













技術(shù)總監(jiān)夸我“索引”用的溜,我飄了......
生產(chǎn)上為了高效地查詢數(shù)據(jù)庫(kù)中的數(shù)據(jù),我們常常會(huì)給表中的字段添加索引,大家是否有考慮過(guò)如何添加索引才能使索引更高效。
圖片來(lái)自 Pexels
添加的索引是越多越好嗎?為啥有時(shí)候明明添加了索引卻不生效?索引有哪些類型?如何評(píng)判一個(gè)索引設(shè)計(jì)的好壞?看了本文相信你會(huì)對(duì)索引的原理有更清晰的認(rèn)識(shí)。
本文將會(huì)從以下幾個(gè)方面來(lái)講述索引的相關(guān)知識(shí):
- 什么是索引,索引的作用
- 索引的種類
- 高性能索引策略
- 索引設(shè)計(jì)準(zhǔn)則:三星索引
什么是索引,索引的作用
當(dāng)我們要在新華字典里查某個(gè)字(如「先」)具體含義的時(shí)候,通常都會(huì)拿起一本新華字典來(lái)查。
你可以先從頭到尾查詢每一頁(yè)是否有「先」這個(gè)字,這樣做(對(duì)應(yīng)數(shù)據(jù)庫(kù)中的全表掃描)確實(shí)能找到,但效率無(wú)疑是非常低下的。
更高效的方相信大家也都知道,就是在首頁(yè)的索引里先查找「先」對(duì)應(yīng)的頁(yè)數(shù),然后直接跳到相應(yīng)的頁(yè)面查找,這樣查詢時(shí)候大大減少了,可以為是 O(1)。
數(shù)據(jù)庫(kù)中的索引也是類似的,通過(guò)索引定位到要讀取的頁(yè),大大減少了需要掃描的行數(shù),能極大的提升效率。
簡(jiǎn)而言之,索引主要有以下幾個(gè)作用:
- 即上述所說(shuō),索引能極大地減少掃描行數(shù)
- 索引可以幫助服務(wù)器避免排序和臨時(shí)表
- 索引可以將隨機(jī) IO 變成順序 IO
第一點(diǎn)上文已經(jīng)解釋了,我們來(lái)看下第二點(diǎn)和第三點(diǎn),先來(lái)看第二點(diǎn),假設(shè)我們不用索引,試想運(yùn)行如下語(yǔ)句:
- SELECT * FROM user order by age desc;
則 MySQL 的流程是這樣的,掃描所有行,把所有行加載到內(nèi)存后,再按 age 排序生成一張臨時(shí)表,再把這表排序后將相應(yīng)行返回給客戶端。
更糟的,如果這張臨時(shí)表的大小大于 tmp_table_size 的值(默認(rèn)為 16 M),內(nèi)存臨時(shí)表會(huì)轉(zhuǎn)為磁盤(pán)臨時(shí)表,性能會(huì)更差,如果加了索引,索引本身是有序的。
所以從磁盤(pán)讀的行數(shù)本身就是按 age 排序好的,也就不會(huì)生成臨時(shí)表,就不用再額外排序 ,無(wú)疑提升了性能。
再來(lái)看隨機(jī) IO 和順序 IO。先來(lái)解釋下這兩個(gè)概念。
相信不少人應(yīng)該吃過(guò)旋轉(zhuǎn)火鍋,服務(wù)員把一盤(pán)盤(pán)的菜放在旋轉(zhuǎn)傳輸帶上,然后等到這些菜轉(zhuǎn)到我們面前,我們就可以拿到菜了。
假設(shè)裝一圈需要 4 分鐘,則最短等待時(shí)間是 0(即菜就在你跟前),最長(zhǎng)等待時(shí)間是 4 分鐘(菜剛好在你跟前錯(cuò)過(guò)),那么平均等待時(shí)間即為 2 分鐘。
假設(shè)我們現(xiàn)在要拿四盤(pán)菜,這四盤(pán)菜隨機(jī)分配在傳輸帶上,則可知拿到這四盤(pán)菜的平均等待時(shí)間是 8 分鐘(隨機(jī) IO),如果這四盤(pán)菜剛好緊鄰著排在一起,則等待時(shí)間只需 2 分鐘(順序 IO)。
上述中傳輸帶就類比磁道,磁道上的菜就類比扇區(qū)(sector)中的信息,磁盤(pán)塊(block)是由多個(gè)相鄰的扇區(qū)組成的,是操作系統(tǒng)讀取的最小單元。
這樣如果信息能以 block 的形式聚集在一起,就能極大減少磁盤(pán) IO 時(shí)間,這就是順序 IO 帶來(lái)的性能提升,下文中我們將會(huì)看到 B+ 樹(shù)索引就起到這樣的作用。
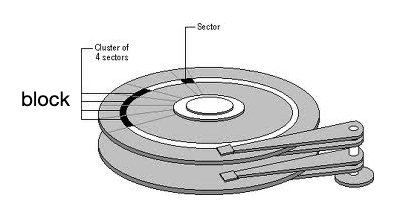
如圖示:多個(gè)扇區(qū)組成了一個(gè) block,如果要讀的信息都在這個(gè) block 中,則只需一次 IO 讀。
而如果信息在一個(gè)磁道中分散地分布在各個(gè)扇區(qū)中,或者分布在不同磁道的扇區(qū)上(尋道時(shí)間是隨機(jī)IO主要瓶頸所在),將會(huì)造成隨機(jī) IO,影響性能。
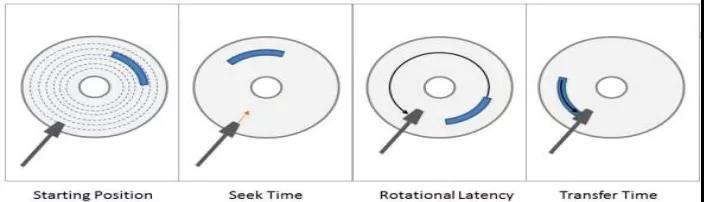
我們來(lái)看一下一個(gè)隨機(jī) IO 的時(shí)間分布:
- seek Time:尋道時(shí)間,磁頭移動(dòng)到扇區(qū)所在的磁道。
- Rotational Latency:完成步驟 1 后,磁頭移動(dòng)到同一磁道扇區(qū)對(duì)應(yīng)的位置所需求時(shí)間。
- Transfer Time:從磁盤(pán)讀取信息傳入內(nèi)存時(shí)間。
這其中尋道時(shí)間占據(jù)了絕大多數(shù)的時(shí)間(大概占據(jù)隨機(jī) IO 時(shí)間的占 40%)。
隨機(jī) IO 和順序 IO 大概相差百倍 (隨機(jī) IO:10 ms/ page, 順序 IO 0.1ms / page),可見(jiàn)順序 IO 性能之高,索引帶來(lái)的性能提升顯而易見(jiàn)!
索引的種類
索引主要分為以下幾類:
- B+樹(shù)索引
- 哈希索引
①B+ 樹(shù)索引

B+ 樹(shù)是以 N 叉樹(shù)的形式存在的,這樣有效降低了樹(shù)的高度,查找數(shù)據(jù)也不需要全表掃描了。
順著根節(jié)點(diǎn)層層往下查找能很快地找到我們的目標(biāo)數(shù)據(jù),每個(gè)節(jié)點(diǎn)的大小即一個(gè)磁盤(pán)塊的大小,一次 IO 會(huì)將一個(gè)頁(yè)(每頁(yè)包含多個(gè)磁盤(pán)塊)的數(shù)據(jù)都讀入(即磁盤(pán)預(yù)讀。
程序局部性原理:讀到了某個(gè)值,很大可能這個(gè)值周圍的數(shù)據(jù)也會(huì)被用到,干脆一起讀入內(nèi)存),葉子節(jié)點(diǎn)通過(guò)指針的相互指向連接,能有效減少順序遍歷時(shí)的隨機(jī) IO。
而且我們也可以看到,葉子節(jié)點(diǎn)都是按索引的順序排序好的,這也意味著根據(jù)索引查找或排序都是排序好了的,不會(huì)再在內(nèi)存中形成臨時(shí)表。
②哈希索引
哈希索引基本散列表實(shí)現(xiàn),散列表(也稱哈希表)是根據(jù)關(guān)鍵碼值(Key value)而直接進(jìn)行訪問(wèn)的數(shù)據(jù)結(jié)構(gòu),它讓碼值經(jīng)過(guò)哈希函數(shù)的轉(zhuǎn)換映射到散列表對(duì)應(yīng)的位置上,查找效率非常高。
假設(shè)我們對(duì)名字建立了哈希索引,則查找過(guò)程如下圖所示:
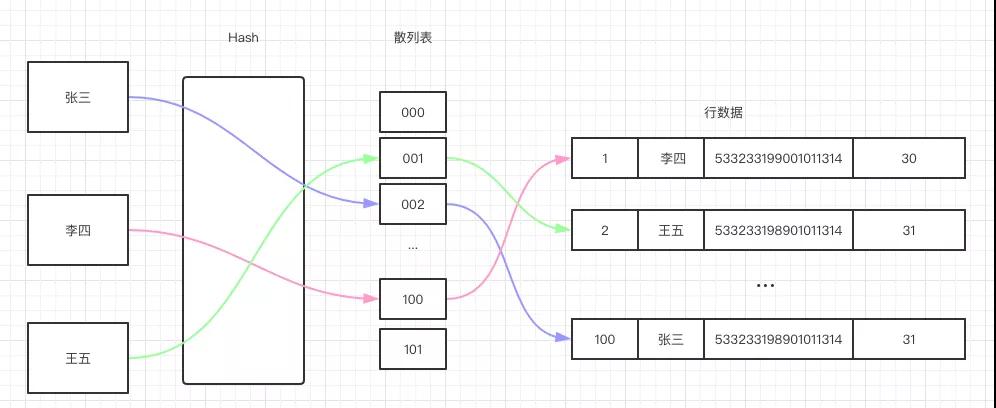
對(duì)于每一行數(shù)據(jù),存儲(chǔ)引擎都會(huì)對(duì)所有的索引列(上圖中的 name 列)計(jì)算一個(gè)哈希碼(上圖散列表的位置),散列表里的每個(gè)元素指向數(shù)據(jù)行的指針。
由于索引自身只存儲(chǔ)對(duì)應(yīng)的哈希值,所以索引的結(jié)構(gòu)十分緊湊,這讓哈希索引查找速度非常快!
當(dāng)然了哈希表的劣勢(shì)也是比較明顯的,不支持區(qū)間查找,不支持排序,所以更多的時(shí)候哈希表是與 B Tree等一起使用的。
在 InnoDB 引擎中就有一種名為「自適應(yīng)哈希索引」的特殊索引,當(dāng) innoDB 注意到某些索引值使用非常頻繁時(shí),就會(huì)內(nèi)存中基于 B-Tree 索引之上再創(chuàng)建哈希索引。
這樣也就讓 B+ 樹(shù)索引也有了哈希索引的快速查找等優(yōu)點(diǎn),這是完全自動(dòng),內(nèi)部的行為,用戶無(wú)法控制或配置,不過(guò)如果有必要,可以關(guān)閉該功能。
InnoDB 引擎本身是不支持顯式創(chuàng)建哈希索引的,我們可以在 B+ 樹(shù)的基礎(chǔ)上創(chuàng)建一個(gè)偽哈希索引,它與真正的哈希索引不是一回事,它是以哈希值而非鍵本身來(lái)進(jìn)行索引查找的,這種偽哈希索引的使用場(chǎng)景是怎樣的呢?
假設(shè)我們?cè)?db 某張表中有個(gè) url 字段,我們知道每個(gè) url 的長(zhǎng)度都很長(zhǎng),如果以 url 這個(gè)字段創(chuàng)建索引,無(wú)疑要占用很大的存儲(chǔ)空間。
如果能通過(guò)哈希(比如 CRC32)把此 url 映射成 4 個(gè)字節(jié),再以此哈希值作索引 ,索引占用無(wú)疑大大縮短!
不過(guò)在查詢的時(shí)候要記得同時(shí)帶上 url 和 url_crc,主要是為了避免哈希沖突,導(dǎo)致 url_crc 的值可能一樣:
- SELECT id FROM url WHERE url = "http://www.baidu.com" AND url_crc = CRC32("http://www.baidu.com")
這樣做把基于 url 的字符串索引改成了基于 url_crc 的整型索引,效率更高,同時(shí)索引占用的空間也大大減少,一舉兩得,當(dāng)然人可能會(huì)說(shuō)需要手動(dòng)維護(hù)索引太麻煩了,那可以改進(jìn)觸發(fā)器實(shí)現(xiàn)。
除了上文說(shuō)的兩個(gè)索引 ,還有空間索引(R-Tree),全文索引等,由生產(chǎn)中不是很常用,這里不作過(guò)多闡述。
高性能索引策略
不同的索引設(shè)計(jì)選擇能對(duì)性能產(chǎn)生很大的影響,有人可能會(huì)發(fā)現(xiàn)生產(chǎn)中明明加了索引卻不生效,有時(shí)候加了雖然生效但對(duì)搜索性能并沒(méi)有提升多少。
對(duì)于多列聯(lián)合索引,哪列在前,哪列在后也是有講究的,我們一起來(lái)看看加了索引,為何卻不生效?
加了索引卻不生效可能會(huì)有以下幾種原因:
①索引列是表示式的一部分,或是函數(shù)的一部分
如下 SQL:
- SELECT book_id FROM BOOK WHERE book_id + 1 = 5;
或者:
- SELECT book_id FROM BOOK WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(gmt_create) <= 10
上述兩個(gè) SQL 雖然在列 book_id 和 gmt_create 設(shè)置了索引 ,但由于它們是表達(dá)式或函數(shù)的一部分,導(dǎo)致索引無(wú)法生效,最終導(dǎo)致全表掃描。
②隱式類型轉(zhuǎn)換
以上兩種情況相信不少人都知道索引不能生效,但下面這種隱式類型轉(zhuǎn)換估計(jì)會(huì)讓不少人栽跟頭,來(lái)看下下面這個(gè)例子。
假設(shè)有以下表:
- CREATE TABLE `tradelog` (
- `id` int(11) NOT NULL,
- `tradeid` varchar(32) DEFAULT NULL,
- `operator` int(11) DEFAULT NULL,
- `t_modified` datetime DEFAULT NULL,
- PRIMARY KEY (`id`),
- KEY `tradeid` (`tradeid`),
- KEY `t_modified` (`t_modified`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
執(zhí)行 SQL 語(yǔ)句:
- SELECT * FROM tradelog WHERE tradeid=110717;
交易編號(hào) tradeid 上有索引,但用 EXPLAIN 執(zhí)行卻發(fā)現(xiàn)使用了全表掃描,為啥呢,tradeId 的類型是 varchar(32)。
而此 SQL 用 tradeid 一個(gè)數(shù)字類型進(jìn)行比較,發(fā)生了隱形轉(zhuǎn)換,會(huì)隱式地將字符串轉(zhuǎn)成整型,如下:
- mysql> SELECT * FROM tradelog WHERE CAST(tradid AS signed int) = 110717;
這樣也就觸發(fā)了上文中第一條的規(guī)則 ,即:索引列不能是函數(shù)的一部分。
③隱式編碼轉(zhuǎn)換
這種情況非常隱蔽,來(lái)看下這個(gè)例子:
- CREATE TABLE `trade_detail` (
- `id` int(11) NOT NULL,
- `tradeid` varchar(32) DEFAULT NULL,
- `trade_step` int(11) DEFAULT NULL, /*操作步驟*/
- `step_info` varchar(32) DEFAULT NULL, /*步驟信息*/
- PRIMARY KEY (`id`), KEY `tradeid` (`tradeid`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
trade_detail 是交易詳情, tradelog 是操作此交易詳情的記錄,現(xiàn)在要查詢 id=2 的交易的所有操作步驟信息,則我們會(huì)采用如下方式:
- SELECT d.* FROM tradelog l, trade_detail d WHERE d.tradeid=l.tradeid AND l.id=2;
由于 tradelog 與 trade_detail 這兩個(gè)表的字符集不同,且 tradelog 的字符集是 utf8mb4,而 trade_detail 字符集是 utf8,utf8mb4 是 utf8 的超集,所以會(huì)自動(dòng)將 utf8 轉(zhuǎn)成 utf8mb4。
即上述語(yǔ)句會(huì)發(fā)生如下轉(zhuǎn)換:
- SELECT d.* FROM tradelog l, trade_detail d WHERE (CONVERT(d.traideid USING utf8mb4)))=l.tradeid AND l.id=2;
自然也就觸發(fā)了 「索引列不能是函數(shù)的一部分」這條規(guī)則。怎么解決呢,第一種方案當(dāng)然是把兩個(gè)表的字符集改成一樣,如果業(yè)務(wù)量比較大,生產(chǎn)上不方便改的話。
還有一種方案是把 utf8mb4 轉(zhuǎn)成 utf8,如下:
- mysql> SELECT d.* FROM tradelog l , trade_detail d WHERE d.tradeid=CONVERT(l.tradeid USING utf8) AND l.id=2;
這樣索引列就生效了。
④使用 order by 造成的全表掃描
- SELECT * FROM user ORDER BY age DESC
上述語(yǔ)句在 age 上加了索引,但依然造成了全表掃描,這是因?yàn)槲覀兪褂昧?SELECT *,導(dǎo)致回表查詢,MySQL 認(rèn)為回表的代價(jià)比全表掃描更大。
所以不選擇使用索引,如果想使用到 age 的索引,我們可以用覆蓋索引來(lái)代替:
- SELECT age FROM user ORDER BY age DESC
或者加上 limit 的條件(數(shù)據(jù)比較小):
- SELECT * FROM user ORDER BY age DESC limit 10
這樣就能利用到索引。
無(wú)法避免對(duì)索引列使用函數(shù),怎么使用索引
有時(shí)候我們無(wú)法避免對(duì)索引列使用函數(shù),但這樣做會(huì)導(dǎo)致全表索引,是否有更好的方式呢。
比如我現(xiàn)在就是想記錄 2016 ~ 2018 所有年份 7 月份的交易記錄總數(shù):
- mysql> SELECT count(*) FROM tradelog WHERE month(t_modified)=7;
由于索引列是函數(shù)的參數(shù),所以顯然無(wú)法用到索引,我們可以將它改造成基本字段區(qū)間的查找如下:
- SELECT count(*) FROM tradelog WHERE
- -> (t_modified >= '2016-7-1' AND t_modified<'2016-8-1') or
- -> (t_modified >= '2017-7-1' AND t_modified<'2017-8-1') or
- -> (t_modified >= '2018-7-1' AND t_modified<'2018-8-1');
前綴索引與索引選擇性
之前我們說(shuō)過(guò),如于長(zhǎng)字符串的字段(如 url),我們可以用偽哈希索引的形式來(lái)創(chuàng)建索引,以避免索引變得既大又慢。
除此之外其實(shí)還可以用前綴索引(字符串的部分字符)的形式來(lái)達(dá)到我們的目的,那么這個(gè)前綴索引應(yīng)該如何選取呢,這叫涉及到一個(gè)叫索引選擇性的概念。
索引選擇性:不重復(fù)的索引值(也稱為基數(shù),cardinality)和數(shù)據(jù)表的記錄總數(shù)的比值,比值越高,代表索引的選擇性越好,唯一索引的選擇性是最好的,比值是 1。
畫(huà)外音:我們可以通過(guò) SHOW INDEXES FROM table 來(lái)查看每個(gè)索引 cardinality 的值以評(píng)估索引設(shè)計(jì)的合理性。
怎么選擇這個(gè)比例呢,我們可以分別取前 3,4,5,6,7 的前綴索引,然后再比較下選擇這幾個(gè)前綴索引的選擇性,執(zhí)行以下語(yǔ)句:
- SELECT
- COUNT(DISTINCT LEFT(city,3))/COUNT(*) as sel3,
- COUNT(DISTINCT LEFT(city,4))/COUNT(*) as sel4,
- COUNT(DISTINCT LEFT(city,5))/COUNT(*) as sel5,
- COUNT(DISTINCT LEFT(city,6))/COUNT(*) as sel6,
- COUNT(DISTINCT LEFT(city,7))/COUNT(*) as sel7
- FROM city_demo
得結(jié)果如下:

可以看到當(dāng)前綴長(zhǎng)度為 7 時(shí),索引選擇性提升的比例已經(jīng)很小了,也就是說(shuō)應(yīng)該選擇 city 的前六個(gè)字符作為前綴索引,如下:
- ALTER TABLE city_demo ADD KEY(city(6))
我們當(dāng)前是以平均選擇性為指標(biāo)的,有時(shí)候這樣是不夠的,還得考慮最壞情況下的選擇性。
以這個(gè) demo 為例,可能一些人看到選擇 4,5 的前綴索引與選擇 6,7 的選擇性相差不大,那就得看下選擇 4,5 的前綴索引分布是否均勻了:
- SELECT
- COUNT(*) AS cnt,
- LEFT(city, 4) AS pref
- FROM city_demo GROUP BY pref ORDER BY cnt DESC LIMIT 5
可能會(huì)出現(xiàn)以下結(jié)果:
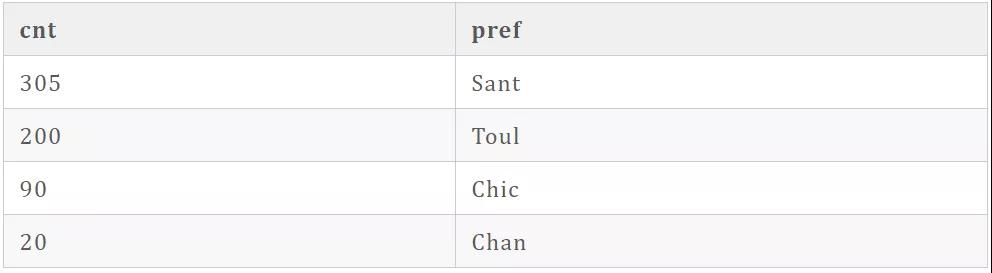
可以看到分布極不均勻,以 Sant,Toul 為前綴索引的數(shù)量極多,這兩者的選擇性都不是很理想,所以要選擇前綴索引時(shí)也要考慮最差的選擇性的情況。
前綴索引雖然能實(shí)現(xiàn)索引占用空間小且快的效果,但它也有明顯的弱點(diǎn),MySQL 無(wú)法使用前綴索引做 ORDER BY 和 GROUP BY ,而且也無(wú)法使用前綴索引做覆蓋掃描,前綴索引也有可能增加掃描行數(shù)。
假設(shè)有以下表數(shù)據(jù)及要執(zhí)行的 SQL:
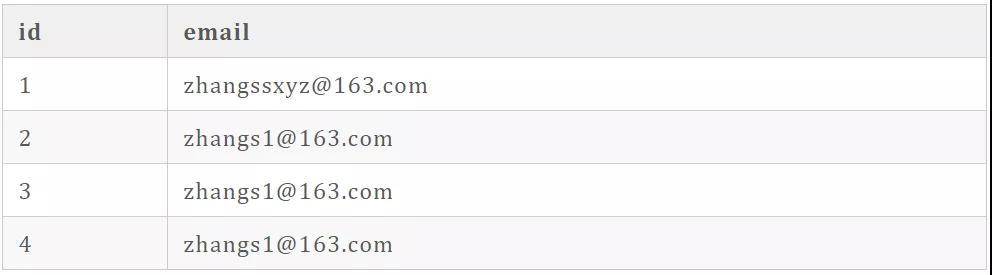
- SELECT id,email FROM user WHERE email='zhangssxyz@xxx.com';
如果我們針對(duì) email 設(shè)置的是整個(gè)字段的索引,則上表中根據(jù) 「zhangssxyz@163.com」查詢到相關(guān)記記錄后,再查詢此記錄的下一條記錄,發(fā)現(xiàn)沒(méi)有,停止掃描。
此時(shí)可知只掃描一行記錄,如果我們以前六個(gè)字符(即 email(6))作為前綴索引,則顯然要掃描四行記錄,并且獲得行記錄后不得不回到主鍵索引再判斷 email 字段的值,所以使用前綴索引要評(píng)估它帶來(lái)的這些開(kāi)銷。
另外有一種情況我們可能需要考慮一下,如果前綴基本都是相同的該怎么辦,比如現(xiàn)在我們?yōu)槟呈械氖忻窠⒁粋€(gè)人口信息表,則這個(gè)市人口的身份證雖然不同,但身份證前面的幾位數(shù)都是相同的,這種情況該怎么建立前綴索引呢。
一種方式就是我們上文說(shuō)的,針對(duì)身份證建立哈希索引,另一種方式比較巧妙,將身份證倒序存儲(chǔ),查的時(shí)候可以按如下方式查詢:
- SELECT field_list FROM t WHERE id_card = reverse('input_id_card_string');
這樣就可以用身份證的后六位作前綴索引了,是不是很巧妙?
實(shí)際上上文所述的索引選擇性同樣適用于聯(lián)合索引的設(shè)計(jì),如果沒(méi)有特殊情況,我們一般建議在建立聯(lián)合索引時(shí),把選擇性最高的列放在最前面。
比如,對(duì)于以下語(yǔ)句:
- SELECT * FROM payment WHERE staff_id = xxx AND customer_id = xxx;
單就這個(gè)語(yǔ)句而言, (staff_id,customer_id) 和 (customer_id, staff_id) 這兩個(gè)聯(lián)合索引我們應(yīng)該建哪一個(gè)呢,可以統(tǒng)計(jì)下這兩者的選擇性。
- SELECT
- COUNT(DISTINCT staff_id)/COUNT(*) as staff_id_selectivity,
- COUNT(DISTINCT customer_id)/COUNT(*) as customer_id_selectivity,
- COUNT(*)
- FROM payment
結(jié)果為:
- staff_id_selectivity: 0.0001
- customer_id_selectivity: 0.0373
- COUNT(*): 16049
從中可以看出 customer_id 的選擇性更高,所以應(yīng)該選擇 customer_id 作為第一列。
索引設(shè)計(jì)準(zhǔn)則:三星索引
上文我們得出了一個(gè)索引列順序的經(jīng)驗(yàn) 法則:將選擇性最高的列放在索引的最前列,這種建立在某些場(chǎng)景可能有用,但通常不如避免隨機(jī) IO 和 排序那么重要,這里引入索引設(shè)計(jì)中非常著名的一個(gè)準(zhǔn)則:三星索引。
如果一個(gè)查詢滿足三星索引中三顆星的所有索引條件,理論上可以認(rèn)為我們?cè)O(shè)計(jì)的索引是最好的索引。
什么是三星索引?
- 第一顆星:WHERE 后面參與查詢的列可以組成了單列索引或聯(lián)合索引。
- 第二顆星:避免排序,即如果 SQL 語(yǔ)句中出現(xiàn) order by colulmn,那么取出的結(jié)果集就已經(jīng)是按照 column 排序好的,不需要再生成臨時(shí)表。
- 第三顆星:SELECT 對(duì)應(yīng)的列應(yīng)該盡量是索引列,即盡量避免回表查詢。
所以對(duì)于如下語(yǔ)句:
- SELECT age, name, city where age = xxx and name = xxx order by age
設(shè)計(jì)的索引應(yīng)該是 (age,name,city) 或者 (name,age,city)。
當(dāng)然了,三星索引是一個(gè)比較理想化的標(biāo)準(zhǔn),實(shí)際操作往往只能滿足期望中的一顆或兩顆星,考慮如下語(yǔ)句:
- SELECT age, name, city where age >= 10 AND age <= 20 and city = xxx order by name desc
假設(shè)我們分別為這三列建了聯(lián)合索引,則顯然它符合第三顆星(使用了覆蓋索引)。
如果索引是(city,age,name),則雖然滿足了第一顆星,但排序無(wú)法用到索引,不滿足第二顆星,如果索引是 (city,name,age),則第二顆星滿足了,但此時(shí) age 在 WHERE 中的搜索條件又無(wú)法滿足第一星。
另外第三顆星(盡量使用覆蓋索引)也無(wú)法完全滿足,試想我要 SELECT 多列,要把這多列都設(shè)置為聯(lián)合索引嗎,這對(duì)索引的維護(hù)是個(gè)問(wèn)題,因?yàn)槊恳淮伪淼? CURD 都伴隨著索引的更新,很可能頻繁伴隨著頁(yè)分裂與頁(yè)合并。
綜上所述,三星索引只是給我們構(gòu)建索引提供了一個(gè)參考,索引設(shè)計(jì)應(yīng)該盡量靠近三星索引的標(biāo)準(zhǔn)。
但實(shí)際場(chǎng)景我們一般無(wú)法同時(shí)滿足三星索引,一般我們會(huì)優(yōu)先選擇滿足第三顆星(因?yàn)榛乇泶鷥r(jià)較大)至于第一,二顆星就要依賴于實(shí)際的成本及實(shí)際的業(yè)務(wù)場(chǎng)景考慮。
總結(jié)
本文簡(jiǎn)述了索引的基本原理,索引的幾種類型,以及分析了一下設(shè)計(jì)索引盡量應(yīng)該遵循的一些準(zhǔn)則,相信我們對(duì)索引的理解又更深了一步。
作者:碼海
編輯:陶家龍
出處:轉(zhuǎn)載自微信公眾號(hào)碼海(ID:seaofcode)












