用PyTorch實現一個簡單的分類器
回想了一下自己關于 pytorch 的學習路線,一開始找的各種資料,寫下來都能跑,但是卻沒有給自己體會到學習的過程。有的教程一上來就是寫一個 cnn,雖然其實內容很簡單,但是直接上手容易讓人找不到重點,學的云里霧里。有的教程又淺嘗輒止,師傅領到了門檻跟前,總感覺自己還沒有進門,教程就結束了。
所以我總結了一下自己當初學習的路線,準備繼續深入鞏固自己的 pytorch 基礎;另一方面,也想從頭整理一個教程,從沒有接觸過 pytorch 開始,到完成一些最新論文里面的工作。以自己的學習筆記整理為主線,大家可以針對參考。
第一篇筆記,我們先完成一個簡單的分類器。主要流程分為以下三個部分:
1,自定義生成一個訓練集,具體為在二維平面上的一些點,分為兩類;
2,構建一個淺層神經網絡,實現對特征的擬合,主要是明白在 pytorch 中網絡結構如何搭建;
3,完成訓練和測試部分的工作,熟悉 pytorch 如何對網絡進行訓練和測試。
1. 自定義生成數據集
- n_data = torch.ones(100, 2)
- x0 = torch.normal(2*n_data, 1)
- y0 = torch.zeros(100)
- x1 = torch.normal(-2*n_data, 1)
- y1 = torch.ones(100)
- x = torch.cat((x0, x1)).type(torch.FloatTensor)
- y = torch.cat((y0, y1)).type(torch.LongTensor)
這篇文章我們先考慮在一個自己定義的簡單數據集上實現分類,這樣子可以最簡單的了解一個神經網絡的模型,如何用 pytorch 搭建起來。
這個代碼對 numpy 比較熟悉的同學應該也可以猜出來它的內容,只是在 numpy 中是一個 numpy array,在 pytorch 中是一個 tensor。這里我簡單的介紹一下這幾行代碼的作用,給有需要的同學捋順思路。
首先 n_data 是基準數據,用來生成其它數據,內容為一個 100 行 2 列 的 tensor,其中的值都為 1。x0 是一類數據的坐標值,通過這個 n_data 來生成。
具體的生成的辦法是用 torch.normal() 這個函數,第一個參數為 mean,第二個參數是 std。所以返回的結果 x0 是一個和 n_data 形狀一樣,但是其中的數據在以 2 為平均值,以 1 為標準差的正態分布中隨機選取的。y0 則是一個 100 維的 tensor,其中的值都為 0。
我們可以這樣理解 x0 和 y0,x0 的形狀是 100 行 2 列的 tensor,其中的值以 2 為中心進行隨機分布,符合正態分布,而這些點的標簽我們設置為 y0,也就是 0。與此相反,x1 對應的中心為 -2,且標簽為 y1,也就是每個點的標簽都為 1。
最后生成的 x 和 y,就是將所有的數據合并起來,x0 和 x1 合并起來作為數據,y0 和 y1 合并起來作為標簽。
2. 構建一個淺層神經網絡
- class Net(torch.nn.Module):
- def __init__(self, n_feature, n_hidden, n_output):
- super(Net, self).__init__()
- self.n_hidden = torch.nn.Linear(n_feature, n_hidden)
- self.out = torch.nn.Linear(n_hidden, n_output)
- def forward(self, x_layer):
- x_layer = torch.relu(self.n_hidden(x_layer))
- x_layer = self.out(x_layer)
- x_layer = torch.nn.functional.softmax(x_layer)
- return x_layer
- net = Net(n_feature=2, n_hidden=10, n_output=2)
- # print(net)
- optimizer = torch.optim.SGD(net.parameters(), lr=0.02)
- loss_func = torch.nn.CrossEntropyLoss()
上面的 Net() 類就是如何構建一個神經網絡的步驟。我們如果是第一次用 pytorch 寫一個神經網絡,那么這個就是一個足夠簡單的例子了。其中的內容由兩部分組成,分別是 __init__() 函數和 forward() 函數。
大家可以簡單的這樣子理解:__init__() 函數中,是對網絡結構的定義,都有哪些層,每層又有什么功能。例如這個函數中,self.n_hidden 就是定義了一個線性擬合函數,也就是全連接層,在此處相當于一個向隱藏層的映射。輸入是 n_feature,輸出是隱藏層的神經元個數 n_hidden。然后 self.out 也一樣是一個全連接層,輸入是剛才的隱藏層的神經元個數 n_hidden,輸出是最后的輸出結果 n_output。
接著就是 forward() 函數,在這里相當于定義我們神經網絡的執行順序。所以這里可以看到,先對輸入的 x_layer 執行上面的隱藏層函數,也就是第一個全連接 self.n_hidden(),然后對輸出再執行激活函數 relu。接下來如法炮制,經過一個輸出層 self.out(),得到最后的輸出。然后將輸出 x_layer 返回。
optimizer 就是這里定義的優化方式,其中的 lr 是學習率的參數。然后損失函數我們選擇交叉熵損失函數,也就是上面的最后一行代碼。優化算法和損失函數,可以在 pytorch 中直接選擇不同的 api 接口,形式上直接參考上面這種固定形式便可。
3. 完成訓練和測試
- for i in range(100):
- out = net(x)
- # print(out.shape, y.shape)
- loss = loss_func(out, y)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
接下來我們看一下如何進行訓練的過程。net() 是我們對 Net() 類實例化出來的一個對象,所以利用 net() 可以直接完成模型的運行,out 就是模型預測出來的結果,loss 則是和真實值按照交叉熵損失函數計算出來的誤差。
下面的三行代碼是一個標準形式,表示了如何進行梯度的反向傳播。到此其實我們的訓練已經完成了,這個網絡現在可以直接拿來對測試的數據集進行預測分類了。
- # train result
- train_result = net(x)
- # print(train_result.shape)
- train_predict = torch.max(train_result, 1)[1]
- plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=train_predict.data.numpy(), s=100, lw=0, cmap='RdYlGn')
- plt.show()
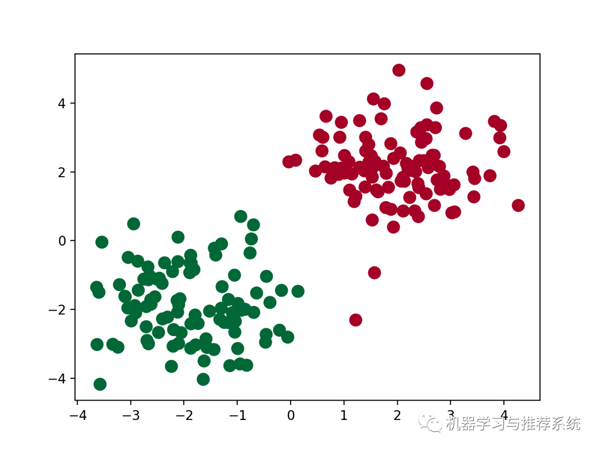
為了讓大家更好的理解這個模型的作用,這里我們來做一些可視化的工作,看看一個模型的學習效果。通過 python 很常見的一個數據可視化的庫 matplotlib 可以實現這個目標,具體的 matplotlib 的用法就不介紹了。
這里的作用是顯示出來訓練好的模型對訓練集的分類效果,可以理解為訓練誤差。
- # test
- t_data = torch.zeros(100, 2)
- test_data = torch.normal(t_data, 5)
- test_result = net(test_data)
- prediction = torch.max(test_result, 1)[1]
- plt.scatter(test_data[:, 0], test_data[:, 1], s=100, c=prediction.data.numpy(), lw=0, cmap='RdYlGn')
- plt.show()
然后我們以 0 為 mean,隨機生成一些數據,來看看模型會怎么去分類這些數據點。
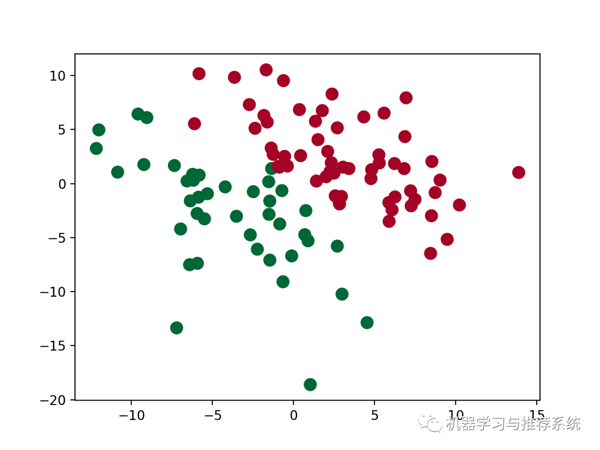
雖然沒有畫出來那條訓練好的分割線,但是我們也可以看到模型學習了一個分割的界面,來將數據劃分為兩類。