MIT再爆知名數據集ImageNet存在系統性Bug,禍端還是WordNet
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
近日,麻省理工學院研究團隊發表了一篇論文指控知名數據集ImageNet存在系統性Bug,該論文還被國際機器學習大會ICML2020接收。
同時,這篇論文名為《From ImageNet to Image Classification: Contextualizing Progress on Benchmarks》,也發表在了在預印論庫arXiv上。
慘遭下架后,MIT再爆知名數據集ImageNet存在系統性Bug,禍端還是WordNet
麻省理工研究團隊之所以在ICML大會上介紹這項研究,是因為近期陷入的“Tiny Images”爭議事件。
就在本月初,麻省理工學院(MIT)宣布永久刪除了包含8000萬張圖像的Tiny Images數據集,并公開表示歉意。其原因是,有關研究人員發表了一篇論文指控Tiny ImageNet數據集存在多項危險標簽,包括種族歧視、性別歧視、色情內容等,而且指控有理有據。
論文中表明,ImageNet在語義結構分析上,使用的WordNet名詞,它包含了種族歧視等危險內容,同時,由于圖像過小,數據量過大,并未手動對圖像標簽進行逐一核對,由此導致了問題的出現。
眾所周知,知名數據集ImageNet也使用了WordNet用于語義結構分析,那么,ImageNet數據集是否也存在同樣的問題?對此,麻省理工研究團隊給出了答案。
ImageNet基準測試與實際不符
大規模ImageNet數據集的出現,可以說意味著機器學習深度變革的一個新起點。2009年,李飛飛領銜的研究團隊在計算機視覺與識別模式大會(CVPR)上首次推出ImageNet,ImageNet數據集包含10000個分類,超過一百萬個圖像,數據量之大是此從未有過的。
正是因數據量大、質量高,ImageNet數據集被廣泛用于預訓練和基準測試。但是,麻省理工研究團隊在最近的研究中卻指出:
ImageNet存在明顯的“系統標注問題”,導致其用作基準數據集時與實際情況并不一致。
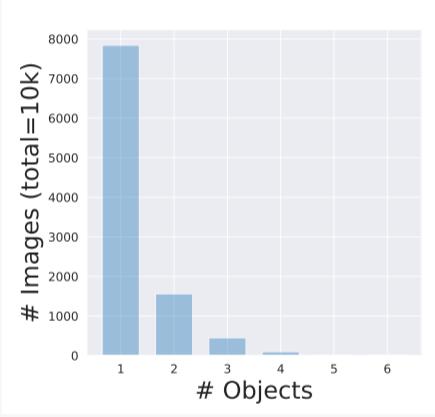
他們發現,ImageNet數據集中大約有20%的圖像包含兩個或更多的對象目標。
慘遭下架后,MIT再爆知名數據集ImageNet存在系統性Bug,禍端還是WordNet
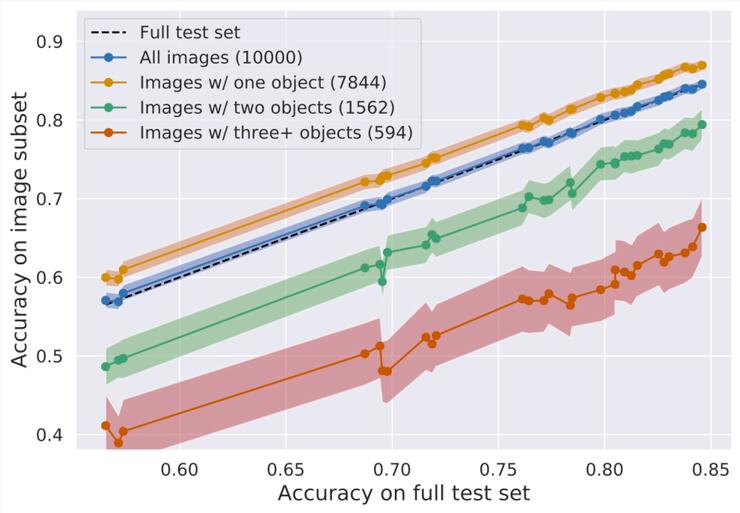
在通過對多個目標識別模型進行分析后,數據表明包含多個對象目標的照片會導致總體基準的準確性下降10%。
慘遭下架后,MIT再爆知名數據集ImageNet存在系統性Bug,禍端還是WordNet
簡單舉個栗子:假如此圖是ImageNet數據集中的一張高清圖像,我們可以看到圖片中不止包含了一個對象目標,有女孩、吉他和唱麥,而且圖片的主目標應該是女孩。
慘遭下架后,MIT再爆知名數據集ImageNet存在系統性Bug,禍端還是WordNet
但ImageNet的數據標簽可能不是女孩,也可能是唱麥或者吉他,重要的是ImageNet只會標注一個標簽,而這樣就可能會導致ImageNet在目標識別中出現失誤。
研究人員在論文中表明,
“總體而言,單個ImageNet標簽可能不能總是捕獲到ImageNet圖像的主要表物體目標。但是,當我們進行培訓和評估時,卻將標簽視為圖像的根本事實,因此,這可能會導致ImageNet基準測試與現實世界中的對象識別任務之間出現不一致,而且這在模型執行和評估性能方面都是如此。”
看到這里你可能會疑惑,為什么不能準確對圖像進行標記?其實問題的關鍵在于ImageNet所使用的標記工具WorldNet。
WordNet名詞標記是關鍵
WordNet在1980年代由George Armitage Miller創立,被廣泛用于數據集的收集和標記過程。簡單的理解,ImageNet會根據WorldNet提供的名詞和它的語義層次結構,在搜索引擎或者Flickr之類的網站進行圖像搜索,作為數據集的初始來源。
當WordNet提供一個名詞后,根據它設定的語音層次結構,ImageNet需要對該名詞的父類節點同義詞進行擴充,并以此作為搜索的關鍵詞。比如“ whippet”分類名詞(父類節點為:“dog”)的搜索還會包括“ whippet dog” 。
這類似于我們經常看到的“相關搜索”。為了進一步擴展圖像池,數據集創建者還會使用多種語言進行了搜索。
但這里的重點是,對于每個檢索到的圖像已經確定了標簽,如果該標簽包含在數據集中,則將分配給該圖像。也就是說,標簽僅由用于相應搜索查詢的WordNet節點給出。
而在這一過程中,WordNet的語義結構會將非主要目標的圖像納入數據集中,進而出現上文提到標記偏差。如論文中的數據顯示,同一分類標簽卻出現了不同的物體目標。(如圖)
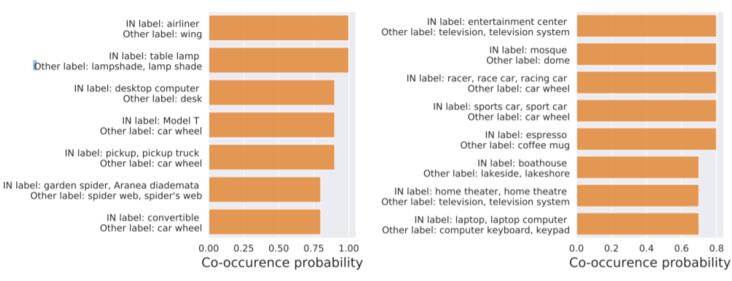
慘遭下架后,MIT再爆知名數據集ImageNet存在系統性Bug,禍端還是WordNet
既然如此,那為什么WordNet名詞還能夠廣泛應用于數據集創建過程中呢?
一方面是因為WorldNet可以完成大量數據的自動標記工作。我們知道,所有數據集在使用前都要先完成標記任務,而一個優秀的數據集規模又是很大的,如果全部手動標記,難度非常高,而WorldNet卻可以很好的解決這一問題。
另一方面對于ImageNet而言,WordNet獲取的只是初始數據標簽,其準確性還需要通過相關模型進行再次驗證。總體來講,ImageNet數據集的創建過程,分為自動圖像收集(automated data collection)和眾包過濾(crowd-sourced filtering)兩個階段,而眾包過濾就是所謂的審核階段,它分為以下5個步驟:
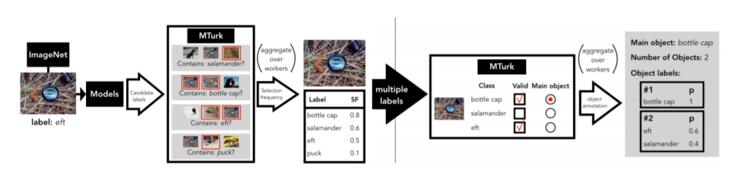
慘遭下架后,MIT再爆知名數據集ImageNet存在系統性Bug,禍端還是WordNet
- 潛在標簽(Candidate Labels):通過現有ImageNet圖像標簽與模型預測的前5個標簽進行組合,獲得每張圖像的潛在標簽。
- 選擇高頻率標簽(Selection Frequency):通過Mechanical Turk(MTurk)平臺,將潛在標簽與注釋內容對比,經過反復過濾循環后,出現頻率最高的為最佳標簽(一般少于5個)。
- CLASSIFY任務:給獲得的少量多標簽(Multiple labels)重新定義一組新的注釋內容,根據注釋信息為不同對象賦予標簽,并確定一個主要對象的標簽,這個過程稱為CLASSIFY。
- 對象注釋(Object Annotation):匯總以上訓練后,獲得更為細粒度的圖像注釋;
與原始ImageNet標簽相比,經過眾包過濾后生成的注釋能夠以更細粒度的方式表征圖像的內容,但研究者發現,這些注釋內容可能并沒有達到期待的效果,如下圖,CONTAINS任務會選擇多個標簽對圖像有效,而對于70%的圖像而言,注釋選擇的標簽頻率至少是ImageNet的原始標簽的一半。
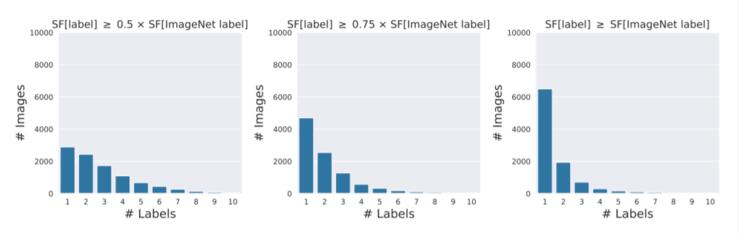
慘遭下架后,MIT再爆知名數據集ImageNet存在系統性Bug,禍端還是WordNet而且下圖表明,盡管只感知到單個對象,它們也經常會選擇多達10個類別標簽。因此,對于單一目標的圖像,ImageNet驗證過程也無法得到準確的標簽。
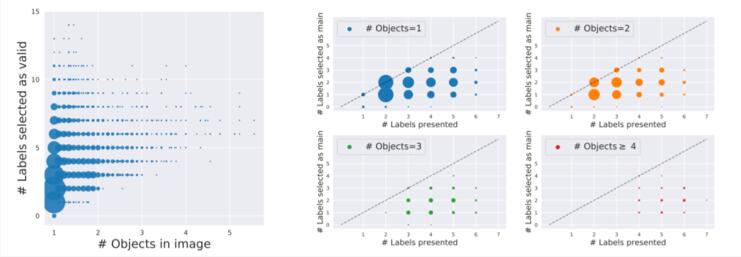
慘遭下架后,MIT再爆知名數據集ImageNet存在系統性Bug,禍端還是WordNet
因此,可以說圖像標簽在很大程度上依然取決于自動檢索(WorldNet)過程,同時眾包過濾的審查過程還有很大的提升空間。
對于未來如何優化數據集的創建任務,研究人員在論文中表明,我們認為開發注釋流程,尤其是審查階段以更好地捕獲基本事實,同時保持可擴展性是未來研究的重要途徑。”
涉嫌種族歧視,大規模數據集爭議不斷
作為人工智能技術的基礎,數據集在諸多研究領域都有著廣泛的使用場景,尤其是在計算機視覺領域。近些年,因數據集的使用引發的隱私泄露、種族歧視等問題接連不斷,導致人工智能技術的發展備受爭議。
除了近期麻省理工學院因涉嫌種族歧視而刪除了包含8000張圖像的Tiny Image數據外,此前,一款圖像修復算法PULSE,在學術圈同樣引起軒然大波。有網友發現,PULSE在修復馬賽克圖像時,將奧巴馬的人臉圖像變成了高分辨率的白人,這一事件引起了黑人網友的不滿。
對此,圖靈獎之父Lecun發表twitter稱,訓練結果存在種族偏見,是因為數據集本身帶有偏見,工程師在使用過程中應該注意這一點。
今年因數據集而引發種族歧視事件頗多,而解決這些數據集爭議,無非是從數據收集和標記階段進行改進。研究人員稱,對于大型數據集,理想的方法是按指定目標在全世界范圍內收集圖像,并讓專家按確切類別進行手動篩選和標記。這里需要注意的是,非專家的人工標記也可能出現錯誤。
但從當前來看,這種方法非常不切實際。事實上,諸如ImageNet此類數據集均是從互聯網搜索引擎抓取的圖像,質量參差不齊,而圖像審查不夠嚴謹。同時大量數據的專家手動標記也很難實現。不過,如本次研究所稱,可以通過技術進一步改善圖像自動審查的過程來提高數據集的質量。
此外,目前學術界已經越來越關注數據集相關缺陷問題,在本月初計算機語言協會(ACL)還重點討論了這一問題。