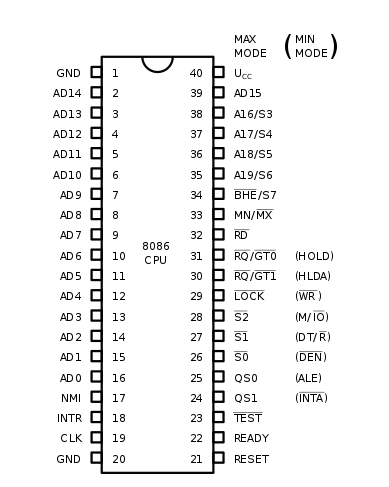
通過這些觸角,CPU 就可以跟內存打交道,獲取指令和數據,辛勤的干活啦。
那個年代,條件比較差,能湊合的就湊合,能共用的就共用。這不,你看祖先 CPU 的地址總線針腳和數據總線針腳就共用了。
祖先是一個 16 位的 CPU,數據(Data)總線就有 16 位,一次性可以傳輸 16 個比特位。和地址(Address)總線湊合著一起共用,于是就取名 AD0-AD15。
不過祖先的地址總線卻不止 16 個,還多出了 A16-A19 整整 4 個呢!這樣有 20 個地址線,可以尋址 1MB 的內存了!
但是祖先的寄存器都是 16 位的啊,只能存放 16 位的地址。不過他們很聰明,發明了一個叫分段式存儲管理的方法,把內存劃分為最大 64KB 的小塊,為什么是 64KB 呢,因為 16 位地址最多只能尋址這么大了。
然后又加了幾個叫做段寄存器的東西,指向這些塊的開頭,這樣,通過段地址+段內偏移地址的方式,就能訪問更多的內存了。
32 位時代
后來啊,祖先的那點計算能力越來越捉襟見肘,實在是跟不上時代了。家族中的年輕一代開始挑大梁,80286 和 80386CPU 相繼問世,尤其是 80386,成為了劃時代的存在。

到了 80386 時代,我們與外界通信的引腳就更多了,并且變成了 32 位的 CPU,那個時候,生活條件就變好了,地址線和數據線再也不用共享引腳了。
后來,人類變得越來越貪心,想要一邊聽音樂,一邊還要上網,同時還要編輯文檔,這就同時需要運行多個程序。
這個時候,有人發現了商機,開發了一個叫操作系統的東西,原來那些程序不再直接和我們 CPU 打交道了,而是和操作系統打交道,操作系統再和我們打交道,中間商賺差價說的就是他們!
操作系統這玩意兒很聰明啊,通過時間片劃分讓我們 CPU 來輪流執行多個程序,一會兒讓我們執行音樂播放,一會兒讓我們執行瀏覽器程序,一會兒又讓我們執行文檔編輯程序。
我們是無所謂啊,給什么代碼不是代碼啊,我們不挑,埋頭苦干就是了。人類的反應速度跟我們就差得遠了,他們還以為這些程序真的是同時執行的呢。
虛擬內存
不過隨之而來出現了一個大問題,這么多程序都要運行,大家擠在一個內存里,經常發生摩擦,沖突不斷。

先祖們為了此事殫精竭慮,終于想出了一個好辦法,一直沿用至今。
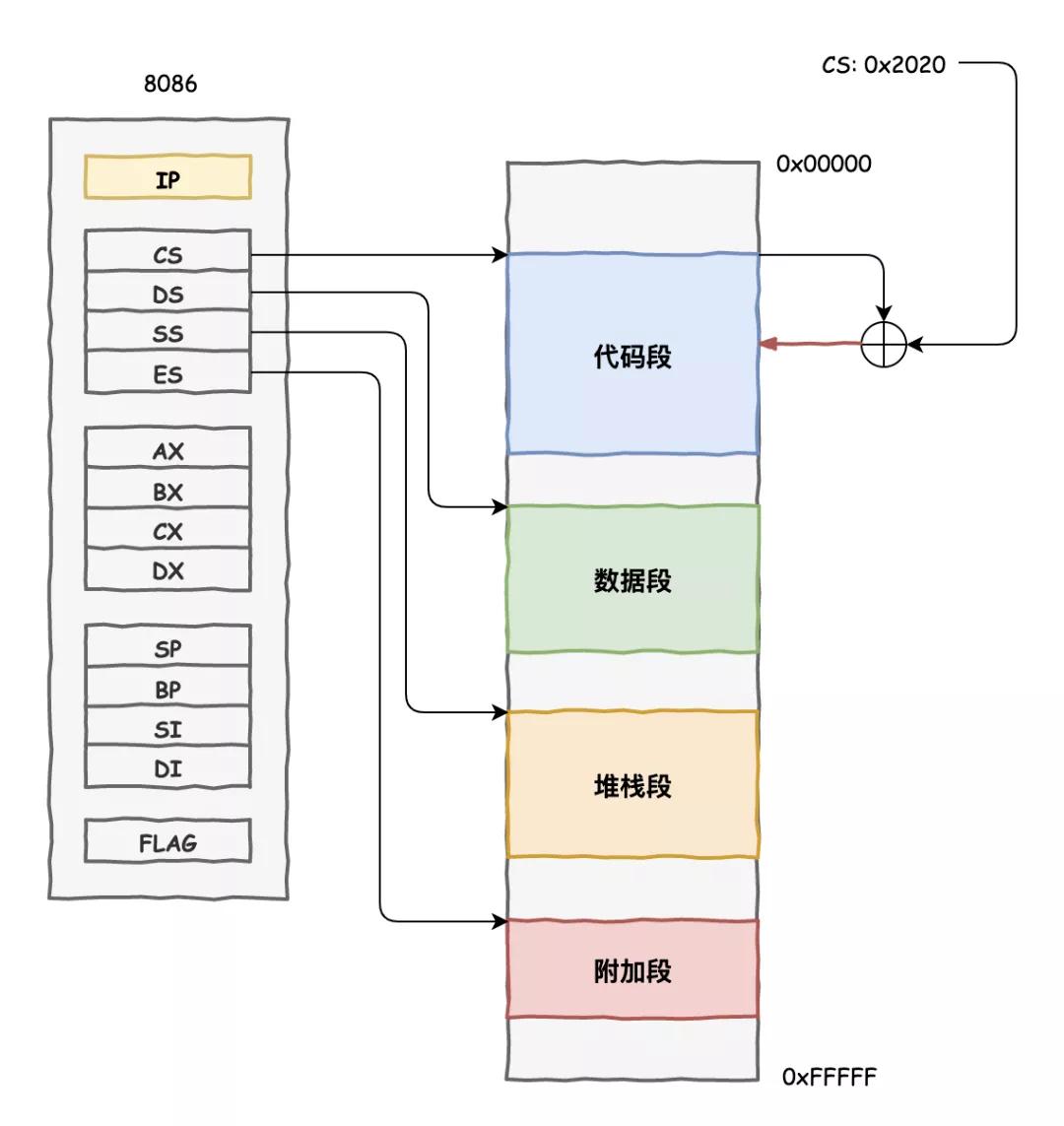
他們提出了一個虛擬地址的東西,所有程序使用的地址都是一個虛擬的地址,在真正和內存打交道的時候,咱們 CPU 內部工作人員再給翻譯成真實的內存地址,關于這事兒,內存那家伙一直被我們蒙在鼓里。
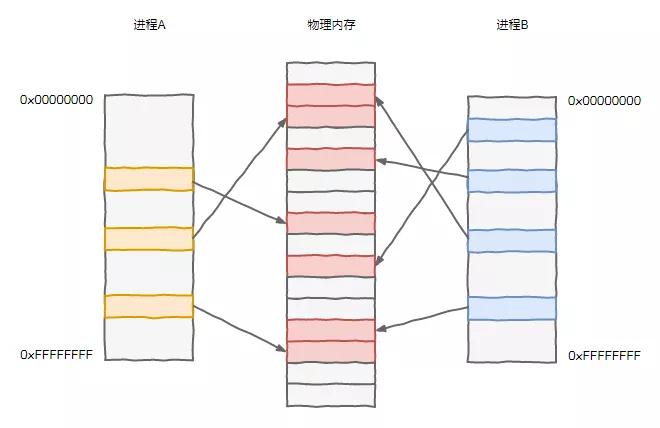
這樣一來,每個程序都可以用的是 0x00000000 到 0xffffffff 總共 4GB 這么大范圍的地址空間,當然不會真的給他們那么多空間,內存那家伙總共才 4GB 呢,而是要按需申請分配。
分配的單元是按照頁來進行的,32 位的 CPU 一個頁是 4KB。這些分配管理的累活就讓操作系統來干了,中間商不能光拿好處不干正事,至于我們 CPU,做好地址翻譯的工作就好了。
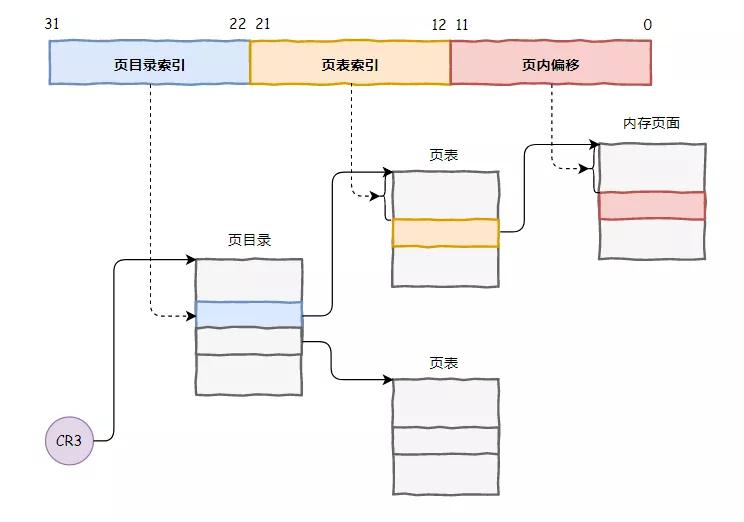
為此,在我們寄存器內部專門添置了一個新的寄存器 CR3,用來指向一個地址翻譯查詢字典,字典劃分了兩級目錄。
我們把一個 32 位的地址劃分了 3 部分,前面兩部分分別指向兩級目錄中的條目,用來定位這個地址在物理內存的哪個頁面,最后一部分就是指向物理內存頁面的偏移,這樣就完成了地址的翻譯工作。
每個進程有不同的地址空間,切換進程的時候,把 CR3 的內容換一下就使用新進程的翻譯字典,特別的方便。
我們把這種內存管理方式叫做分頁式內存管理。
真佩服先祖們的智慧,這樣巧妙的把各個程序隔離開來,后來我們把這種工作模式叫做保護模式,把之前那種直接使用真實內存地址的工作模式叫做實地址模式。
分頁交換
人類變得越來越貪婪,程序變得越來越多,對內存的需求也越來越大。隨著這些程序都不斷申請內存頁面,內存空間很快就要耗盡了。
我們看在眼里,急在心里,后來找操作系統協商,看看這問題該怎么辦。
操作系統那家伙也不賴,想出了一個好辦法。內存的大小有限,但是硬盤給力啊,硬盤空間大的多,去硬盤上劃一塊區域來,把內存里長時間沒有用到的頁面給換到這塊區域里去,然后做個標記。
如果后面誰要訪問那個頁面,咱們 CPU 就檢查如果有這個標記,就發送一個頁錯誤的中斷信號告訴操作系統去把這個頁面換回來。
通過我們之間的配合,解決了內存緊張的危機。后來我們把這個技術叫做內存分頁交換。
現在
時間過得很快,到了我們這一輩,內存變得更大了,16GB 都是小 case,32GB 也很常見。
除了內存,我們 CPU 本身也更先進了,別的不說,你光看看咱們現在的引腳數那比先祖們那幾輩就不可同日而語。

我們不僅從 32 位變成了 64 位,還從單核變成了多核,像我所在的 CPU 就有 8 個車間,8 核并行執行,比起先祖那個年代簡直有云泥之別。
04.就為了一個原子操作 其他 CPU 核心罷工了
和小黑閑談間,我們車間的老 K 突然出現在了門口。
“阿 Q 原來你在這里,讓我好找,趕快回去吧,隔壁二號車間的虎子說我們改了他們的數據,上門來鬧事了······”
i++ 問題
由于老 K 的突然出現,我不得不提前結束與小黑的交流,趕回了 CPU 一號車間。
見到我回來,虎子立刻朝我嚷嚷:“你們是怎么回事?才幾納秒的時間,就把數據給我改了,你說這事怎么辦吧!”
我聽著迷迷糊糊的,連連說到:“虎子你先別急,我剛回來,到底出什么事兒了,先讓我了解清楚好不好?”
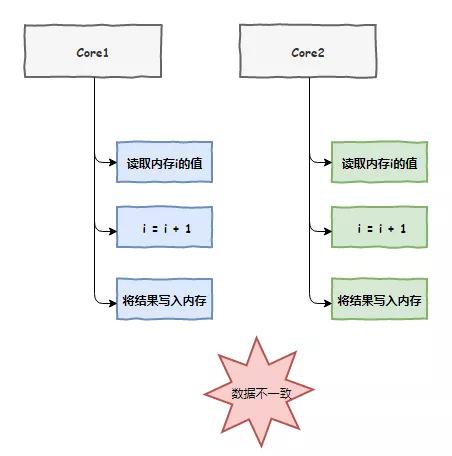
接下來,老 K 把事情的經過告訴了我。原來,我們兩個 CPU 車間各自負責的線程都在執行一個 i++ 的操作,我們都把i的值放到了自己的緩存中,完了之后都沒有通知對方,加了兩次但結果卻只有一次,出現了數據不一致問題。
原子操作
了解清楚事情的原委之后,我向虎子說道:“大家都執行一樣的代碼,這事兒也不能怪我們啊”
虎子一聽急了,“怎么不怪你們了,我們比你們先一步找內存拿走了i,那你們得等我們加完之后再用啊,不信你可以打電話問內存那家伙,看看是不是我們二號車間先來的”
“好好好,你先冷靜一下,你看我們又不知道你們先去拿了,這不情有可原嗎,再說現在事情已經出了,我們應該一起坐下來想個辦法避免以后再次出現這種問題,你說是不是?”
虎子嘆了口氣問道:“那你說說你有什么辦法?”
我繼續說道:“你看啊,像咱們在執行i++這種操作的時候就不應該被干擾”
“不被干擾?”
“對,比如虎子你們二號車間在訪問i的時候,我們一號車間就不能訪問,需要等著,等你們訪問完成我們再來,非常簡單的辦法卻很有用”
虎子聽完一愣,“這不就是加鎖嗎?你是想怪程序員做 i++ 前沒有加鎖?”
“的確是加鎖,不過這種簡單操作還要程序員來加鎖那也太麻煩了,咱們 CPU 內部處理好就行了”
“內部處理,你打算怎么實現?”,虎子問到。
“這,,讓我想想···”,虎子問到了具體實現,我倒還沒想到這一步。
這時,一旁的老 K 站了出來:“我倒是有個辦法,可以找總線主任啊,他是負責協調各個車間使用系統總線訪問內存的總指揮,讓他在中間協調一下應該不難”
老 K 一語點醒夢中人,接著我們就去找了總線主任,后來我們商量出了一套解決方案:我們定義了一個叫原子操作的東西,表示這是一個不可切分的動作,誰要執行原子操作,總線主任就在系統總線上加上一個 LOCK# 信號,其他車間的想去訪問內存就得等著,直到原子操作指令執行完畢。
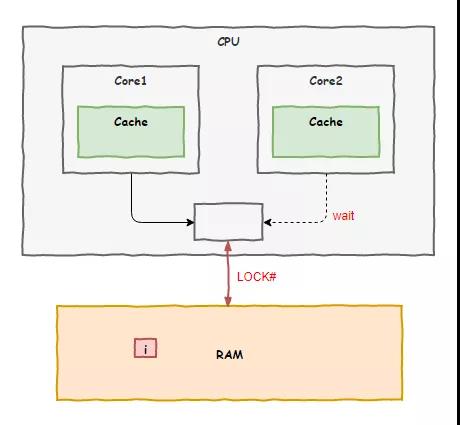
我們把這套方案上報了領導,很快就批下來了,后面我們 8 個車間都按照這套方案來工作,以后程序員們把 i++ 這樣的動作換成原子操作后,問題就能迎刃而解。
不過施行了一段時間之后,各個車間卻開始大倒苦水:就因為某個車間要執行一個原子操作,就讓總線主任把系統總線鎖住,其他車間的人都沒法訪問內存,都干不了活了,嚴重影響工作效率。
抱怨歸抱怨,在沒有更好的替代方案出現之前,日子還得過下去。
緩存引發的問題
不過,沒過多久,數據不一致問題又一次出現了。
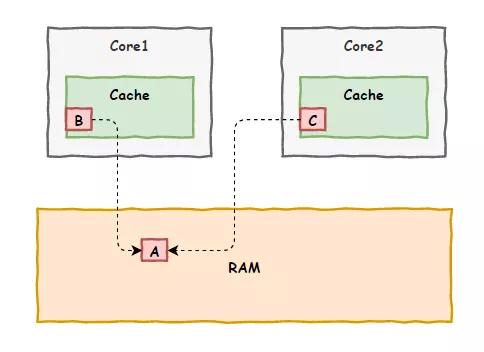
這一次,倒不是加法的問題,我們兩車間還是因為各自緩存的原因,先后修改了變量的值,對方沒有即時知道,誤用了錯誤的值,以致釀成大錯。
“阿 Q,上次那辦法好是好,可解決不了這一次的問題啊”,虎子再次找上門來。
“你來的正好,我正想去找你說這事呢”
“哦,是嗎,難不成你想到破解之道了?”
“只是一些初步的想法,問題的核心在于現在咱們各個車間各自為政,都有自己的私有緩存,各自修改數據后向內存更新時也不互相打招呼,缺少一個聯絡機制”
虎子點了點頭,“確實,所以咱們需要建立一個聯絡機制,來對各個車間的緩存內容進行統一管理是嗎?”
“對!這事兒咱倆說了可不算,我建議召集 8 個核心車間的代表,統一開一個會議,詳細討論下這個問題。哦,對了,把總線主任也叫上,他經驗豐富說不定能提供一些思路”
緩存一致性協議 MESI
很快,咱們 CPU 的 8 個核心車間就為此問題召開了會議,并且取得了非常重要的成果。
我們牽了一條新的專線,把 8 個核心車間連接起來,用于各個車間之間進行信息溝通,不同于 CPU 外部的總線系統,大家把這個叫片內總線。
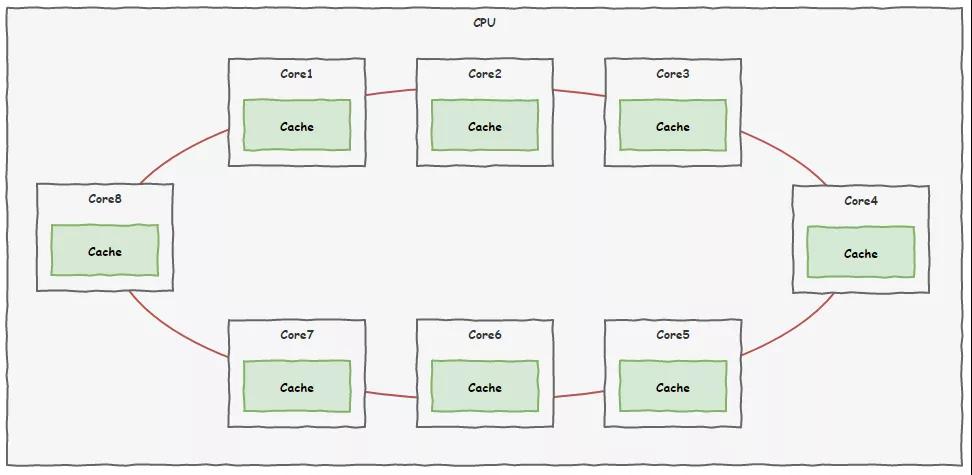
新的線路鋪設好了,以后大家就可以通過這條線路即時溝通,為了解決之前出現的問題,大家還制定了一套規則,叫做緩存一致性協議。
規則里面規定了所有車間的緩存單元——緩存行有四種狀態:
已修改 Modified (M):緩存行已經被修改了,與內存的值不一樣。如果別的 CPU 內核要讀內存這塊數據,要趕在這之前把該緩存行回寫到主存,把狀態變為共享 (S)。
獨占 Exclusive (E):緩存行只在當前 CPU 核心緩存中,而且和內存中數據一樣。
當別的 CPU 核心讀取它時,狀態變為共享;如果當前 CPU 核心修改了它,就要變為已修改狀態。
共享 Shared (S):緩存行存在于多個 CP U核心的緩存中,而且和內存中的內容一致。
無效 Invalid (I):緩存行是無效的。
四種狀態之間的轉換是這樣的:
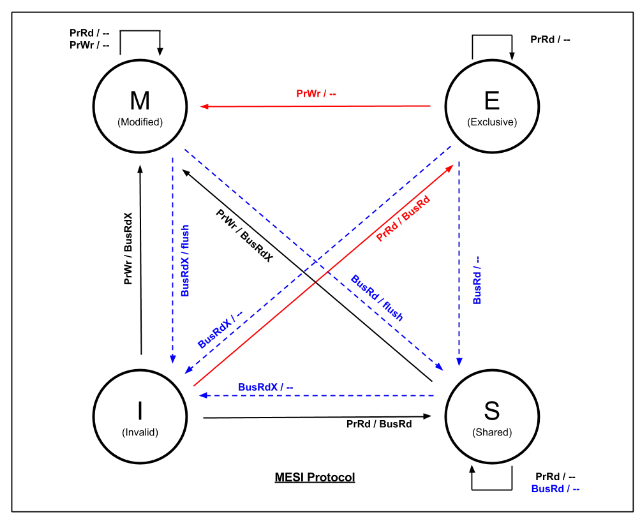
按照這套規則,大家不能再像以前那樣隨意了,各車間對自家緩存進行讀寫時,都要相互通一下氣,避免使用過時的數據。
除此之外,還規定如果一塊內存區域被多個車間都緩存,就不再允許多個車間同時去修改緩存了。
會議還有另外一個收獲,以前被各車間詬病的每次原子操作都要鎖定總線,導致大家需要訪問內存的都只能干等著的問題也得到了解決。以后總線主任不再需要鎖定總線了,通過這次的緩存一致性協議就可以辦到。
自此以后,數據不一致的問題總算是根治了,咱們 8 個車間又可以愉快的工作了。
作者:軒轅之風
編輯:陶家龍
出處:轉載自微信公眾號編程技術宇宙(ID:ProgramUniverse)














