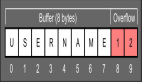
什么是緩沖區溢出以及如何利用漏洞
在信息安全和編程中,緩沖區溢出是一種異常,其中程序在將數據寫入緩沖區時會超出緩沖區邊界并覆蓋相鄰的內存位置。緩沖區是留出的用于存儲數據的內存區域,通常是在將數據從程序的一個部分移動到另一部分或在程序之間移動時使用的。如果假設所有輸入都小于特定大小,并且緩沖區被創建為該大小,則產生更多數據的異常事務可能導致其寫入緩沖區的末尾。
緩沖區溢出概念
緩沖區溢出是指當計算機向緩沖區內填充數據位數時超過了緩沖區本身的容量溢出的數據覆蓋在合法數據上,理想的情況是程序檢查數據長度并不允許輸入超過緩沖區長度的字符,但是絕大多數程序都會假設數據長度總是與所分配的儲存空間相匹配,這就為緩沖區溢出埋下隱患,操作系統所使用的緩沖區,又被稱為"堆棧"。在各個操作進程之間,指令會被臨時儲存在"堆棧"當中,"堆棧"也會出現緩沖區溢出。
緩沖區溢出攻擊之所以成為一種常見安全攻擊手段其原因在于緩沖區溢出漏洞太普遍了,并且易于實現。而且,緩沖區溢出成為遠程攻擊的主要手段其原因在于緩沖區溢出漏洞給予了攻擊者他所想要的一切:植入并且執行攻擊代碼。被植入的攻擊代碼以一定的權限運行有緩沖區溢出漏洞的程序,從而得到被攻擊主機的控制權。
緩沖區溢出漏洞詳解
當你使用諸如“C”或“C ++”之類的語言開發程序并使用gcc使用以下命令對其進行編譯時:
- gcc -o program program.c
你知道gcc如何將你的代碼從“C”轉換為計算機可執行的機器語言嗎?簡而言之,我們可以說該過程分3個步驟完成:
“C”中的代碼將轉換為匯編語言,該匯編語言是二進制之后的最低級語言。此時,匯編代碼被翻譯成二進制。可執行文件是“鏈接的”,換句話說,鏈接是由代碼使用的庫建立的。
現在讓我們看一下匯編器的基礎知識,因為這種語言對于理解開發過程至關重要。
- section .text
- global _start
- _start:
- push rdx
- mov rdi, 0x4444444444444444 ; v_addr
- mov rsi, 0x5555555555555555 ; len
- mov rdx, 0x7 ; RWX
- mov rax, 10 ; mprotect0x80483dc
- syscall
- mov rcx, 0x2222222222222222
- mov rsi, 0x3333333333333333
- mov rdx, 0x6666666666666666 ; random_int
- mov rdi, rsi
- jmp _loop
- _loop:
- cmp rcx, 0x0
- je _end
- lodsb
- not al
- xor al, dl
- stosb
- loop _loopon
- _end:
- pop rdx
- mov rax, 0x1111111111111111
- jmp rax
上面這段代碼的目的只是向你展示它的外觀。如你所見,代碼是由諸如push,mov,cmp等指令組成的。
- ; Note, in assembler everything behind a semicolon is considered as a comment
- call 0x80483dc; Call function at address 0x80483dc
- push 0x0; puts the value 0x0 on the stack
- pop ebx; put what is at the top of the stack in ebx
- mov eax, 0x1; puts 0x1 in eax
如你所見,并不復雜。eax或ebx這些就是我們所說的寄存器。在其中存儲一些值,例如地址,數字等。對于32位處理器,寄存器eax,ebx,ecx,edx,ebp,esp,eip和edi大小為8位。還有其他寄存器,但老實說,它們暫時對我們沒有任何意義。還有一件事,對于64位處理器,我們將使用相同的寄存器,只是它們將是16位而不是8位,并且“e”將替換為“r”,因此寄存器名稱將變為rax,rbx ,rcx,rdx,rbp,rsp,rip和rdi。
內存段
.data-存儲全局變量的段;.bss-包含靜態變量;.text-包含我們的代碼,可能還不夠清楚,所以讓我們用一些代碼來說明一下:

在上面的示例中,我們可以看到以下內容:
a和b在.bss中,c被放在堆棧上,而我們的函數主要在.text中。
讓我們看看如何反匯編程序:

我們將通過編譯上面的一小段代碼進行測試。首先,打開你的終端,并簡單地一個接一個地使用以下命令:
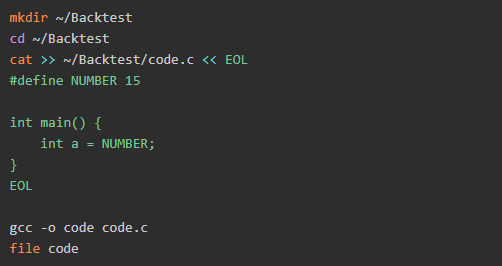
輸出內容:

現在,我們已經編譯了文件,我們將使用objdump對其進行反編譯,objdump是大多數現代GNU / Linux發行版中提供的線性反匯編工具。
- objdump -M intel -d code
輸出內容:
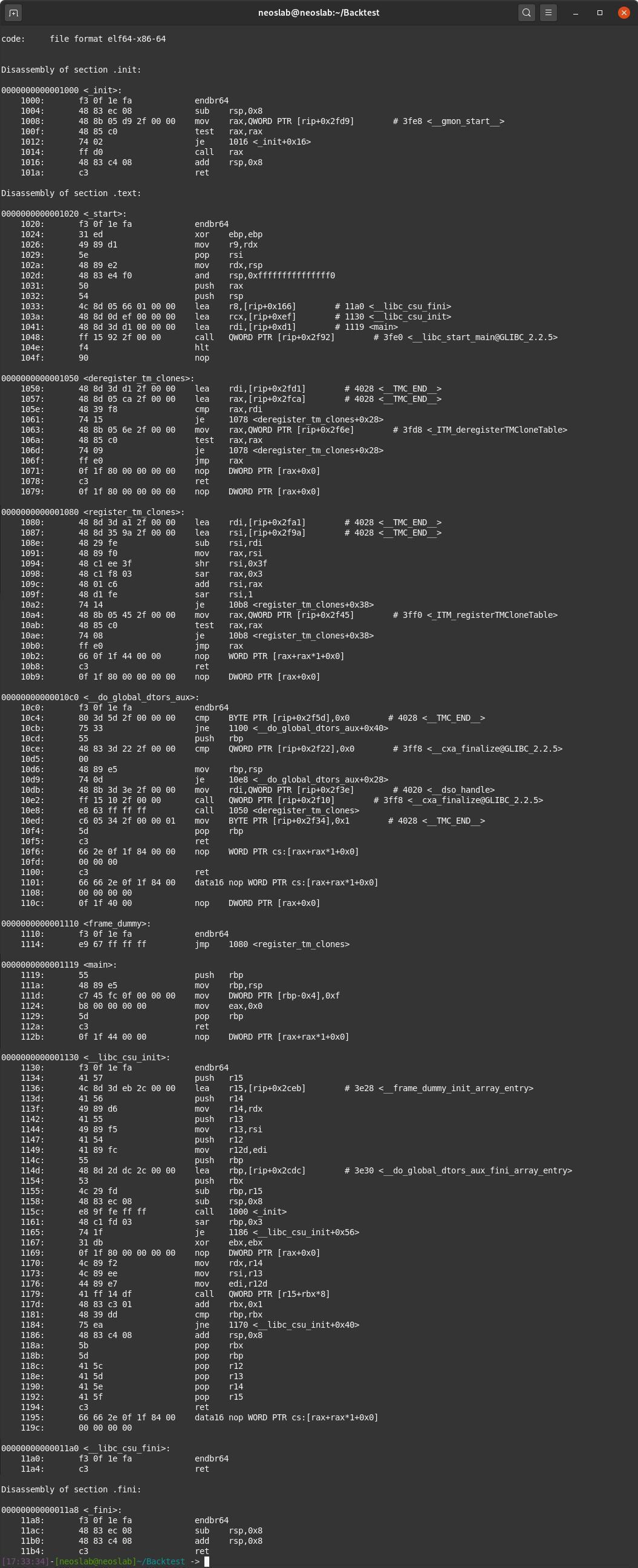
你所看到的一切都是正確的!從上面的屏幕截圖中,我們將重點放在“0000000000001119

讓我們繼續檢查一下我們程序的確切函數:
推送rbp,將rbp放入堆棧;
mov rbp,rsp,將rsp放入rbp;
mov DWORD PTR [rbp-0x4],0xf將0xf(十六進制為15)放入rbp;
mov eax,0x0將0放入eax;
pop rbp將什么放在棧頂中;
如你所見,沒有定義變量。我們甚至可以說也沒有變量名,但是最終我們在rbp中確實有15個。
讓我們看一下這段代碼:

輸出內容:

從上面的輸出中,我們將了解每個會話的大小。到目前為止,你可以看到引用的bss列的大小為“8”。
現在讓我們看看如果通過添加新變量來修改代碼:
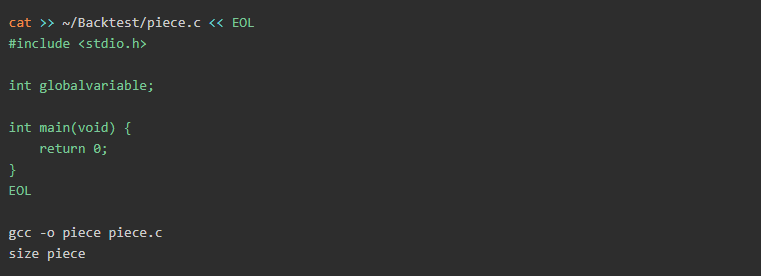
輸出內容:

如你所見,bss從8個字節增加到12個字節,我們可以輕松地認為我們的全局變量存儲在bss中,因為他的值確實增加了。
現在,我們將在主函數中包含一個靜態變量,以進行另一項測試,然后看看會發生什么。
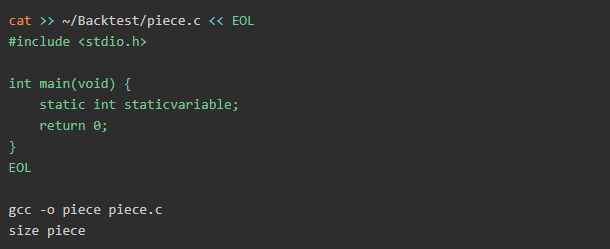
輸出內容:

如你所見,變量沒有像前面的示例那樣存儲在bss中,而是存儲在從512字節變為516字節的數據中。看起來很有趣,不是嗎?
進行最終測試,以了解如果初始化全局變量會發生什么。
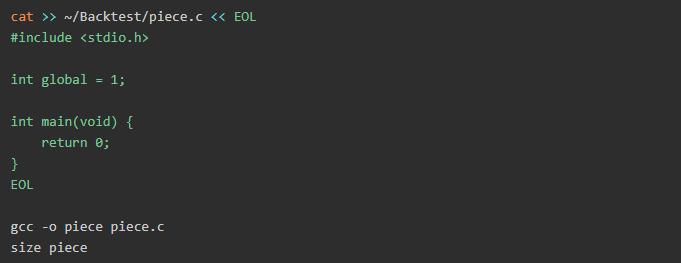
輸出內容:

我們得到相同的結果,你知道為什么嗎?全局變量(如果已初始化)將被放入數據中。我認為如果此時已經開發了足夠的內容,可以讓你了解變量的存儲位置和存儲方式。
內存如何運作?
現在,我們將不談論你的物理內存,而是談論RAM及其如何由操作系統管理。在計算機上運行的進程需要內存,而在計算機中,內存量是有限的。
因此,進程必須尋找可用的內存才能工作。假設有多個進程同時運行。如果兩個進程想要訪問相同的內存區域,將會發生什么?而且,如果某個進程寫入了一個內存區域,那么另一個進程將用其數據覆蓋該相同的內存區域,那么第一個進程將考慮找到其數據,但它將找到第二個進程的數據。這可能是一個很大的問題,不是嗎?
通過為每個進程分配一定范圍的虛擬內存,在32位系統上限制為4GB,在64位系統上限制為8 GB,這是操作系統的主要函數用來解決此問題的位置。
每個進程將能夠使用所需的內存地址,而不必擔心其他進程,操作系統的內核將設法鏈接虛擬內存和實際內存。
棧和堆
現在,我們將繼續進行一些非常重要的事情,堆可以由程序員操縱。這是寫入動態分配的內存區域malloc()或calloc()的內存部分。
此存儲區域沒有固定大小,它根據我們的要求增加或減少,我們可以通過分配或釋放算法保留或刪除塊以供將來使用。堆大小越大,內存地址越大,并且它們與堆棧中的內存地址越接近。與堆棧不同,除了物理內存限制外,堆中變量的大小不受限制。
程序中的任何地方都可以使用指針訪問堆中存儲的變量,堆棧的大小也可變,但是堆棧的大小增加得越大,內存地址減少的越多,從而接近堆的頂部。函數的堆棧框架是堆棧中的一個存儲區域,在其中存儲了調用此函數所需的所有信息,該函數還有局部變量。
理解堆棧的概念
讓我們從LIFO開始講起,它并不代表任何復雜的事情,因為我們之前已經看到過。 LIFO代表后進先出。這就是說,放到棧上的最后一件事是我們要發布的第一個東西,尤其是通過pop和push看到的。
最終緩沖區溢出
最后,我們進入開發部分。讓我們來看下面的一小段代碼。

該代碼看起來完全正常,在學習“C”語言時必須使用scanf函數。但是,如果我們看一下此示例中的堆棧,該怎么辦。
- [buffer (100)] [int a] [saved ebp] [saved eip]
你可能想知道保存的ebp和eip是什么?其實,我們不在乎“保存的ebp”,我們感興趣的是“保存的eip”。你還記得eip包含什么嗎?下一條要執行的指令的地址。如果我們更改此地址,我們可以執行任何操作!
但是,如何更改此值?這很簡單!你會發現scanf不會檢查接收到的字符數!讓我們用以下一段代碼來演示。

如果在執行scanf時給出的值太大(例如,多個“A”),則會導致緩沖區溢出。因此,該程序將向我們返回分段錯誤。但是,如果我們通過有效地址更改“A”值,則可以跳轉到任何位置,特別是在adminfunction()上。
緩沖區溢出和遠程堆溢出的區別,以iOS Mail 客戶端MFMutable中的遠程堆溢出為例。
在分析代碼流時,我們確定了以下內容:
1.以原始MIME格式下載電子郵件時,會調用函數[MFDAMessageContentConsumer ConsumerData:length:format:mailMessage:],并且該函數也會多次調用,直到電子郵件以交換模式下載為止。它將創建一個新的NSMutableData對象,并為屬于同一電子郵件/ MIME消息的任何新流數據調用appendData:。對于其他協議(例如IMAP),它改用-[MFConnection readLineIntoData:],但邏輯和漏洞是相同的。
2.NSMutableData將閾值設置為0x200000字節,如果數據大于0x200000字節,它將把數據寫入文件,然后使用mmap系統調用將文件映射到設備內存。閾值大小0x200000可以輕易增加,因此每次需要添加新數據時,都會重新映射文件,并且文件大小以及mmap大小也會越來越大。
3.重新映射是在-[MFMutableData _mapMutableData:]內部完成的,該漏洞位于此函數內部。
易受攻擊的函數的偽代碼如下:-[MFMutableData _mapMutableData:] 在mmap系統調用失敗時調用函數 MFMutableData__mapMutableData___block_invoke。
MFMutableData__mapMutableData___block_invoke的偽代碼如下,它分配一個大小為8的堆內存,然后用分配的內存替換data-> bytes指針。
在執行-[MFMutableData _mapMutableData:]之后,進程繼續執行-[MFMutableData appendBytes:length:],從而在將數據復制到分配的內存時導致堆溢出。
append_length是來自流式傳輸的數據塊的長度,由于MALLOC_NANO是一個可預測的內存區域,因此可以利用此漏洞。
攻擊者不需要耗盡最后一點內存來導致mmap失敗,因為mmap需要一個連續的內存區域。
根據mmap的操作說明,如果指定了MAP_ANON并且可用內存不足,則mmap將失敗。
目標是使mmap失敗,理想情況下,一封足夠大的郵件將不可避免地導致失敗。但是,我們認為,可以使用其他可以耗盡資源的技巧來觸發漏洞。這些技巧可以通過多部分、RTF和其他格式來實現,我們會在稍后再介紹。
另一個影響可利用性的重要因素是硬件規格:iPhone 6擁有1GB內存;iPhone 7有2GB內存;iPhone X有3GB內存;
較舊的設備具有較小的物理RAM和較小的虛擬內存空間,因此沒有必要耗盡所有的RAM來觸發這個漏洞,當mmap在可用的虛擬內存空間中找不到給定大小的連續內存時,它就會失敗。
我們已經確定,MacOS不會同時受到這兩個漏洞的攻擊。
在iOS 12中,觸發漏洞更容易,因為數據流傳輸是在同一過程中完成的,因為默認郵件應用程序(MobileMail)會處理更多的資源,從而耗盡分配的虛擬內存空間(尤其是UI),而在iOS 13中,MobileMail將數據流傳遞到后臺進程(即郵件)。它把資源集中在解析電子郵件上,從而降低了虛擬內存空間意外耗盡的風險。
由于MobileMail / maild并未明確設置電子郵件大小的最大限制,因此可以設置自定義電子郵件服務器并發送包含幾GB純文本的電子郵件。 iOS MIME /消息庫在流式傳輸數據時將數據平均分成大約0x100000字節,因此完全可以不下載整個電子郵件。
請注意,這只是如何觸發此漏洞的一個示例。攻擊者無需發送此類電子郵件即可觸發此漏洞,并且采用多部分、RTF或其他格式的其他技巧也可以使用標準大小的電子郵件實現相同的目標。
目前,蘋果修復了iOS 13.4.5 beta中的兩個漏洞,如以下屏幕截圖所示:
為了緩解這些漏洞,你可以使用最新版的Beta。如果無法使用Beta版,不過要禁用郵件應用程序,并使用不易受攻擊的Outlook,Edison Mail或Gmail。