機器人懂點「常識」,找東西快多了:CMU打造新型語義導航機器人
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
想讓機器人像人一樣思考,似乎一直是個難題。
例如,讓機器人去拿放在「植物」旁邊的遙控器,機器人幾乎立即檢測出了「植物」盆栽所在的位置,從而檢測到遙控器的存在。

項目已被ECCV 2020收錄,并獲得了居住地目標導航挑戰賽的第一名。
一起來看看實現的過程。
讓機器人「學點常識」
事實上,以往大部分采用機器學習訓練的語義導航機器人,找東西的效果都不太好。
相比于人類潛意識中形成的常識,機器人往往有點“死腦筋”,它們更傾向于去記住目標物體的位置。
但物體所處的場景往往非常復雜,而且彼此間差異很大(正所謂每個人的家,亂得各有章法),如果單純以大量不同場景對系統進行訓練,模型泛化能力都不太好。
于是,相比于用更多的樣本對系統進行訓練,這次研究者們換了一種思路:
采用半監督學習的方式,使用一種名為semantic curiosity(語義好奇心)的獎勵機制對系統進行訓練。

訓練的核心目的,是讓系統基于對語義的「理解」來確定目標物體的最優位置,換而言之,就是讓機器人“學點常識”。
舉個例子,通過理解冰箱和洗手間的差異,機器人就能搞懂目標物體和房間布局的關系,并計算出最容易找到某個物體的房間。(就像沙發通常會在客廳、而不是在洗手間)
一旦確定了物體最可能出現的地方,機器人就能通過導航,直接去往預計的位置,并快速檢測到目標物體的存在,這個過程被稱之為探索策略(exploration policy)。
采用Mask RCNN訓練探索策略
如下圖所示,策略的實現被分成了三步:學習、訓練、測試。
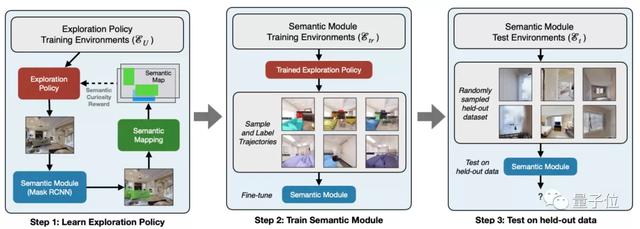
首先,采用Mask RCNN對圖像從上至下進行目標預測,用于訓練探索策略,后者負責生成目標檢測和場景分割所需的訓練數據。
對訓練數據進行標記后,數據會被用于微調和評估目標檢測及場景分割的效果。
在目標檢測的過程中,即使面對某一物體的鏡頭轉360度,機器人也必須將之識別為同一種物體。
這其中最關鍵的一個步驟,在于構造語義地圖。
構造「有魔法的」地圖
從下圖可見,圖像被處理成RGB和Depth兩種模式。
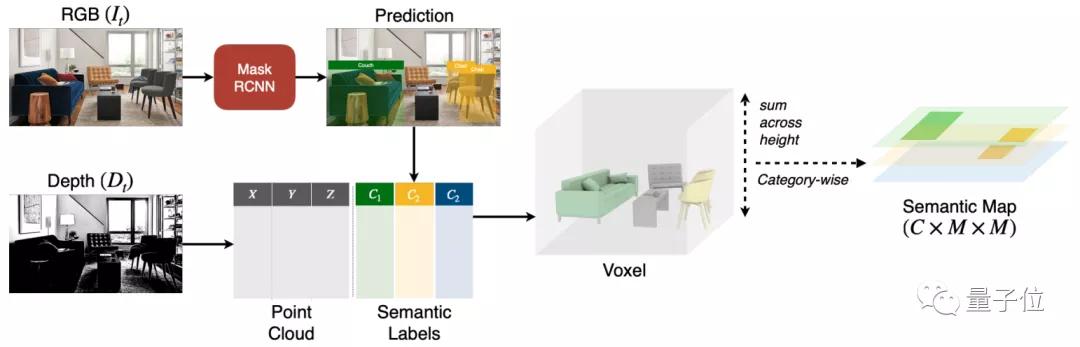
其中,RGB圖像會通過Mask RCNN網絡,用于獲得目標分割預測。
而Depth架構,則被用于計算點云,其中的每個點,都會在Mask RCNN的預測結果基礎上與語義標簽進行關聯。
最后,基于幾何計算,會在空間中會生成一個三維立體圖。
每一個通道用于表示一種物體類別,原本2D的地圖就會轉變成一個3D的語義地圖。
有了語義地圖,機器人在移動時也能準確地對3D空間進行目標預測了。
「語義好奇心」獎勵機制
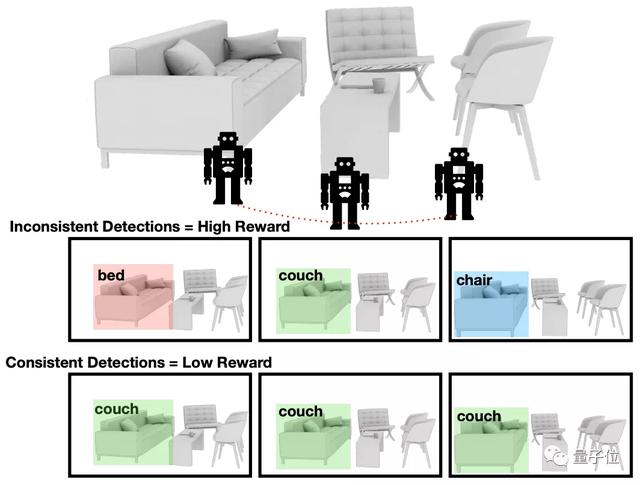
不過,這會出現一種情況,如果目標物體在不同的幀上被預測的標簽不同,那么語義圖中對應這個物體的多個通道都會是1。
如下圖,不同的時間,系統預測的目標標簽可能并不一樣,有時候是床,有時候則變成了沙發。

這就出現了語義好奇心的策略。
論文定義了語義好奇心累計獎勵(cumulative semantic curiosity reward),指占語義地圖中所有元素總和的比例。
而語義好奇心獎勵機制,則采用強化學習的方式,目的是使這個比例最大化。
通過了解物體之間的差異、從而了解房間布局,系統就會逐漸理解房間與物體的聯系。
實驗結果
事實證明,這種方法非常有效。
機器人在訓練過程中,可以專注地去理解目標物體與房間布局的關系,而非不停地進行路徑規劃。
訓練出的機器人,在人機交互方向上變得更加容易操控。
例如,在各種方法下,即使探索區域不及倒數第二和第三種方法,但語義好奇心仍然檢測出了相當的目標數量。
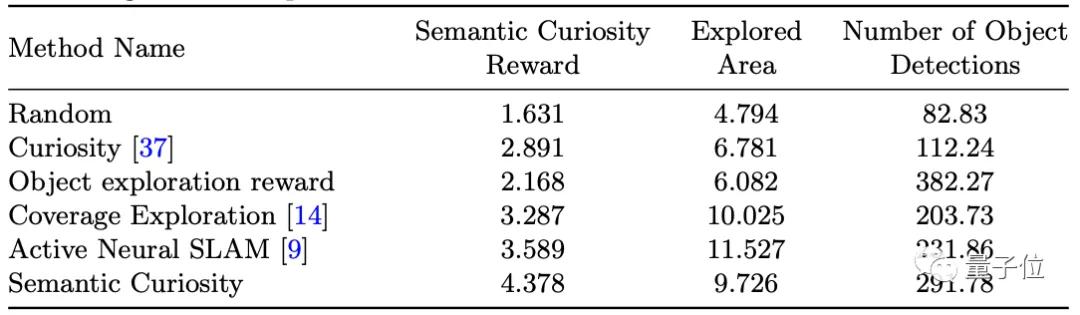
這說明它在進行目標檢測時,能更專注于所需要探測的物體。
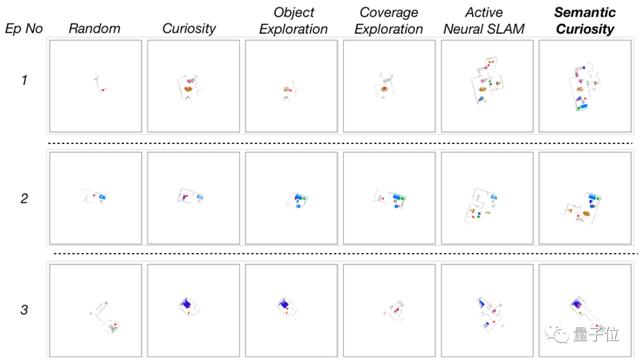
而從下圖可見,語義好奇心明顯發現了更多其他策略無法發現的物體,這對于檢測目標是非常有效的。
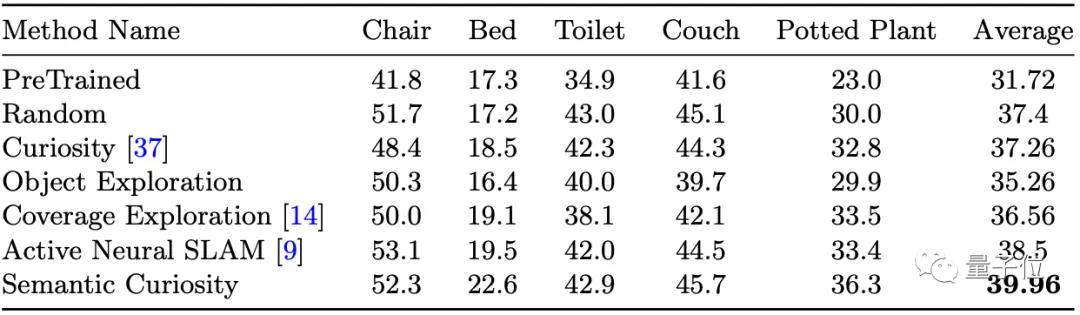
在最終的訓練結果中,語義好奇心拿到了最高的39.96分。
這個方法,使得人與機器人之間的交互也變得更加容易實現。
作者介紹
Devendra Singh Chaplot,在卡內基梅隆大學(CMU)讀博,主要研究深度強化學習、以及其在機器人和自然語言處理方向上的應用。
傳送門:
論文鏈接:https://arxiv.org/pdf/2006.09367.pdf
項目鏈接:https://devendrachaplot.github.io/projects/SemanticCuriosity