













了解AI背后的引擎,4個技術愛好者應該知道的機器學習算法
人工智能正在做不可思議的事情-駕駛汽車,調酒,打仗-但是,盡管機器人面具受到了沉重的關注和關注,但任何真正的技術愛好者都知道基本的機器學習算法,這些算法可以移動并控制可實現驚人成就的機器人技術。

有四種主要的機器學習算法-決策樹,隨機森林,支持向量機和神經網絡-在最近的AI開發中常用。 機器人技術背后的算法甚至比機器本身重要得多,更不用說機器學習的非物理應用了。
機器學習基礎
機器學習由多個領域組成,其中與人工智能應用最相關的一個領域是監督學習。 在機器學習的這一部分中,算法被賦予x并被告知預測y。 在自動駕駛汽車的應用中,x可能是當前汽車前方的圖像。 我們將假定圖像像素為700像素寬,400像素長,它們將形成700 * 400 = 280,000尺寸的x。
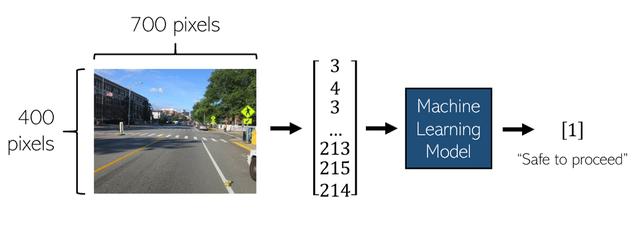
在上面的示例中,前方道路的圖像被轉換為長度為280,000的矢量,然后將其輸入經過訓練的機器學習模型中。 在這種情況下,模型可能會輸出1表示"行進安全"(如果認為道路行進不安全,則輸出0)。 自動駕駛汽車中圖像識別的其他領域包括深度感知(識別物體有多遠)或讀取限速標志。 除了圖像分類之外,機器學習的其他應用程序還包括確定計算一個人過街的速度或確定前方汽車向右轉的可能性。
在文本實例中,文本被矢量化或轉換為數字數組。 文本可以被分類,例如在真實/偽造新聞中,或用于生成(創建唯一文本)。
機器學習算法輸入和輸出的所有內容都是純數字的,因此每種算法本質上都是數學的。 機器學習算法只需執行一組數學過程即可將多維x數據轉換為(通常)奇異的y值。 監督學習的主要子類是分類和回歸。 前者致力于將x劃分為一組離散的類別(例如,圖像是貓還是狗),而后者則致力于以連續的比例分配xay(例如,基于諸如臥室數量等屬性的房價) 。
數據的每個維度也稱為要素。 在圖像的情況下,每個像素都是一個特征,或者在預測房價的示例中,每個房屋屬性(例如,臥室,浴室的數量,是否有水濱等)都是一個特征。
決策樹
決策樹算法基于以下簡單思想:遵循一組是/否問題以得出最終結論。 例如,一個例子是問一個朋友接下來要嘗試哪種食物。 您的朋友可能會根據他們的經驗問您一系列"是/否"問題,以確定您應該嘗試哪種食物。 示例樹可能如下所示:
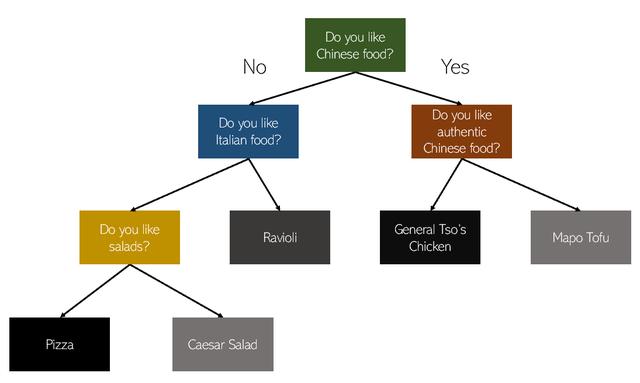
根據您對朋友問題的是/否回答,您的朋友沿著樹下的路徑到達終點。 對于真實數據集,決策樹可能深達數十層。 決策樹在分類方面非常強大。 在數據集中,算法嘗試通過將最有區別的特征放在頂部來構造樹。 最具特色的功能是提供最多信息的最佳功能。
一個功能的"好"程度可以通過其信息增益來衡量,也可以通過僅基于該功能將數據分為兩類來提供多少信息。
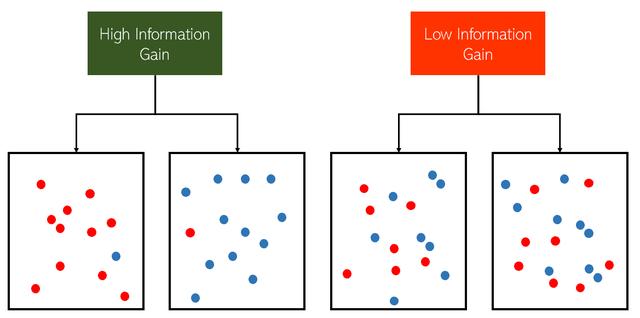
決策樹的各層在頂部添加了最多的信息獲取功能,在底部添加了最少的信息獲取功能。 在實際數據集中,決策樹仍會構造是/否問題,但可以用許多方式來表達它們,例如:
- 浴室數量是否大于或等于3?
- 房子在水邊嗎?
決策樹算法還可以通過較小的方式用于回歸,也可以提供概率置信度(基于獲得的信息量)。 決策樹可以通過復雜的數據結構選擇方法,但也可以解釋。 決策樹可用于診斷癌癥,阿爾茨海默氏癥或相關的醫療狀況。 他們能夠捕捉人類醫生永遠無法完成的復雜性和深度。
隨機森林
決策樹可以使用隨機森林算法進行改進。 決策樹的問題在于,由于它們試圖最大程度地獲取信息,因此很容易過度擬合。 此時,模型變得非常擅長對數據進行分類,以致于無法在將要使用的新數據上很好地表現數據。 這類似于孩子記住對問題的確切措詞的確切答案,但不能回答具有不同措辭的問題。
在機器學習中,決策樹被認為是高偏置算法。 就像您的朋友推薦嘗試食物的類比,僅一個朋友一個人就會使您有偏頗的選擇。 隨機森林通過在"森林"中包含多個決策樹模型來擴展決策樹算法。
類似于一個朋友推薦食物的例子,想象一下問十個不同的朋友來指導您完成相同的是/否問題解答過程。 由于每個朋友都有不同的口味和經驗,因此他們會提出不同的問題,并得出自己應該嘗試哪種食物的結論。 最后,您選擇十個朋友中大多數同意您應點的食物。 這樣可以做出更全面的決策,而不僅僅是基于一個朋友,而是從許多人的全球角度出發。
隨機森林算法包括許多決策樹。 每個人都接受數據的不同子集的訓練,這些子集都是隨機選擇的。 每個模型都在不同的數據子集上進行訓練,類似于具有不同的體驗和品味。 在每個子集上構建決策樹之后,隨機森林模型會匯總其投票以得出最終決策。
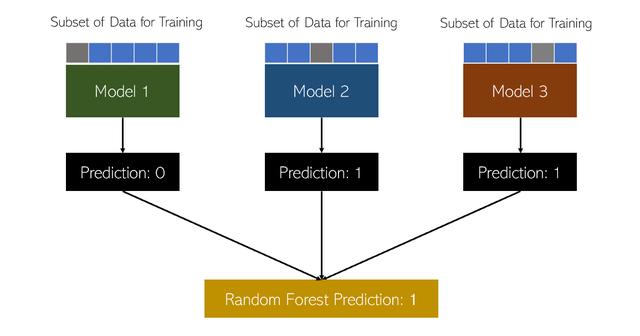
隨機森林模型可以執行決策樹算法可以完成的相同任務。 其優點在于,它可以提供更平衡的透視圖,但訓練起來的計算量也更大。 在某些情況下,隨機森林甚至可能比決策樹更差。 無論如何,決策樹和隨機森林都是非常強大的分類算法,在AI中有許多應用。
支持向量機(SVM)
支持向量機(SVM)算法是機器學習中用于二進制分類(將數據點分為兩類之一)的一種常用且功能強大的算法。 SVM算法構造一條線,將數據分為兩類,如下所示。
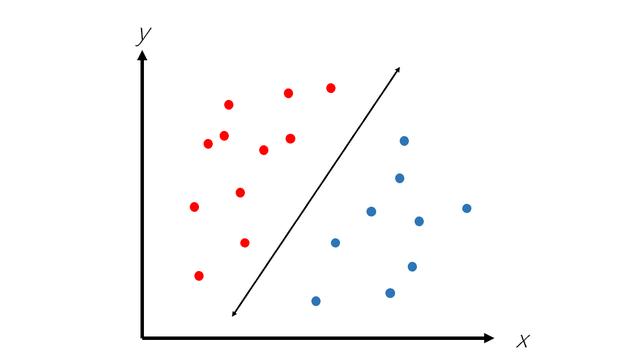
但是,SVM的前提是數據是線性可分離的,這意味著可以將它們放在帶有直線(或超平面)的兩個不同類別中。 然而,這并非總是如此:
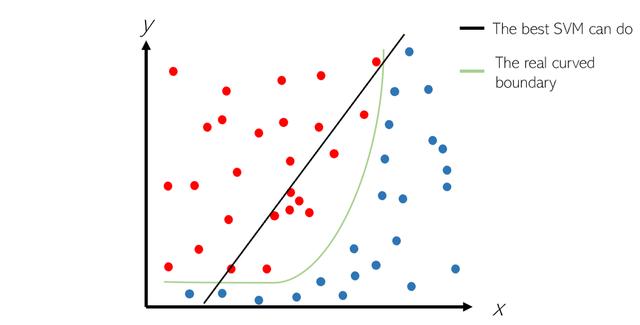
在這種情況下,純線性SVM分隔符無法容納真實的彎曲邊界。 因此,為了解決皮膚問題,SVM應用了各種內核函數以在可線性分離的邊界之間拉直數據。 盡管這是一個簡化,但這是內核技巧的主要思想。 例如,考慮指數邊界,并且應用對數對拉直的效果。
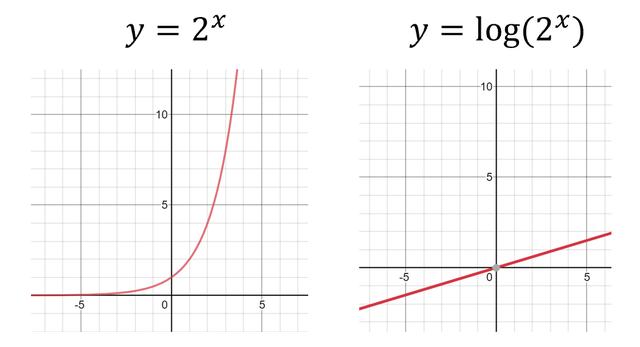
還將訓練適用于數據的哪些函數,包括但不限于多項式,S形,高斯函數以及這些函數的任意組合,以提供最容易線性分離的數據。 在高維數據中,無論數據的結構如何,SVM都可以很好地運行。
支持向量機有時被用作低維圖像分類的一種低計算成本的方法,該模式易于識別,因此支持向量機可以正確地對其進行分類,但不能保證復雜數據關系的常用算法即神經網絡。
神經網絡
神經網絡是機器學習中最強大的算法家族。 但是,數學上已經證明,沒有"通用"算法可以在所有數據集上發揮最佳性能,因此,不應將神經網絡用作對任何數據集的切刀解決方案。 最重要的是,它們的培訓成本可能很高,因此應謹慎使用。
就是說,神經網絡是最先進的AI應用程序中使用最廣泛的算法。 它們在大腦中模擬神經元及其之間的聯系。 在神經網絡中,存在三種類型的層:
- 輸入圖層,用于接收信息。 輸入層中神經元的數量與輸入(X)的維數相對應。 例如,如果圖像數據集為28 x 28像素,則輸入層將具有28 x 28 = 784個神經元。
- 輸出層,輸出神經網絡的決策。 輸出層中神經元的數量與輸出的維數(y)相對應。 例如,一個旨在將新聞分類為真實(1)或偽造(0)的數據集將只有一個輸出神經元。
- 隱藏層,它們連接輸入層和輸出層。 隱藏層為神經網絡增加了更多的復雜性和信息。 通常,隱藏層越多,神經網絡可以執行的功能越復雜和"智能"。
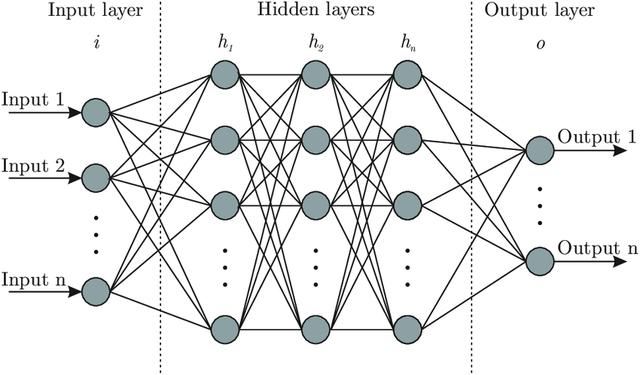
每個神經元就像一個小型計算器-信息經過傳遞,轉換,然后傳遞到下一層。 神經元具有輸入要通過的激活函數,該函數將輸入簡單地轉換為更好地幫助神經網絡理解和處理信息的格式。
神經元之間的每個連接也具有權重。 信息通過連接傳遞時,將乘以權重。
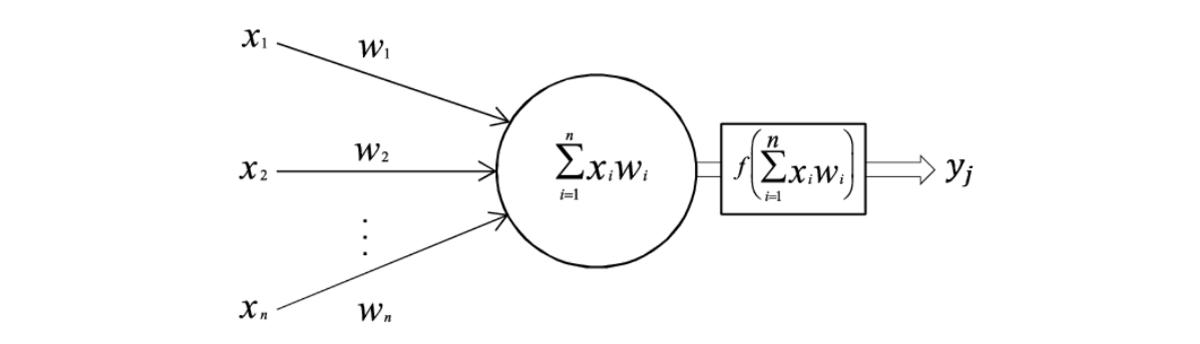
每個神經元都會執行少量計算,將它們與權重鏈接在一起時,現代神經網絡便會在龐大的規模上運行-數十個隱藏層,每層數百個神經元以及數百萬個參數(權重),它們可以生成文本, 讀取圖像并執行其他"智能"操作。
神經網絡的反向傳播算法可調整權重。 在神經網絡中,調整神經網絡之間的權重。 如果網絡足夠大,可能要花費數小時甚至數天的時間來訓練幾千萬個砝碼中的每一個。
神經網絡和深度學習一直是最新技術發展背后的算法,其中包括AlphaGo擊敗世界圍棋冠軍,創造逼真的藝術品并產生音樂。
現在您了解了AI的引擎。
謝謝閱讀! 如果您對AI中的這四種算法或機器學習有任何疑問或澄清,請隨時做出回應。














