干貨!3 個(gè)重要因素,帶你看透 AI 技術(shù)架構(gòu)方案的可行性
人工智能這幾年發(fā)展的如火如荼,不僅在計(jì)算機(jī)視覺(jué)和自然語(yǔ)言處理領(lǐng)域發(fā)生了翻天覆地的變革,在其他領(lǐng)域也掀起了技術(shù)革新的浪潮。無(wú)論是在新業(yè)務(wù)上的嘗試,還是對(duì)舊有業(yè)務(wù)對(duì)改造升級(jí),AI這個(gè)奔涌了60多年的“后浪”,正潛移默化的影響著我們傳統(tǒng)的技術(shù)架構(gòu)觀念。
AI架構(gòu)(尤其是以機(jī)器學(xué)習(xí)和深度學(xué)習(xí)為代表的架構(gòu)方案)已經(jīng)成為我們技術(shù)架構(gòu)選型中的一個(gè)新的選項(xiàng)。
你是否需要AI架構(gòu)的解決方案?AI架構(gòu)選型的主要依據(jù)是什么?這是我們今天主要討論的問(wèn)題。
我們先來(lái)看一個(gè)典型的AI架構(gòu):
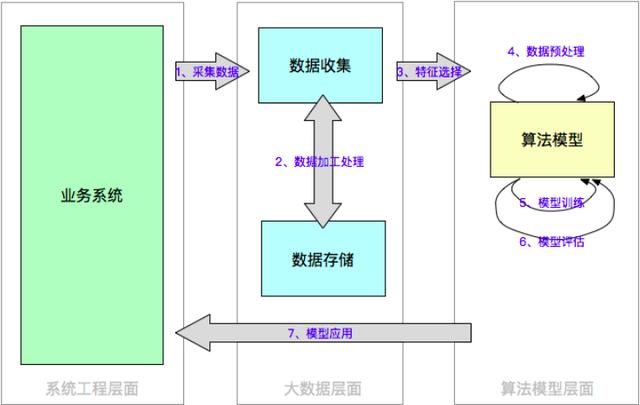
1、首先需要采集訓(xùn)練模型所需要的數(shù)據(jù),這些數(shù)據(jù)有可能來(lái)自業(yè)務(wù)系統(tǒng)本身,如CTR預(yù)估任務(wù)中的用戶點(diǎn)擊數(shù)據(jù)、用戶下單數(shù)據(jù)等;也有可能來(lái)系統(tǒng)外部,公開購(gòu)買或自主爬取,如圖片分類任務(wù)中的圖片、NLP任務(wù)中的語(yǔ)料等。
2、這些數(shù)據(jù)被收集起來(lái)后,經(jīng)過(guò)清洗、加工,被存儲(chǔ)起來(lái),因?yàn)楫吘共皇侵挥靡淮巍R话闶谴鎯?chǔ)在分布式存儲(chǔ)設(shè)備(如HDFS)或云端,多數(shù)公司還會(huì)建立自己的數(shù)據(jù)平臺(tái),保存在數(shù)據(jù)倉(cāng)庫(kù)中,長(zhǎng)期積累下來(lái)。
3、需要使用的時(shí)候,先進(jìn)行數(shù)據(jù)篩選,選擇合適的特征數(shù)據(jù),然后經(jīng)過(guò)數(shù)據(jù)預(yù)處理,送入到算法模型中。模型的搭建可選的技術(shù)框架很多,可以是基于spark mllib,也可以是sklearn、tensorflow、pytorch等。然后經(jīng)過(guò)訓(xùn)練、評(píng)估和調(diào)參,完成模型的構(gòu)建工作。
4、最后模型要應(yīng)用到線上的具體業(yè)務(wù)中,完成分類、回歸某一具體任務(wù)。在部署過(guò)程中,有可能是將模型打包,將預(yù)測(cè)模型直接部署到業(yè)務(wù)系統(tǒng)(客戶端)中;也有可能是直接提供一個(gè)在線RESTful接口,方便跨語(yǔ)言調(diào)用。
總結(jié)一下,經(jīng)過(guò)數(shù)據(jù)采集、加工處理、特征選擇、數(shù)據(jù)預(yù)處理、模型訓(xùn)練、模型評(píng)估、模型應(yīng)用幾個(gè)環(huán)節(jié),數(shù)據(jù)跨過(guò)業(yè)務(wù)系統(tǒng)、數(shù)據(jù)平臺(tái)、算法模型三個(gè)系統(tǒng),形成一個(gè)閉環(huán),最終又應(yīng)用到業(yè)務(wù)系統(tǒng)中,這就構(gòu)成了整個(gè)AI架構(gòu)的核心。
是否需要AI架構(gòu),如何衡量這套技術(shù)架構(gòu)方案的可行性?我認(rèn)為,主要是看以下三個(gè)要素。
1. 場(chǎng)景
我們討論架構(gòu)的可行性,是否適合業(yè)務(wù)及業(yè)務(wù)發(fā)展是第一衡量準(zhǔn)則,AI架構(gòu)也不例外。
回顧那些經(jīng)典的、已經(jīng)廣泛應(yīng)用的機(jī)器學(xué)習(xí)場(chǎng)景,比如推薦、搜索、廣告等,這些場(chǎng)景都具有這樣的特點(diǎn):場(chǎng)景相對(duì)封閉、目標(biāo)單一、可控。
究其原因,無(wú)論算法模型多么復(fù)雜,其最終都要落實(shí)到損失函數(shù)上的,而后者一般都是單目標(biāo)、單優(yōu)化任務(wù)。或追求極值(損失最小化)、或達(dá)到某種對(duì)抗上的平衡(比如GAN)。在這種情況下,無(wú)論業(yè)務(wù)如何建模,還是要落地到算法模型和損失函數(shù)的,最終也就限制了場(chǎng)景和目標(biāo)上的單一。
因此,看一個(gè)業(yè)務(wù)是否適合AI架構(gòu),就要先看這個(gè)業(yè)務(wù)場(chǎng)景目標(biāo)是否單一、可控。或經(jīng)過(guò)業(yè)務(wù)建模和架構(gòu)拆解后,每個(gè)環(huán)節(jié)的場(chǎng)景是否單一。
舉個(gè)例子,同程藝龍酒店系統(tǒng)為酒店商家提供了上傳酒店圖片的功能,在這個(gè)場(chǎng)景下,除了要審查圖片的合法性,還要給圖片打上分類標(biāo)簽,如“大堂”、“前臺(tái)”、“客房”、“周邊”等。為了能正常使用AI架構(gòu),就必須對(duì)場(chǎng)景內(nèi)的各目標(biāo)進(jìn)行拆分,訓(xùn)練不同的分類器。具體流程如下:
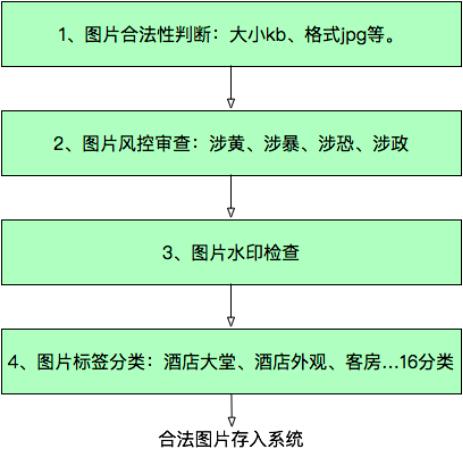
其中,第2、3、4步涉及到多個(gè)圖片分類器,每個(gè)分類器的目標(biāo)不同,所需要的訓(xùn)練數(shù)據(jù)也不同。對(duì)于輸入的同一個(gè)樣本圖片,每個(gè)分類器完成自己的職能,目標(biāo)單一可控。對(duì)于一些不通過(guò)的樣本,可能還涉及到人工干預(yù)。最后合法的圖片存入系統(tǒng)。
從業(yè)務(wù)必要性上來(lái)說(shuō),也并不是所有業(yè)務(wù)場(chǎng)景都需要AI架構(gòu)。算法模型是對(duì)事物的精確模擬和抽象,復(fù)雜度也是比較高的。但可能有時(shí)我們業(yè)務(wù)上并不需要如此精細(xì)的控制。比如有時(shí)一個(gè)簡(jiǎn)單的if...else...就解決了問(wèn)題;復(fù)雜點(diǎn)的可能會(huì)設(shè)計(jì)幾種“策略”,然后由業(yè)務(wù)專家針對(duì)每種情況進(jìn)行配置;再?gòu)?fù)雜的可能還會(huì)考慮BI的方案:收集數(shù)據(jù),然后展開多維度的分析,最后由分析師連同業(yè)務(wù)專家得到某種規(guī)律性的結(jié)論,再內(nèi)置到系統(tǒng)里,效果可能也不錯(cuò)。
再舉個(gè)酒店分銷調(diào)價(jià)的例子,在將酒店分銷給代理售賣前,一般會(huì)在底價(jià)基礎(chǔ)上對(duì)產(chǎn)品賣價(jià)進(jìn)行干預(yù),調(diào)整一定的點(diǎn)數(shù)(百分比),保證銷量的同時(shí),最大化收益。
一開始,可能僅僅是一個(gè)固定的比率(比如加價(jià)6%)。隨著業(yè)務(wù)發(fā)展,設(shè)計(jì)了一系列策略,比如針對(duì)“是否獨(dú)家”、“是否熱門”2維度將酒店劃分到4個(gè)象限里,對(duì)“獨(dú)家-熱門”酒店實(shí)施一個(gè)較高的調(diào)價(jià)比率,而對(duì)“非獨(dú)家-冷門”酒店實(shí)施一個(gè)較低的比率。結(jié)果收益提高了一大截,效果不錯(cuò)。
而后,業(yè)務(wù)人員希望施行更加精細(xì)的控制,于是對(duì)酒店的星級(jí)、地區(qū)、商圈、獨(dú)家、房型等維度進(jìn)行了更為精細(xì)的劃分,并結(jié)合歷史數(shù)據(jù)進(jìn)行統(tǒng)計(jì)分析,對(duì)各種結(jié)果施以不同的調(diào)價(jià)比率。產(chǎn)量和收益又進(jìn)一步提升了。
這時(shí)如果各業(yè)務(wù)方都比較滿意、成本也不高,系統(tǒng)復(fù)雜度也不高,那就沒(méi)必有再考慮更為精細(xì)、智能的AI架構(gòu)了。引入AI,本質(zhì)上,還是要帶來(lái)效率、體驗(yàn)或準(zhǔn)確性的提升,同時(shí)平衡成本和收益,控制系統(tǒng)復(fù)雜度。如果不能帶來(lái)這些,那就要重新審視我們的方案了。
當(dāng)然,有時(shí)我們也會(huì)考慮架構(gòu)的擴(kuò)展性和業(yè)務(wù)的發(fā)展,預(yù)留一些設(shè)計(jì)上的“開閉”空間。“策略模式”這時(shí)也許是個(gè)不錯(cuò)的選擇。對(duì)于系統(tǒng)的默認(rèn)策略,采用基于人工的、配置的方案,同時(shí)保留策略擴(kuò)展接口,隨著將來(lái)業(yè)務(wù)要求的增高,再引入“基于AI的策略”。這樣即控制了當(dāng)前的成本,又平衡了系統(tǒng)的擴(kuò)展性。
2. 數(shù)據(jù)
數(shù)據(jù)決定了機(jī)器學(xué)習(xí)的上限,而算法和模型只是逼近這個(gè)上限而已。
數(shù)據(jù)的采集和獲取通常需要很長(zhǎng)時(shí)間,建立充分、全面的數(shù)據(jù)倉(cāng)庫(kù),更需要長(zhǎng)時(shí)間的積累和打磨,因此,數(shù)據(jù)在任何一個(gè)公司都是寶貴的資產(chǎn),不肯輕易送出。而一個(gè)算法模型的成功與否,關(guān)鍵看數(shù)據(jù)和特征。因此,一套AI架構(gòu)的解決方案,最終能否取得好的效果,關(guān)鍵看是否已經(jīng)采集到了足夠、充分的數(shù)據(jù)。
這些數(shù)據(jù)來(lái)源一般包括:自有系統(tǒng)采集、互聯(lián)網(wǎng)公開數(shù)據(jù)收集(或爬取)、外購(gòu)等。
自有系統(tǒng)采集是最常見(jiàn)的方案,業(yè)務(wù)系統(tǒng)自身產(chǎn)生的數(shù)據(jù),一般也更適合業(yè)務(wù)場(chǎng)景的應(yīng)用。可這樣的數(shù)據(jù)珍貴且稀少,所以往往需要公司的決策者提前布局,早早的開始收集、整理業(yè)務(wù)數(shù)據(jù),建設(shè)數(shù)據(jù)平臺(tái)、充實(shí)數(shù)據(jù)倉(cāng)庫(kù),這樣經(jīng)過(guò)幾個(gè)月甚至幾年以后,在真正用到AI架構(gòu)時(shí),彈藥庫(kù)里已經(jīng)儲(chǔ)備了充足的“彈藥”了。
互聯(lián)網(wǎng)公開的數(shù)據(jù)爬取也是一個(gè)快速且免費(fèi)的方法,但在茫茫大海中找到適合自己的數(shù)據(jù)并不容易,且因?yàn)槟隳苣玫健e人也能拿到,因此很難拉開和其他競(jìng)對(duì)公司的差異。
外購(gòu)一般要花費(fèi)巨額費(fèi)用,且質(zhì)量參差不齊,一般是互聯(lián)網(wǎng)公司最后不得已的方案。
在數(shù)據(jù)獲取成本高、難度大、積攢時(shí)間久這樣的前提下,而場(chǎng)景又適合使用AI架構(gòu),面對(duì)數(shù)據(jù)匱乏,是不是就沒(méi)有辦法了呢?也不盡然,我們還是有些替代方案的。
1、 淺層模型通常比深層模型需要更少的數(shù)據(jù)量,因此,在數(shù)據(jù)量不足的時(shí)候,通常可以使用淺層模型替代深層模型來(lái)減少對(duì)數(shù)據(jù)量的需求。當(dāng)然,模型的表達(dá)能力也會(huì)隨之下降,但應(yīng)對(duì)不是特別復(fù)雜的業(yè)務(wù)場(chǎng)景,淺層模型也一樣能取得很好的效果。當(dāng)然,隨之而來(lái)的是對(duì)特征挖掘更高的要求和對(duì)模型選擇的挑剔。拿分類任務(wù)來(lái)說(shuō),SVM、邏輯回歸、隨機(jī)森林、樸素貝葉斯...每種模型都有其特點(diǎn)和適用性,要充分考慮和權(quán)衡,才能利用好每一條數(shù)據(jù)。所謂數(shù)據(jù)不夠、模型來(lái)湊,也是不得已的辦法。
2、 采用預(yù)訓(xùn)練模型也是降低數(shù)據(jù)需求量的一個(gè)很好的辦法,遷移學(xué)習(xí)已經(jīng)在圖像分類問(wèn)題上廣泛運(yùn)用,BERT模型也將預(yù)訓(xùn)練模型帶入自然語(yǔ)言處理的大門。在一些特定問(wèn)題上,如果能找到合適的預(yù)訓(xùn)練模型,再加之少量自己的數(shù)據(jù)進(jìn)行微調(diào),不但對(duì)數(shù)據(jù)的需求量降低,訓(xùn)練時(shí)間也大大降低,一舉兩得。只是合適的預(yù)訓(xùn)練模型可遇而不可求。
3、 還有一個(gè)減少數(shù)據(jù)需求的變通的辦法是采用少量數(shù)據(jù)先“啟動(dòng)”,然后不斷獲取數(shù)據(jù),并加快模型更新頻率,直至采用“在線學(xué)習(xí)”的方法。這里實(shí)際上是將總的數(shù)據(jù)需求,拉長(zhǎng)到時(shí)間維度去解決。當(dāng)然,這里也需要業(yè)務(wù)上允許前期模型的準(zhǔn)確度不是那么高,隨著數(shù)據(jù)的增多和模型的不斷更新,逐步達(dá)到預(yù)期效果。
舉個(gè)例子,酒店shopper類產(chǎn)品的售賣,為了加快展現(xiàn)速度,通常采取供應(yīng)商數(shù)據(jù)預(yù)抓取的方式落地。但供應(yīng)商給的QPS極其有限,每次只能抓取一個(gè)酒店,高頻率的抓取可以保證酒店數(shù)據(jù)的新鮮度,給客人更好的體驗(yàn);低頻率的抓取因庫(kù)存、價(jià)格信息時(shí)效性不能保證,往往就會(huì)導(dǎo)致預(yù)定失敗,造成損失。因此,如何在酒店間合理的分配QPS就是一個(gè)典型的機(jī)器學(xué)習(xí)問(wèn)題。
我們從酒店熱度、預(yù)定周期、節(jié)假日等多個(gè)維度進(jìn)行了特征挖掘,最后卻發(fā)現(xiàn)“季節(jié)”這個(gè)關(guān)鍵因素,我們卻提取不到有效特征,原因是數(shù)據(jù)倉(cāng)庫(kù)里只有三個(gè)月的數(shù)據(jù),也就是只有當(dāng)季的數(shù)據(jù)。
為了解決這個(gè)問(wèn)題,我們重新設(shè)計(jì)了模型,調(diào)整了架構(gòu)方案,采用“在線學(xué)習(xí)”的方式,將模型更新問(wèn)題納入到了解決方案中。原始數(shù)據(jù)只用來(lái)訓(xùn)練一個(gè)初始模型,上線后,模型不斷拿新產(chǎn)生的數(shù)據(jù)并進(jìn)行迭代更新,同時(shí)對(duì)時(shí)間線更近的數(shù)據(jù)賦以更高的樣本權(quán)重,以此來(lái)保證對(duì)季節(jié)性因素的跟進(jìn)。系統(tǒng)上線后,取得了很好的效果。
4、 強(qiáng)化學(xué)習(xí)在初始數(shù)據(jù)缺乏的情況下,大多數(shù)時(shí)候也是一個(gè)備選方案。強(qiáng)化學(xué)習(xí)采用“試錯(cuò)”的方式,不斷演化,并最終學(xué)到規(guī)律。當(dāng)然這需要業(yè)務(wù)模型做相應(yīng)的調(diào)整,同時(shí),如果演化周期過(guò)長(zhǎng),那有可能模型在前期相當(dāng)長(zhǎng)的時(shí)間內(nèi),都不能做出較優(yōu)的決策,因此需要業(yè)務(wù)容忍度較高。
3. 算力
眾所周知,訓(xùn)練過(guò)程是一個(gè)典型的“計(jì)算密集型任務(wù)”,沒(méi)有強(qiáng)大的算力,是難以支撐算法模型的訓(xùn)練和研究的。做機(jī)器學(xué)習(xí)的計(jì)算平臺(tái),GPU幾乎是標(biāo)配,其訓(xùn)練時(shí)間比CPU一般能縮短5倍以上。
目前,主要有自建和租賃云平臺(tái)兩種途徑獲取。如果“不差錢”,當(dāng)然可以選擇自建,但現(xiàn)在GPU升級(jí)換代太快,基本一年一換。對(duì)于做機(jī)器學(xué)習(xí)的GPU來(lái)說(shuō),運(yùn)算速度是關(guān)鍵,很可能花了大價(jià)錢搭建的GPU集群,過(guò)幾年卻變成了一臺(tái)“老爺車”。
租賃云平臺(tái)雖然可以隨時(shí)享受最新GPU運(yùn)算速度帶來(lái)的“快感”,但所需花費(fèi)的精力也不少。不但要詳細(xì)對(duì)比每家云平臺(tái)提供的服務(wù)和成本,還要合理的搭配CPU和GPU,做到資源利用最大化。
說(shuō)了這么多,提的最多的可能就是“成本”和“收益”這兩個(gè)詞了,這也是業(yè)務(wù)最關(guān)心的問(wèn)題。無(wú)論是計(jì)算資源還是系統(tǒng)架構(gòu),上一套AI架構(gòu)的解決方案都是需要投入相當(dāng)大的成本的,如果選擇得當(dāng),在一個(gè)合適的場(chǎng)景下,AI也是能帶來(lái)相當(dāng)不錯(cuò)的收益;但如果入不敷出,選擇AI架構(gòu)的解決方案就要慎重了。
最后,技術(shù)人員儲(chǔ)備和法律因素也是上AI架構(gòu)前需要考量的問(wèn)題,前陣子還發(fā)生了國(guó)家工信部約談AI換臉應(yīng)用企業(yè)的事件。
AI是一場(chǎng)浪潮,它不僅帶來(lái)了新的技術(shù)和行業(yè),也給了老系統(tǒng)煥發(fā)新生命活力的機(jī)會(huì)。作為技術(shù)人員,我們不僅要擁抱新技術(shù)帶來(lái)的挑戰(zhàn),更要清楚其技術(shù)選型的主要因素和背后的風(fēng)險(xiǎn),這樣才能屹立浪潮之巔。那么,你是否需要AI架構(gòu)的解決方案呢?