













如果機器學(xué)習(xí)失敗該怎么辦:計算學(xué)習(xí)理論
介紹
假設(shè)您已經(jīng)建立了一個面部識別模型,并且現(xiàn)在使用驗證集來調(diào)整測試集上的實驗參數(shù)。 可悲的是,您的實驗得出的測試結(jié)果令人失望。
我們?nèi)绾沃泪槍Υ颂囟▎栴}的優(yōu)秀的補救方法是什么?
首先了解假設(shè)提升問題,然后看看是否可以從衍生自該算法的AdaBoost算法的結(jié)果中提取實用原理,從而解決該問題。
線性預(yù)測器
線性回歸
線性回歸建模解釋變量或自變量與標量響應(yīng)或因變量之間的關(guān)系。
使用線性預(yù)測函數(shù)對關(guān)系進行建模。
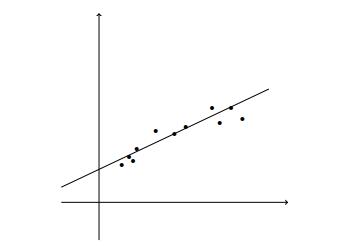
> Linear Regression
回歸的損失函數(shù)需要定義由于我們的預(yù)測與標簽或目標的真實結(jié)果之間的差異而應(yīng)受到的懲罰。
均方誤差使用平方損失函數(shù)來最小化此差異。
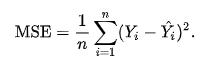
> Mean Squared Error
其中n是預(yù)測數(shù),Y是被預(yù)測變量的觀測值,而Ŷ是預(yù)測值。
一些學(xué)習(xí)任務(wù)需要非線性預(yù)測器,例如多項式預(yù)測器。
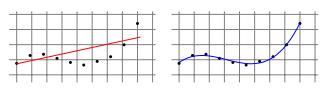
> Linear Regression for Polynomial Regression Tasks
通過使用最小二乘算法找到系數(shù)的優(yōu)秀矢量,可以將這個問題簡化為線性回歸問題,該算法最小化了曲線上各點的偏移的平方和("殘差")。
邏輯回歸
在邏輯回歸中,我們學(xué)習(xí)對間隔[0,1]上存在的某個類別或事件的概率進行建模。
邏輯函數(shù)是一個S型函數(shù),它接受任何實際輸入,并輸出一個介于0和1之間的值。
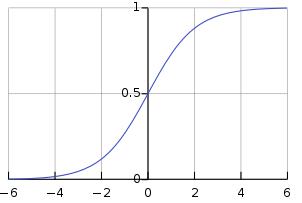
> Sigmoid function
如果此處的學(xué)習(xí)失敗,我們可以嘗試增強以解決偏差-偏差權(quán)衡問題。
假設(shè)提振問題
"一組弱學(xué)習(xí)者可以創(chuàng)造一個單一的強學(xué)習(xí)者嗎?" —邁克爾·科恩斯(Michael Kerns)和萊斯利·加布里埃爾·萊斯(Leslie Gabriel Valiant)
Boosting使用線性預(yù)測變量的泛化來解決以下問題:
偏差-方差權(quán)衡
讓我們定義一些術(shù)語:
- 近似誤差是我們先驗知識的誤差,或者是我們的算法以何種概率輸出最佳答案。
- 估計誤差是我們的算法將預(yù)測看不見數(shù)據(jù)的結(jié)果的誤差。
候選模型越復(fù)雜,近似誤差越小,但是估計誤差越大。
通過使學(xué)習(xí)者從可能具有較大近似誤差的簡單模型開始,發(fā)展為使近似誤差和估計誤差均最小的模型,Boosting使學(xué)習(xí)者可以控制此折衷。
學(xué)習(xí)的計算復(fù)雜性
提升可以提高弱勢學(xué)習(xí)者或簡單算法的準確性,而簡單算法的性能要比隨機猜測好一點。 這個想法是試圖將弱學(xué)習(xí)者轉(zhuǎn)變?yōu)閺妼W(xué)習(xí)者,以便產(chǎn)生一個與難以學(xué)習(xí)和計算復(fù)雜的學(xué)習(xí)者相當(dāng)?shù)母咝ьA(yù)測器。
自適應(yīng)提升
AdaBoost(自適應(yīng)增強)是一種基于理論假設(shè)增強問題的算法,該算法將假設(shè)的線性組合與檢測圖像中人臉的單個假設(shè)組成。
AdaBoost的偽代碼,

> AdaBoost pseudocode
對于指定的回合數(shù),AdaBoost算法分配權(quán)重,該權(quán)重與每個假設(shè)的誤差成反比。 然后在假設(shè)正確的情況下更新此權(quán)重,這將獲得較低的概率權(quán)重,而與假設(shè)不正確的示例相反。 這是針對多個回合執(zhí)行的,因此,在每個后續(xù)回合中,弱學(xué)習(xí)者會將注意力集中在有問題的樣本上。 然后,這會基于所有弱假設(shè)的加權(quán)總和產(chǎn)生一個"強分類器"。
其中T是訓(xùn)練回合的數(shù)量,h是弱學(xué)習(xí)者的運行時間,AdaBoost算法的運行時間有效地為O(Th)。
AdaBoost用于人臉識別
讓我們回到我們的示例,在此示例中,我們要構(gòu)建一個人臉識別模型,該模型采用24 x 24像素的圖像并使用該信息來確定圖像是否描繪了人臉。
我們將使用代表這四個基本假設(shè)的線性函數(shù),
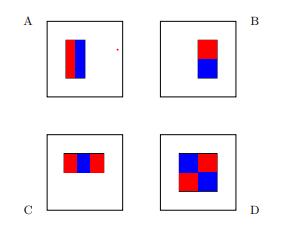
> Base hypotheses for face recognition
每個假設(shè)的功能形式包括:
- 軸對齊矩形R,最多24個軸對齊矩形
- A,B,C或D型
并將圖像映射到標量值。
為了計算我們的學(xué)習(xí)函數(shù),我們計算位于紅色矩形內(nèi)的像素的灰度值之和,然后從藍色矩形內(nèi)的像素的灰度值之和中減去該值。
我們可以通過首先在每個圖像上計算函數(shù)的所有可能輸出,然后應(yīng)用AdaBoost算法來實現(xiàn)弱學(xué)習(xí)者。 這導(dǎo)致強度在臉部區(qū)域中增長,這可能導(dǎo)致更好的預(yù)測。
模型選擇與驗證
我們已經(jīng)到了最終解決方案可以選擇幾種模型的地步。
解決我們特定問題的優(yōu)秀模型是什么?
我們可以將樣本劃分為訓(xùn)練集和測試集,以便在近似誤差和估計誤差之間找到平衡。 在訓(xùn)練模型時,我們將使用訓(xùn)練集,并且將使用獨立測試集來驗證模型,以獲取經(jīng)驗誤差。 這將使我們有直覺來了解我們是過度擬合,過于緊密地擬合我們的訓(xùn)練樣本,還是欠擬合而不充分地擬合我們的訓(xùn)練樣本。
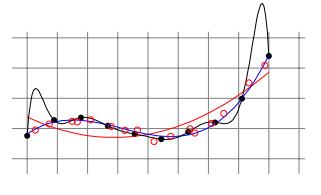
> Validation for model selection on polynomial regressors
近似誤差和估計誤差到底取決于什么?
首先定義一些術(shù)語:
- 讓我們的假設(shè)類別代表我們可以為機器學(xué)習(xí)算法選擇的所有可能假設(shè)的集合。
- 讓我們將分布定義為未知函數(shù),該函數(shù)確定從樣本空間進行任何單獨觀察的真實概率。
我們的近似誤差取決于分布和假設(shè)類別。 增加假設(shè)類別或使用其他特征表示可能會為我們提供一些替代知識,這些知識可能會改善近似誤差。
我們的估計誤差取決于訓(xùn)練樣本量。 為了改善估計誤差,我們必須有足夠數(shù)量的訓(xùn)練樣本。 較大的假設(shè)類別通常會增加估計誤差,因為這會使找到良好的預(yù)測變量更加困難。 AdaBoost算法的結(jié)果是產(chǎn)生一個"強分類器",該分類器基于所有弱假設(shè)的加權(quán)和,從本質(zhì)上減少了假設(shè)類別。
結(jié)論
從線性回歸到自適應(yīng)提升向我們展示了一個示例,說明如何解決學(xué)習(xí)成績差的問題是模棱兩可的。
模型選擇,驗證和學(xué)習(xí)曲線是我們可以用來幫助我們了解學(xué)習(xí)失敗的原因以便找到補救措施的工具。
很好地總結(jié)了以下原則,這些原則直接來自對機器學(xué)習(xí)的理解:從理論到算法:
1.如果學(xué)習(xí)涉及參數(shù)調(diào)整,請繪制模型選擇曲線以確保適當(dāng)調(diào)整了參數(shù)。
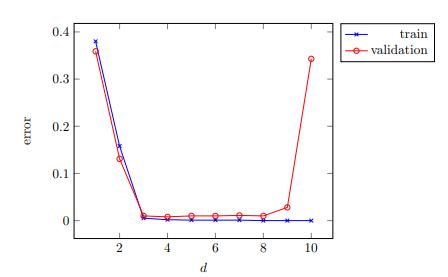
> Model-selection curve
2.如果訓(xùn)練誤差過大,請考慮擴大假設(shè)類別,完全更改它,或更改數(shù)據(jù)的特征表示。
3.如果訓(xùn)練誤差較小,則繪制學(xué)習(xí)曲線并嘗試從中推斷出問題是估計誤差還是近似誤差。
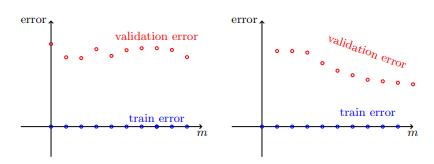
> Learning curves : estimation error vs approximation error
4.如果近似誤差似乎足夠小,請嘗試獲取更多數(shù)據(jù)。 如果這不可能,請考慮降低假設(shè)類別的復(fù)雜性。
5.如果近似誤差似乎也很大,請嘗試完全更改假設(shè)類別或數(shù)據(jù)的特征表示。















