













在Apache Spark中執行聚合的五種方法

聚合是數據分析任務中廣泛使用的運算符,Spark為此提供了堅實的框架。 以下是使用Spark可以針對大數據進行聚合的五種不同方式。
RDD上的GroupByKey或ReduceByKey轉換:RDD是Spark中分布式數據收集的最早表示,其中數據通過" T"類型的任意Java對象表示。 RDD上的聚合與map-reduce框架中的reduce概念相似,在reduce中,reduce函數(作用于兩個輸入記錄以生成聚合記錄)是聚合的關鍵。 使用RDD時,聚合可以通過GroupByKey或ReduceByKey轉換來執行,但是,這些轉換僅限于Pair RDD(元組對象的集合,每個元組都由類型為" K"的鍵對象和類型為" V"的值對象組成) 。
在通過GroupByKey進行聚合的情況下,轉換會導致元組對象具有鍵對象和針對該鍵對象的所有值對象的集合。 因此,之后需要應用一個映射器(通過map,maptoPair或mapPartitions進行映射轉換),以便將每個Tuple對象的值對象的集合減少為一個聚合的值對象。
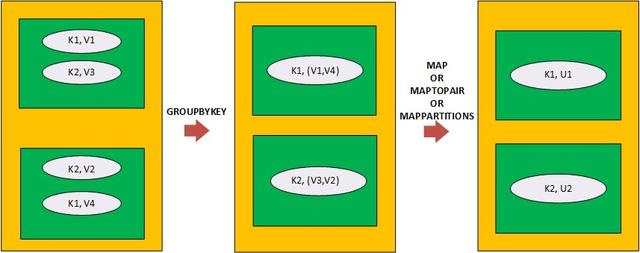
> Aggregation on a Pair RDD (with 2 partitions) via GroupByKey followed via either of map, maptopair
映射程序(例如map,maptoPair和mappartitions轉換)包含聚合函數,以將類型為" V"的值對象的集合減少為類型為" U"的聚合對象。 聚合函數可以是任意函數,不需要遵循關聯性或交換性狀。 GroupByKey轉換具有三種風格,它們因應用GroupByKey轉換而在RDD的分區規范上有所不同。 GroupByKey可以總結為:
- GroupByKey (PairRDD) => PairRDD> Map (PairRDD>) => PairRDD
如果通過ReduceByKey進行聚合,則轉換將直接導致具有鍵對象和針對該鍵對象的聚合對象的元組對象。 與GroupByKey一樣,在ReduceByKey之后不需要映射器。 ReduceByKey轉換采用關聯和可交換的聚合函數,以便在跨分區聚合記錄之前,可以在本地聚合位于同一分區的記錄。 同樣,聚合函數接受兩個說類型為" V"的值對象,并返回一個類型為" V"的對象。 與GroupByKey相似,ReduceByKey轉換也具有三種風格,它們的區別在于通過應用ReduceByKey轉換而導致的RDD分區規范。 ReduceByKey可以總結為:
- ReduceByKey(PairRDD, Function) => PairRDD
在GroupByKey和ReduceByKey中,前者更通用,可以與任何聚合函數一起使用,而后者則更有效,但僅適用于前面所述的一類聚合函數。
RDD或數據集上的Mappartitions:如先前博客中所述,Mappartitions是功能強大的窄轉換之一,可在RDD和Dataset(Spark中的數據表示)上使用,以明智地執行各種操作。 這樣的操作之一也包括聚合。 但是,唯一需要滿足的條件是,屬于相同分組關鍵字的記錄應位于單個分區中。 在涉及分組密鑰的混排操作中實現的RDD或數據集(要聚合)中可以隱式滿足此條件。 同樣,可以通過首先基于分組密鑰對RDD或數據集進行重新分區來明確實現該條件。
在用于典型聚合流的mappartitions內,必須首先實例化一個Hashmap,將Hashmap與相應的分組鍵相對應地存儲聚合的Value Objects。 然后,在迭代基礎分區的數據收集時,將重復更新此Hashmap。 最后,返回包含在映射中的聚合值/對象(可選以及關聯的分組鍵)的迭代器。
由于基于Mappartitions的聚合涉及將Hashmap保留在內存中以保存鍵和聚合的Value對象,因此,如果大量唯一分組鍵駐留在基礎分區中,則Hashmap將需要大量堆內存,因此可能導致 相應執行程序的內存不足終止的風險。 從此以后,不應該歪曲跨分區的分組密鑰分配,否則會由于過度提供執行程序內存來處理偏斜而導致執行程序內存浪費。 此外,由于需要基于堆內存的聚合哈希圖,因此與Spark中的專用聚合運算符相比,對內存的相對內存分配更多,但是如果內存不是約束,則基于Mappartitions的聚合可以提供良好的性能提升。
用于數據幀或數據集的UDAF:與上述方法不同,UDAF基于聚合緩沖區的概念以及在此緩沖區上運行的一組方法來實現聚合。
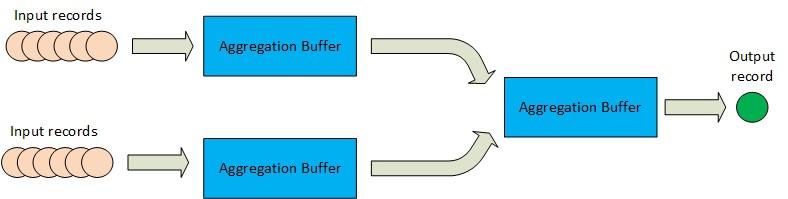
> Aggregation buffer based aggregation flow in Spark (for Datasets and Dataframe)
到目前為止,UDAF是為Spark中的分布式數據收集的Dataframe或Dataset表示編寫聚合邏輯的最常用方法。 UDAF在數據收集的無類型視圖上工作,在該視圖中,數據記錄被視為(表的)一行,其架構定義了該行中每一列的類型和可空性。 通過擴展包" org.apache.spark.sql.expressions"中存在的" UserDefinedAggregationFunction"類并覆蓋基類中以下方法的實現,可以在Spark中創建UDAF:
- /*Return schema for input column(s) to the UDAF, schema being built using StructType*/
- => public StructType inputSchema()
- /*Return schema of aggregation buffer, schema being built using StructType */
- => public StructType bufferSchema()
- /*DataType of final aggregation result*/
- => public DataType dataType()
- /*Initialize aggregation buffer*/
- => public void initialize(MutableAggregationBuffer buffer)
- /*Update aggregation buffer for each of the untyped view (Row) of an input object*/
- => public void update(MutableAggregationBuffer buffer, Row row)
- /*Update current aggregation buffer with a partially aggregated buffer*/
- => public void merge(MutableAggregationBuffer buffer, Row buffer)
- /*Evaluate final aggregation buffer and return the evaluated value of DataType declared earlier */
- => public Object evaluate(Row buffer)
除了覆蓋上述方法外,還可以始終聲明其他字段(在UDAF構造函數中使用可選的初始化)和自定義UDAF類中的其他方法,以便在覆蓋方法中使用它們以實現聚合目標。
在使用UDAF之前,必須先在Spark框架中注冊相同的實例:
- spark.udf.register('sampleUDAF, new SampleUDAF());
注冊后,可以在Spark SQL查詢中使用UDAF來聚合整個數據集/數據框或數據集/數據框中的記錄組(通過一列或多列分組)。 除了直接在Spark SQL查詢中使用外,還可以通過數據框/數據集聚合API(例如" agg")使用UDAF。
UDAF雖然是定義自定義聚合的一種流行方法,但是當在聚合緩沖區中使用復雜的數據類型(數組或映射)時,會遇到性能問題。 這是由于以下事實:在UDAF中的每次更新操作期間,對于復雜的數據類型,將scala數據類型(用戶特定)轉換為相應的催化劑數據類型(催化劑內部數據類型)(反之亦然)變得非常昂貴。 從內存和計算的角度來看,此成本都更高。
數據集的聚合器:聚合器是對數據集執行聚合的最新方法,類似于UDAF,它也基于聚合緩沖區的概念以及在該緩沖區上運行的一組方法。 但是,聚合器進行聚合的方式稱為類型化聚合,因為它涉及對各種類型的對象進行操作/使用各種類型的對象進行操作。 聚合器的輸入,聚合緩沖區和最終的聚合輸出(從緩沖區派生)都是具有相應Spark編碼器的某些類型的對象。 用戶可以通過使用為IN定義的類型(輸入記錄類型)擴展抽象的通用'Aggregator '類(在包'org.apache.spark.sql.expressions中提供)來定義自己的自定義Aggregator。 ,為BUF(聚合緩沖區)定義的類型和為OUT(輸出記錄類型)定義的類型,以及在基類中重寫以下方法的實現:
- /* return Encoder for aggregation buffer of type BUF. This is required for buffer ser/deser during shuffling or disk spilling */
- => public Encoder<BUF> bufferEncoder()
- /* return Encoder for output object of type OUT after aggregation is performed */
- => public Encoder<OUT> outputEncoder()
- /* return updated aggregation buffer object of type BUF after aggregating the existing buffer object of type BUF with the input object of type IN*/
- => public BUF reduce(BUF buffer, IN input) ()
- /* return updated aggregation buffer of type BUF after merging two partially aggregated buffer objects of type BUF */
- => public BUF merge(BUF buffer1, BUF buffer2)
- /* return output object of type OUT from evaluation of aggregation buffer of type BUF */
- => public OUT finish(BUF arg0)
- /* return buffer object of type BUF after initializing the same */
- => public BUF zero()
由于Aggregator本機支持將聚合緩沖區作為對象,因此它是高效的,并且不需要與從Scala類型轉換為催化劑類型(反之亦然)相關的不必要的開銷(與UDAF一樣)。 同樣,聚合器的聚合方式在編寫聚合邏輯時提供了更多的靈活性和編程的美感。 聚合器也已集成到無類型聚合流中,以支持SQL,例如即將發布的版本中的查詢。
預定義的聚合功能:Spark提供了各種預構建的聚合功能,可用于分布式數據收集的數據框或數據集表示形式。 這些預先構建的函數可以在SPARK SQL查詢表達式中使用,也可以與為Dataframe或Dataset定義的聚合API一起使用。 在org.apache.spark.sql包中,所有預先構建的聚合函數都定義為"函數"類的靜態方法。 帶下劃線的鏈接可以列出所有這些功能的列表。
預定義的聚合函數經過高度優化,在大多數情況下可以直接與Spark tungusten格式一起使用。 因此,如果" functions"類中存在預先構建的聚合函數,則Spark程序員應始終偏向于使用它們。 萬一那里沒有所需的聚合函數,那么只有一個可以訴諸于編寫自定義聚合函數。
如果您對Spark Aggregation框架有更多查詢,請隨時在評論部分提問。





















