













處理器感知線程管理系統 · OSDI 2018
本文要介紹的是 2018 年 OSDI 期刊中的論文 —— Arachne: Core-Aware Thread Management[^1],這篇論文通過引入處理器感知的線程管理器 Arachne[^2] 提高應用程序的性能,通過在 Memcached 中引入新的線程管理器,我們可以將 Memcached 的吞吐量提高 37%、降低 10 倍的尾延遲并且在與其他應用程序混合部署時也幾乎不會帶來性能上的損耗。今天我們來看一看論文中基于處理器感知的線程管理器如何幫助應用程序實現低延遲和高吞吐量。
想要同時實現低延遲和高吞吐量不是一件簡單的事情,在傳統的線程管理或者協程管理器中,上層的應用程序不清楚底層的調度策略,應用程序自己無法決定會跑在哪個 CPU 上。因為大多數的場景不需要考慮極端的性能,代碼的可維護性和可讀性相比更加重要,這種關注點分離的設計方式能夠降低應用程序的復雜性,所以它能夠為開發者提供便利。
應用程序想要實現低延遲和高吞吐量就一定要通過虛擬資源管理它們的并行性,而現在它們沒有辦法告訴操作系統需要多少 CPU 資源,也無法直接確定線程和 CPU 之間的綁定關系。想要實現低延遲和高吞吐量,每個應用程序都應該能夠根據負載動態決定需要多少 CPU 資源并且可以控制線程和 CPU 的綁定關系。
處理器感知線程管理會為應用程序提供 CPU 等信息,將對 CPU 的部分控制權開放給應用開發者以滿足應用程序在性能上的需求、不過因為 Linux 等操作系統沒有直接提供易用的接口,所以 Arachne 使用了如下圖所示的架構實現處理器感知的線程管理,整個系統不需要修改操作系統內核,它依賴操作系統提供的接口實現處理器感知,也可以與不使用 Arachne 的應用程序一起運行:
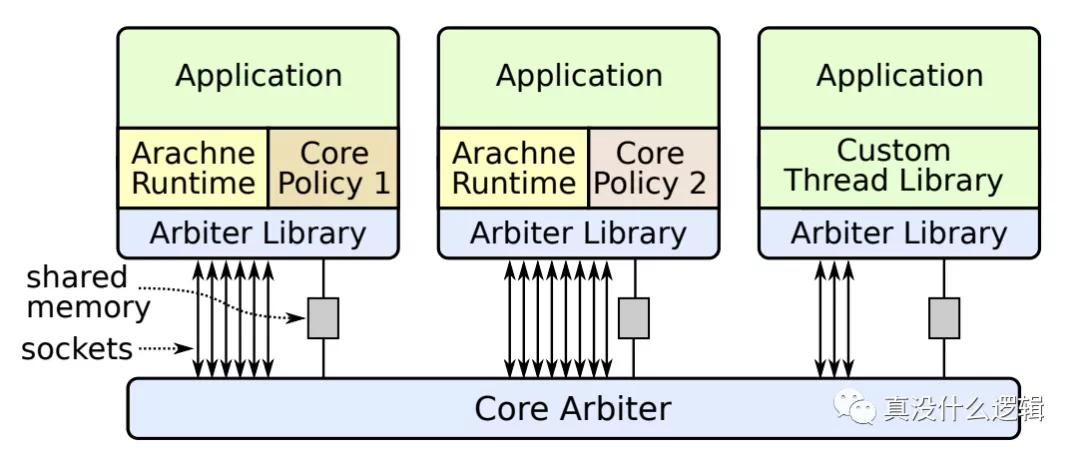
圖 1 - Arachne 架構
Arachne 中包含了三個重要的組件,分別是仲裁者、運行時和策略,其中仲裁者是運行在 Linux 上的守護進程,所有使用 Arachne 的應用程序都會利用它提供的運行時庫通過 Socket 與守護進程通信,我們將依次介紹這三個組件的作用和原理。
仲裁者
核心仲裁者(Core Arbiter)是 Arachne 的核心組件,它是應用程序和操作系統的中間層,主要負責控制系統中的 CPU 并將這些資源合理地分配給不同的應用程序,該系統包含三個特點:
- 在用戶態基于 Linux 的機制實現了 CPU 管理;
- 可以與不使用 Arachne 的應用程序同時存在;
- 使用協作式的方法管理內核,包括優先級管理和內核搶占;
仲裁者使用 Linux 的 cpuset 特性將內核分成管理的內核和未被管理的內核,未被管理的內核會分配給機器上的其他應用程序,而被管理的內存會分配給使用 Arachne 的進程。
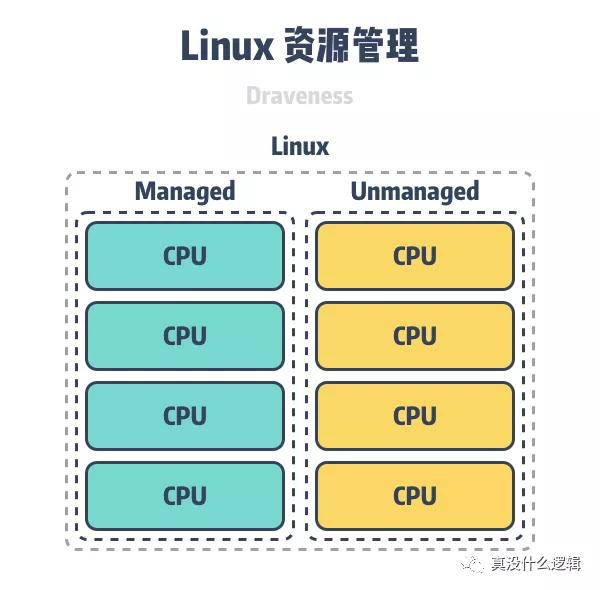
圖 2 - 拆分 CPU 資源
這種方案可以與現有的進程運行方式兼容,我們不需要修改內核,就可以直接利用 Linux 現有的特性管理 CPU 資源。
優先級管理
當應用程序啟動時,它會調用 setRequestedCores: 方法通過 Socket 向仲裁者請求 CPU 資源,該方法的參數是一個數組,從左到右依次表示八種不同優先級的 CPU:
- 0 0 1 2 0 0 0 0
仲裁者使用了比較簡單的優先級管理策略,高優先級的請求可以覆蓋低優先級的請求,因為沒有其他調度器的分時復用機制,并且調度基本都是協作式的,所以部分應用程序只要申請高優先級的資源就可以餓死其他進程,Arachne 中并沒有解決這個問題,雖然它提出可以通過鑒權防止惡意資源申請,但是這仍然無法解決饑餓問題。
資源申請
當應用程序想要向仲裁者申請 CPU 資源時,會經歷如下所示的幾個步驟:
- 應用程序在發出 setRequestedCores: 后會即創建與請求核數相同的內核線程(Kernel Thread);
- 調用 blockUntilCoreAvailable: 阻塞這些線程等待仲裁者分配資源;
- 當仲裁者決定為這些線程分配資源時,它會通過 cpuset 綁定線程和 CPU、通知并喚醒應用程序的內核線程,操作系統會負責將當前線程調度到綁定的 CPU 上;
- Arachne 運行時中的內核線程隨后會在調度器中為其他的用戶線程分配合適的資源;
每一個基于 Arachne 運行時的應用程序中都會啟動對應數量的內核線程,運行時中的調度器會決定執行哪些用戶態線程,該模型與 Go 語言的 G-M-P 模型也比較相似[^3],它們的初衷都是盡可能降低線程切換帶來的額外開銷,但是 Arachne 提供了對資源更細粒度的控制:
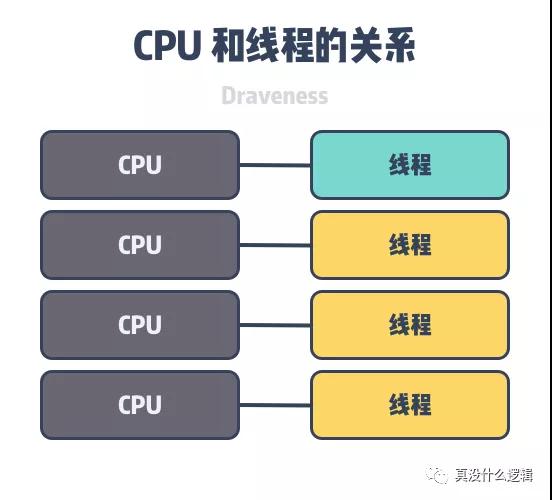
圖 3 - Arachne 線程模型
需要注意的是仲裁者和應用程序之間的通信機制是不同的,應用程序會通過 Socket 訪問仲裁者,而仲裁者發出的請求都是通過共享內存。這是因為應用程序在發出請求后可以陷入休眠等待響應或者資源的分配,但是 Socket 是相對比較昂貴的操作,所以仲裁者會通過共享內存請求應用程序。
Arachne 使用了協作的方式進行調度,當仲裁者需要回收資源時,應用程序可以延遲一段時間釋放 CPU;如果應用程序超過 10ms 都沒有釋放資源,仲裁者就會通過 cpuset 將資源分配給其他程序,沒有主動釋放的程序會看到性能明顯地下降。
運行時
Arachne 的運行時實現了老生常談的用戶態線程,但是這里的用戶態線程針對特定的場景做出了優化,它主要支持細粒度的計算,其中包括大量生命周期極短的線程,例如常見的 HTTP/RPC 服務,它們會創建單獨的線程處理外部的請求。
圖 4 - HTTP 服務與線程
大多數的線程操作都需要在多個 CPU 之間通信,而跨核的通信會導致緩存缺失(Cahce Miss),緩存缺失大概需要 50 ~ 200 個 CPU 循環,這也是影響 Arachne 運行時性能的主要因素。為了解決緩存缺失帶來的性能影響,運行時會在數據傳輸時并行執行其他的指令,優化 CPU 緩存以提升用戶態線程的性能。線程的創建和調度是運行時的關鍵操作,優化這些操作的性能就可以降低延遲并提高吞吐量。
線程創建
多數的用戶態線程管理器都會在同一個 CPU 上創建線程并使用工作竊取(Work-stealing)[^4]平衡多個 CPU 上的負載,但是工作竊取對于存在時間較短的線程來說是非常昂貴的,所以我們希望在線程創建時立刻觸發負載均衡,將線程創建在其他的核心上;同時,為了減少程序中的緩存丟失,Arachne 將每一個線程的上下文都綁定了特定的 CPU 上,只有在仲裁者回收時才可能發生處理器遷移,大多數的線程在創建之后就不會觸發遷移。當應用程序創建新的線程時:
- 運行時會在多個 CPU 中隨機選擇兩個;
- 在上述兩個 CPU 中選擇活躍線程數較少的 CPU;
- 將線程開始的方法地址和參數拷貝到上下文中;
每個 CPU 上都有對應的 maskAndCount 變量,其中存儲著正在執行的線程和當前 CPU 上的線程數。為了減少線程的緩存丟失,我們使用單獨的緩存塊(Cache Line)存儲線程所有信息,這樣創建線程最少只需要觸發四次緩存丟失,分別是讀取maskAndCount、傳輸函數地址、參數和調度信息,能夠最大限度的減少開銷。
線程調度
傳統的調度模型會在運行時中引入準備隊列(Ready Queue)保存可執行的線程,例如:Linux 和 Go 語言的調度器[^5],但是如果準備隊列是跨 CPU 的,那么增加或者刪除任務時都需要修改多個變量以及獲取共享鎖,這都會觸發緩存丟失進而影響性能。
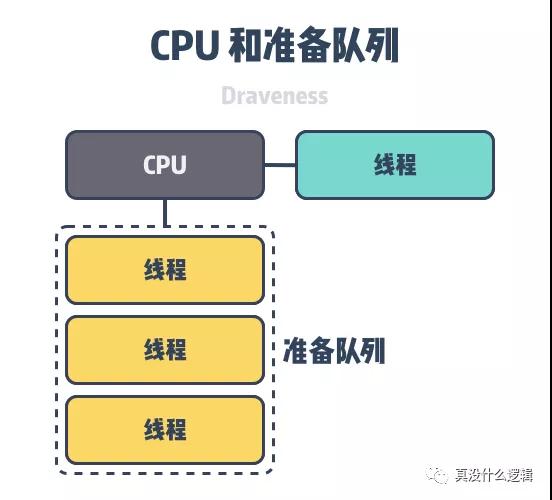
圖 5 - 線程調度
為了減少程序中的緩存丟失,Arachne 的調度器不會使用準備隊列,它會持續檢查當前 CPU 上的所有活躍線程直到發現可以運行的線程,因為以下的兩個原因,這個看起來非常簡單的輪訓機制實際上非常高效:
在同一時間,單個 CPU 上應該只會包含少數幾個線程上下文;
當前線程一定會由其他核心喚醒,因為跨核的傳輸會帶來緩存丟失,而在觸發緩存丟失時可以并行掃描全部上下文不會帶來過大的開銷;
因為線程可能處于阻塞狀態等待特定的執行條件滿足,所以上下文中會包含 wakeupTime,即線程多久后需要被喚醒;線程可以通過 block(time) 和 signal(thread) 兩個方法改變 wakeupTime 通知調度器當前線程的狀態和喚醒時間。
核心策略
為了能夠讓應用程序對 CPU 有更細粒度的控制,Arachne 不會在運行時中指定 CPU 的使用策略,如何使用 CPU 都是由獨立的策略模塊確定的,Arachne 中的一些默認核心策略如果不能滿足應用程序的需求,它們還可以實現一些自定義的策略滿足特定的需求。
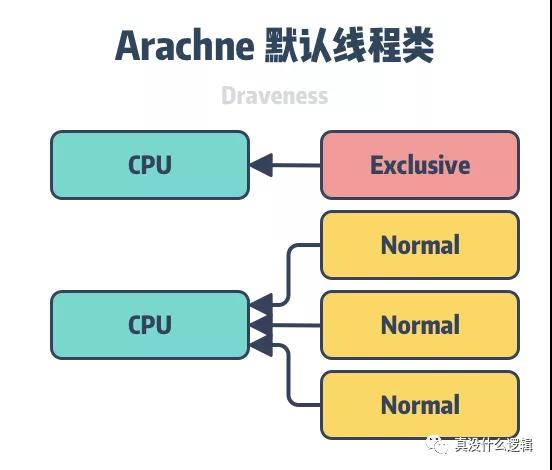
圖 6 - 線程類
與 Linux 調度器中的調度類比較相似,當應用程序創建新的用戶線程時,它需要指定該線程的類,核心策略會根據調度類選擇 CPU 執行。默認的核心策略中包含兩個線程類,分別是獨占的(Exclusive)和正常的(Normal),前者會為線程保留整個 CPU 資源,而后者會在多線程之間分享資源。
資源預估
默認的核心策略中包含動態的 CPU 資源預估功能,它會使用以下的三個參數根據過去一段時間的負載和 CPU 使用情況調整當前應用程序申請的資源:
- 負載因子(Load Factor) — 當運行正常線程的所有 CPU 負載達到特定的閾值時,向仲裁者申請額外的 CPU;
- 時間間隔(Interval) — 用于預估占用資源的 CPU 采樣區間,默認為過去的 50ms,這可以決定策略對負載變換的敏感程度;
- 滯后因子(hysteresis Factor) — 記錄每次提升負載前的資源利用率,并根據該利用率減少申請的 CPU 資源;
作為 Arachne 中的默認策略,它提供的一定是相對簡單的、普適的模型,我們可以根據自己的需求調整策略中的三個參數,也可以實現其他的策略。
總結論文的最后在線程的創建、控制權轉移等常見的調度原語方面對比了 Arachne、std::thread、Go 和 uThreads 幾種具有相似功能的線程管理器,Arachne 在幾個方面都有不錯的表現:
| Benchmark | Arachne | std::thread | Go | uThreads |
|---|---|---|---|---|
| Thread Creation | 217 ns | 13329 ns | 444 ns | 6132 ns |
| One-Way Yield | 93 ns | - | - | 79 ns |
| Null Yield | 12 ns | - | - | 6 ns |
| Condition Notify | 281 ns | 4962 ns | 483 ns | 4976 ns |
| Signal | 282 ns | - | - | - |
表 1 - 調度原語的開銷對比
正如我們在文章中提到的,Arachne 與其他線程管理器使用了完全不同的設計思路,因為我們的目的是充分利用 CPU 資源,所以應用程序需要對資源有著更細粒度的掌握和控制,其他的線程管理器都會盡可能地屏蔽底層的實現細節,讓上層只關注內部的一些邏輯,我們從軟件工程的角度也不能說誰對誰錯,但是在真正追求極致的性能時,一定清楚對下一層甚至下兩層的信息,在線程調度器這個場景下就是 CPU 資源的詳細使用情況。
本文轉載自微信公眾號「 真沒什么邏輯」,可以通過以下二維碼關注。轉載本文請聯系 真沒什么邏輯公眾號。

















