Facebook 集群調度管理系統 · OSDI 2020
『看看論文』是一系列分析計算機和軟件工程領域論文的文章,我們在這個系列的每一篇文章中都會閱讀一篇來自 OSDI、SOSP 等頂會中的論文,這里不會事無巨細地介紹所有的細節,而是會篩選論文中的關鍵內容,如果你對相關的論文非常感興趣,可以直接點擊鏈接閱讀原文。
本文要介紹的是 2020 年 OSDI 期刊中的論文 —— Twine: A Unified Cluster Management System for Shared Infrastructure[^1],該論文實現的 Twine 是 Facebook 過去十年生產環境中的集群管理系統。在該系統出現之前,Facebook 的集群由為業務定制的獨立資源池組成,因為這些資源池中的機器可能有獨立的版本或者配置,所以無法與其他業務共享。
Twine 的出現解決了不同資源池中機器配置不同的問題,提供了動態配置機器的功能,這樣可以合并原本獨立的資源池,提高資源整體的利用率,在業務申請資源時可以根據需要配置機器,例如:改變內核版本、啟用 HugePages 以及 CPU Turbo 等特性。
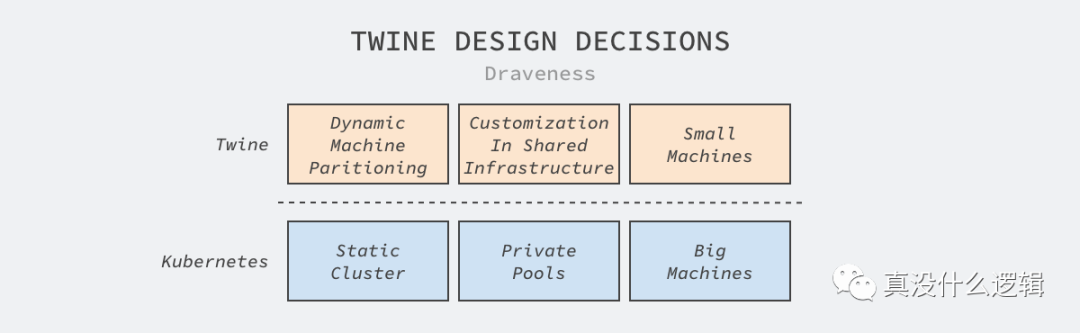
圖 1 - Twine 設計決策
Kubernetes 是今天十分熱門的集群管理方案,不過 Facebook 的方案 Twine 卻做出了與 Kubernetes 相反的決策,實現了截然不同的解決方案。需要注意的是使用 Kubernetes 并不一定意味著要使用靜態集群、私有節點池和大容量機器,我們仍然可以通過引入其他模塊實現動態集群等特性,只是 Kubernetes 本身不支持這些設計。我們在這篇文章中僅會討論上述三大決策的前兩個以及 Twine 如何實現水平擴容、管理大規模的集群。
架構設計
作為可以管理上百萬機器、支撐 Facebook 業務的核心調度管理系統,Twine 的生態系統非常復雜,我們在這里簡單介紹該系統中的一些核心組件:
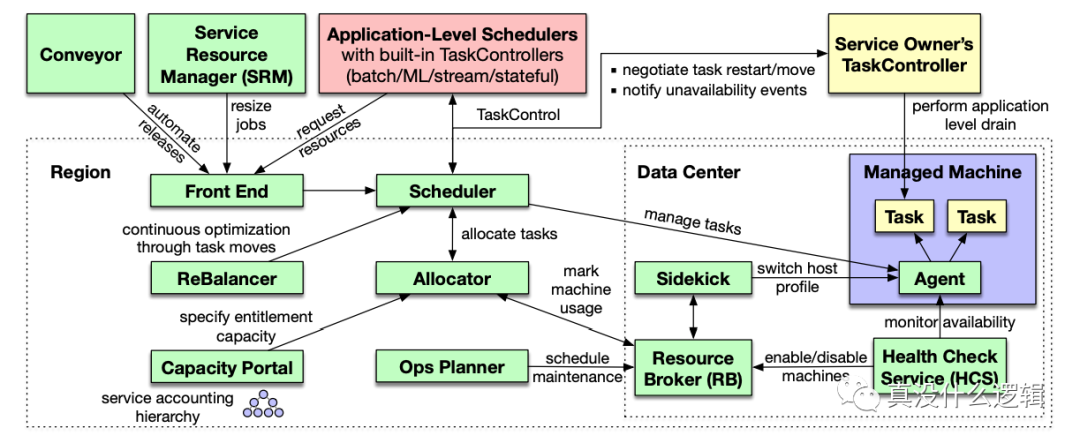
圖 2 - Twine 生態系統
分配器(Allocator):對應 Kubernetes 中的調度器,負責為工作負載分配機器,它在內存中維護了所有機器的索引和屬性并使用多線程處理資源的調度分配;
調度器(Scheduler):對應 Kubernetes 中的控制器,它負責管理工作負載的生命周期,當集群出現硬件故障、日常維護等情況時會推動系統做出響應;
應用程序調度器(Application-Level Schedulers):對應 Kubernetes 中的 Operator,如果我們想使用特殊的邏輯管理有狀態服務,需要實現自定義的調度器;
分配器、調度器和應用程序調度器是 Twine 系統中的核心組件,然而除了這些組件之外,生態中還包含前端界面、優化集群工作負載的平衡器和指定特定業務容量的服務。在了解這些具體組件之后,這里我們圍繞文章開頭提出的動態集群和自定義配置展開討論 Twine 的設計。
動態集群
Twine 的動態集群建立在其抽象出的權利(Entitlement)上,每個權利集群都包含一組動態分配的機器、屬于特定業務的偽集群。數據中心中的機器和任務之間建立其的這層抽象使機器的分配變得更加動態:
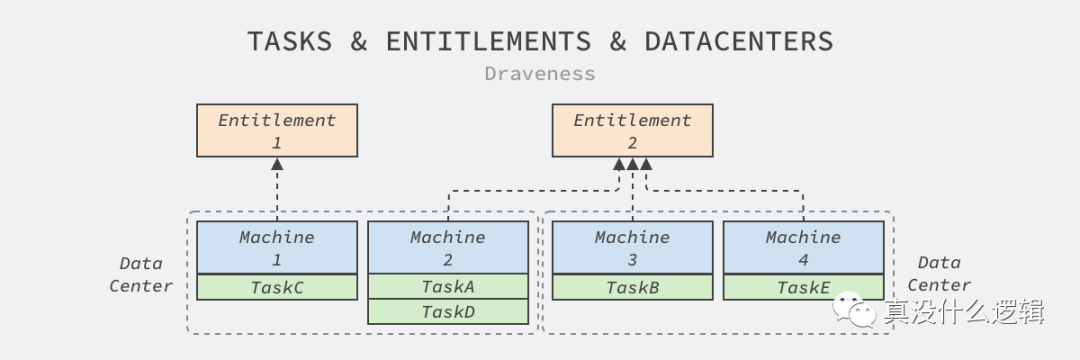
圖 3 - 任務、權利和數據中心
分配器不僅會將機器分配給權利集群,還會把同一個權利集群中的工作負載調度到特定的機器上。
需要注意的是,我們在這里簡化了 Twine 中的模型,Facebook 的數據中心會由幾十個主配電板(Main Switchboard、MSB)組成,它們具有獨立的電力供應和網絡隔離,配電板上的機器可以看做屬于同一個集群。
自定義配置
私有的節點池很不利于機器的共享,但是確實有很多業務對機器的內核版本和配置有要求,例如:很多機器學習或者數據統計的任務都需要使用 Linux 的 HugePages 優化性能,但是 HugePages 可能會損害在線服務的性能。
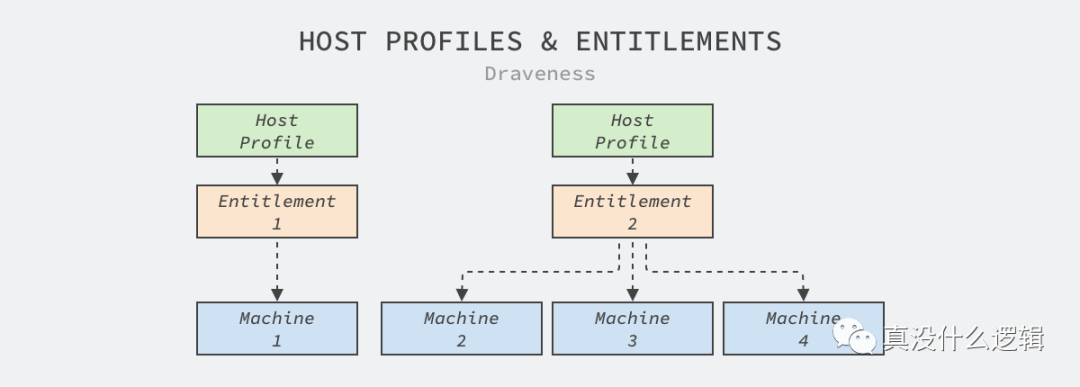
圖 4 - 主機配置
Twine 由此引入了主機配置的概念,為每個權利集群綁定獨立的主機配置,當數據中心的機器被分配到某個偽集群時,會根據集群的配置更新機器,為工作負載提供最符合需求的運行環境,這在 Facebook 內將 Web 層的服務性能提高了 11%,也是目前的 Kuberentes 無法滿足的。
集群規模
Facebook 的集群規模也是目前世界領先的,雖然目前的集群規模還沒有突破百萬級,但是隨著業務的快速發展,Twine 很快就需要支持百萬級別的物理機管理,它會通過下面兩個原則支撐這個數量級的節點:
通過按照權利集群分片的方式水平擴容;
通過分離關注點減少調度系統的工作量;
分片
分片是集群或者系統想要實現水平擴容的最常見方式,Twine 為了支持水平擴容就以權利集群的維度分片;作為虛擬集群,Twine 可以在分片之間遷移權利集群,不需要重啟機器上的任務,然而跨權利集群的遷移就需要滾動更新的支持了。
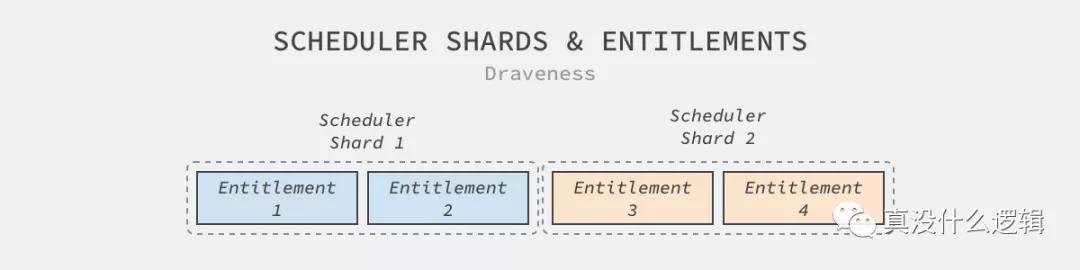
圖 5 - 調度器分片
通過分片,集群管理系統的水平擴容就變得非簡單,而 Twine 最大的分片中管理了 170,000 臺機器,這與 Kubernetes 能夠支持 5,000 節點相比有將近兩個數量級的差距。
除了分片之外,聯邦也是解決集群管理規模的有效手段,Kubernetes 社區的聯邦可以讓同一個任務在多個獨立集群運行,可以支持多地區、混合云甚至多云的部署,但是因為需要跨集群同步信息,所以實現相對比較復雜;Twine 的調度器可以在分片中的機器不足時動態遷移新的機器,所以可以使用單個調度器管理一個服務的所有副本。這里就不討論兩種方案的優劣了,各位讀者可以自行思考,不過作者還是傾向于通過的聯邦管理多個集群。
分離關注
Kubernetes 是一種中心化的架構,所有的組件都會從集群中的 API 服務器讀取或者寫入信息,所有的數據都存儲在獨立的持久存儲系統中,而中心化的架構和存儲系統也成為了 Kubernetes 集群管理的瓶頸。
Twine 在設計上盡量避免了中心化的存儲系統并分離原本屬于單個組件的職責,拆分到了調度器、分配器、資源代理、健康檢查服務和主機配置服務中,每個服務也有獨立的存儲系統,這就能夠避免單存儲系統帶來的擴容問題。
總結
在 Kubernetes 大行其道的今天,能夠看到 Facebook 分享其內部集群管理系統的不同設計還是有很大意義的,這讓我們重新思考 Kubernetes 中設計帶來的潛在問題,例如:中心化的 etcd 存儲,很多使用 Kubernetes 的大公司為了讓其能夠管理更多節點,都會選擇修改 etcd 的源代碼或者替換存儲系統。
Kubernetes 對于集群規模較小的公司還是有很大好處的,而其本身確實能夠解決集群管理中 95% 的問題,Kubernetes 也不是銀彈,它沒法做到解決場景內的全部問題。在應用 Kubernetes 時,中小規模的公司可以全盤接收 Kubernetes 的架構和設定,而大公司可以在 Kubernetes 的基礎上做一些定制,甚至參與到標準的制定中增加技術影響力、提高話語權并且幫助支撐公司業務成長。
[^1]: Tang C, Yu K, Veeraraghavan K, et al. Twine: A Unified Cluster Management System for Shared Infrastructure[C]//14th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 20). 2020: 787-803.
本文轉載自微信公眾號「真沒什么邏輯」,作者嵌入式系統。轉載本文請聯系真沒什么邏輯公眾號。