遍覽200多個機器學習工具后,我學到了啥
大數據文摘出品
來源:huyenchip
編譯:Fisher、Andy
因為機器學習研究的放緩,以及大家對產業化的需求。近來大家對MLOps的關注越來越高,特別是其中涉及到的各種各樣的工具。
在這篇文章中,Chip小哥統計了兩百多個機器學習相關工具,并且對整個該領域的發展和現狀進行了回顧,同時列出機器學習開發的難點特別是和傳統軟件開發的不同點,最后還特意討論了開源對該領域的影響。
最近,為了更好地了解機器學習領域工具的整體情況,我決定徹底調查每個能找到的人工智能/機器學習工具。整個過程中參考的資源包括:
- Full Stack Deep Learning
- LF AI Foundation landscape
- AI Data Landscape
- 各媒體評選出的AI創業公司榜單
- 推特和領英上收到的帖子回復
- 別人分享給我的工具列表(包括朋友、陌生人、風險投資人)
在篩掉只有應用程序的公司(如用機器學習提供商業分析的公司)、未處于積極開發中的工具,以及沒人用的工具后,最后剩下202個工具。
完整列表如下:
https://docs.google.com/spreadsheets/d/1OV0cMh2lmXMU9bK8qv1Kk0oWdc_Odmu2K5sOULS9hHQ/edit?usp=sharing
如果有工具你覺得應該列入但未被列入,請務必在留言區補充!
免責聲明:
- 這個工具列表創建于19年11月,現在情況肯定不同了;
- 有些科技公司提供的一套工具數量太多,難以一一列舉,如Amazon Web Services提供超過165項功能齊全的服務;
- 有很多不知名的創業公司,我可能并不知道,甚至還有些都還沒聽說就倒閉了。
概述
我認為可以將機器學習生產流程歸納成4個主要步驟:
- 項目創建
- 數據管道
- 建模和訓練
- 上線服務
基于某個工具是服務于上述流程中哪個,我對工具進行了分類。我沒將項目創建部分包含進來,因為這一步需要的是項目管理工具,而不是機器學習工具。分類有時候并非簡單粗暴的,因為有些工具可能涉及多個步驟。而且這些工具模棱兩可的描述也讓人頭大:什么“我們突破了數據科學的極限”,“將AI項目轉化為現實世界的商業成果”,"讓數據像空氣一般自由流動",還有我個人最pick的一句:“我們生活于數據科學之上,呼吸于數據科學之中”。
對于涵蓋了流程中多個步驟的工具,我按照其最為人所知的功能來分類。有些工具多個分類的功能都為大家所熟悉,我就把它們都放在“一體化”(All-in-one)類中。我還增加了“基礎設施”(Infrastructure)這一類,來納入那些提供基礎設施來訓練和存儲模型的公司,它們大部分都是“云”提供者。
整體發展歷程
對此,我記錄了每個工具推出的年份。對于開源項目,我通過查看首次提交時間來確定項目是何時公開的。對于公司,我在Crunchbase網站上查找它的創立年份。然后我繪制了各個類別工具數目隨時間的變化圖。

隨年份累加的工具數目圖:左上角圖例依次為一體化、數據管道、基礎設施、建模和訓練、提供服務。
正如所料,數據顯示該領域從12年才開始急速發展,正好伴隨著人們對深度學習的重新關注開始。
前AlexNet時期(12年之前)
直到11年,該領域都是以建模和訓練工具為主。一些框架現在還很流行(如scikit-learn),或影響了現在的框架(如Theano)。在12年之前創立并存活至今的工具,有的已上市(Cloudera、Datadog、Alteryx),有的被收購(Figure Eight),有的成為了圈內非常熱門的開源項目(Spark、Flink、Kafka)。
發展時期(2012年到2015年)
隨著機器學習圈開始了"使勁喂數據"玩法后,機器學習已經變成了數據主導的領域。看每年推出的各個類別工具數時,這點尤其明顯。15年,57%(82個中的47個)是數據管道工具。
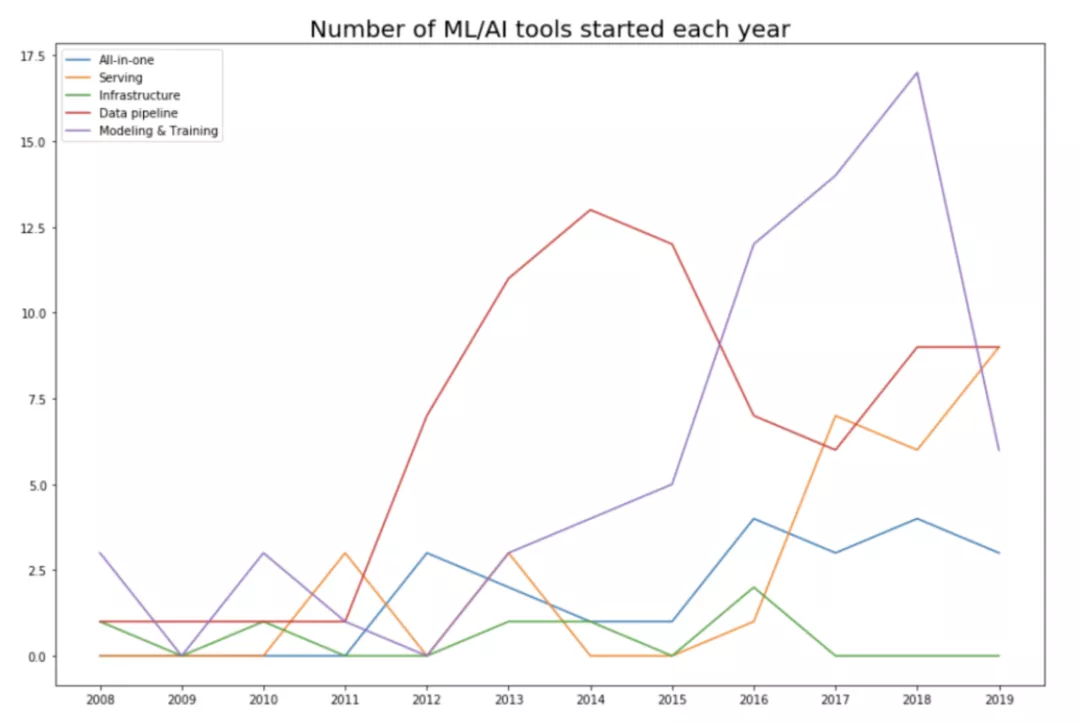
每年推出的各個類別的工具數。左上角圖例依次為一體化、提供服務、基礎設施、數據管道、建模和訓練。
產業化時期(2016年至今)
雖然純研究很重要,但大多數公司都負擔不起成本,除非研究能在短期就帶來商業應用。隨著機器學習的研究、數據和現成模型越來越易得,有更多的人和組織會想要直接找應用場景,這就增加了對機器學習產業化工具的需求。
在16年,谷歌宣布用神經機器翻譯來改進谷歌翻譯服務,這是深度學習在現實中的首批重要應用中一個。此后,大家開發了各種工具來幫助機器學習類應用部署上線。
整體發展現狀
盡管AI領域初創公司很多,但大多數是應用型的(提供商業分析或客戶支持等應用),而不是工具型的(打造工具來幫助其他公司開發應用)。或者用風投的行話來講,大多數創業公司都是垂直細分AI(Vertical AI)。在19年的福布斯“50家AI創業公司”榜單中,只有7家是工具型公司。
應用類更好銷售,因為你可以直接去一家公司推銷說:“我們可以讓你們一半的客戶支持業務自動化”。相比起來,雖然工具類要更長時間來銷售,但會產生更大影響,因為你不是關注單獨孤立的應用程序,而是關注整個生態的一部分。對于某一類應用,可以有多家供應商共存;但對于生態的一環,通常只有少數工具能存活下來。
這次,經過大量搜索后,我也只找到大約200個AI工具,和傳統軟件工程的工具數量相比還很少。比如,如果你想對傳統的Python應用做測試,2分鐘之內就能在谷歌上搜到至少20種工具。而如果你想對機器學習模型做測試,那一個可能也搜不到。
機器學習開發所面臨的問題
許多傳統的軟件工程工具都能用來開發或部署機器學習應用。但也有很多問題是機器學習應用特有的,所以也需要專門的工具。
在傳統的軟件工程中,寫代碼部分是難點。但在機器學習中,寫代碼只是整體的一小部分。開發一個新模型,而且對實際任務提供顯著提升,這不光難,成本也很高。所以大部分公司不會專注于開發模型,而是用現成模型,例如 “BERT大法解決一切”。
對于機器學習,一般有最多/最好數據的應用就是最好的。因此,大多數公司并不太專注于改進深度學習算法,而是專注于改善數據質量。由于數據可能會快速變化,所以機器學習應用也要求更快的開發和部署周期。在很多時候,你可能得每晚都部署一個新模型。
模型的大小也是一個問題。經過預訓練的大型 BERT 模型有340M個參數,占1.35GB空間。就算能裝在移動終端比如手機上,因為其推斷要花的時間太長,所以對很多應用場景也是沒意義的。比如,如果輸入法提示下一個字符所花時間比你直接輸入還要長,那相應的自動補全模型也就沒意義了。
Git通過逐行比較來進行版本管理,這對大多數傳統程序很有效。但它不適用于對數據集或模型做版本管理。對于大多數傳統數據框架的操作,Pandas就很好了,但它卻不能在GPU上跑。
基于行的數據格式(比如CSV)對于使用較少數據的應用效果很好。但如果你的樣本包含許多特征,而你只想用其中一個子集,那么基于行的數據格式仍需要先載入所有特征才行。像PARQUET和OCR這樣的列式文件格式對處理這種情況進行了優化。
機器學習應用開發所面臨的一些問題:
- 監測:如何得知你的數據分布發生了變化,然后重新訓練模型?例如:Dessa,由AlexNet的Alex Krizhevsky支持,于20年2月被Square收購。
- 數據標記:如何快速標記新數據或針對新模型重新標記現有數據?例如:Snorkel
- CI/CD測試:如何運行測試來確保模型在改動后仍能發揮預期作用?你不能每次都花幾天時間重新訓練直到收斂。例如:Argo。
- 部署:如何打包和部署一個新模型或替換掉一個現有模型?例如:OctoML。
- 模型壓縮:如何壓縮模型來適應終端設備?例如:Xnor.ai是從Allen Institute分拆出來的一家創業公司,專注模型壓縮。2018年5月,該公司以6200萬美元的估值得到1460萬美元融資。2020年1月,蘋果花了約2億美元收購了它,并關掉了它的網站。
- 推斷優化:如何加快模型的推斷時間?通過合并若干操作?通過降低模型精度?模型更小會讓推斷速度更快。例如:TensorRT。
- 邊緣設備:專門設計的硬件,使機器學習算法運行起來更快成本更低。例如:Coral SOM。
- 隱私:如何才能既通過用戶數據來訓練模型,同時又保護用戶隱私?如何才能使流程符合歐盟《通用數據保護條例》的要求?例如:PySyft。
下面這張圖里,橫坐標是這些工具設法解決的主要問題,縱坐標是針對特定問題的工具數量。
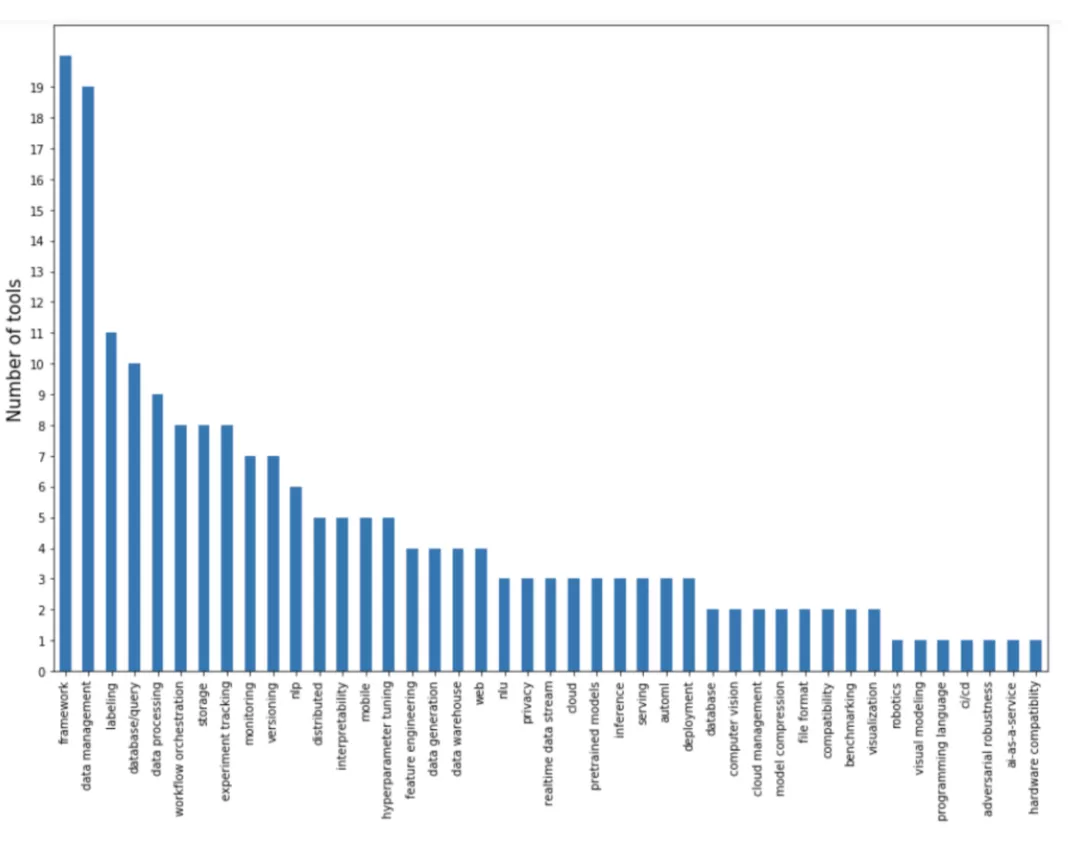
可以看出,很大一塊兒比例集中在數據管道方面:數據管理、數據標記、數據庫/查詢、數據處理、數據生成。這類工具可能志在發展成一體化平臺。因為數據處理是項目中最耗費資源的階段,一旦你讓人們把數據放到你的平臺上,你會很想用這些數據弄出一些預訓練模型什么。
而針對建模和訓練方面的工具大多是框架。深度學習框架的競爭現在差不多大局已定,主要是PyTorch和TensorFlow兩個框架,此外還包括基于這兩個框架的更高層次的框架,用于特定任務,比如自然語言處理(NLP)、自然語言理解(NLU)以及多模態問題。現在還有可以進行分布式訓練的框架。以及最近谷歌推出的新框架JAX,每個討厭TensorFlow的谷歌黨都對它夸夸不停。
還有一些獨立工具針對實驗追蹤,而流行框架內也有自己的實驗跟蹤功能。超參數調優很重要,所以有好幾個工具就專注于此,但好像沒有哪個被廣泛接受——因為超參數調優的瓶頸不在設置上,反而在調優過程中所需算力上。
留待解決的最令人興奮的問題是在部署和服務方面。缺乏服務解決方案的原因之一是研究人員和產品工程師之間缺乏溝通。在那些有能力進行AI研究的公司(一般是大公司),研究團隊與部署團隊是分開的,兩個團隊只通過帶有字母“p”各種經理溝通:產品經理(product managers)、項目經理(project managers),以及項目群經理(program managers)。小公司的員工可以看到全棧的情況,但受制于迫在眉睫的產品需求,也沒什么時間搞。只有少數創業公司設法填補這個空白,這些公司通常是由有為的研究人員創辦,而且有足夠資金來雇用熟練的工程師,隨時準備在AI工具市場上搶占份額。
開放源碼和開放內核
我查看的202種工具中,有109種是開源軟件。即使是不開源的那些,通常也有相伴的開源工具。
開源興盛有若干原因。其中一個原因是所有支持開源的人多年來一直在談論的:透明度、協作性、靈活性,而且這似乎成了道德規范。客戶可能不愿使用一個沒法看到源代碼的新工具。否則,一旦這個工具停止運營(初創公司里經常發生),就得悲劇地不得不重寫代碼。
當然,開源軟件并不代表非盈利和免費,其維護非常費時,而且昂貴。據傳TensorFlow團隊的規模接近1000人。公司在提供開源工具時必須得考慮其商業目標,例如,越多人使用他們的開源工具,就有越多人了解他們,信任他們的技術,并因此去購買他們的付費工具或想加入他們的團隊。
比如谷歌就希望推廣它的工具,好讓大家用它的云服務。英偉達維護著cuDF(以及之前的dask),這樣就能賣出更多GPU。Databricks免費提供MLflow,而同時在出售其數據分析平臺。就在最近,Netflix組建了專門的機器學習團隊并發布了他們的Metaflow框架,此舉使他們進入機器學習領域,得以招攬人才。Explosion免費提供SpaCy,但對Prodigy收費。HuggingFace免費提供transformers,但我還不知道他們怎么賺錢的(哈哈哈,良心企業)。
由于開源軟件已經成了一種標準,初創公司要找到一種行之有效的商業模式還是挺難的。因為任何一家公司創立后都必須與現有開源工具競爭。如果你遵循開放內核的商業模式,那就必須決定哪些功能放在開源版本里,哪些放在付費版本里,而且還不顯得吃相太難看;或者琢磨如何讓免費用戶開始付費。
結論
一直以來都有很多討論,討論AI泡沫是否會破滅。現今AI投資的很大一部分是在自動駕駛汽車上。由于完全自動駕駛離商業化還比較遙遠,所以有人猜測投資者會對AI行業徹底失望。加上現在谷歌已經停止了機器學習研究員的招聘,而Uber裁掉了AI團隊一半的研究人員。這兩家公司的決定都是在新冠疫情前做出的。有傳言稱,由于大量的人在上機器學習課,所以這方面的技術人員將會飽和。
現在還是進入機器學習領域的好時機嗎?我相信對人工智能的炒作確實存在,而且是時候冷靜下來了。但我不認為機器學習領域會消失,雖然有能力做機器學習研究的公司可能會減少,但那些需要各種工具把機器學習整合產業化的公司還是一直需要的。
如果你必須在工程師和機器學習專家之間選擇的話,那我建議你選擇工程師吧。優秀的工程師更容易掌握機器學習知識,但機器學習專家要成為優秀的工程師就難多了。如果你成了一名工程師,為機器學習領域開發出很棒的工具,我也會永遠感激你的!
相關報道:https://huyenchip.com/2020/06/22/mlops.html
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】