













為什么我使用了索引,查詢還是慢?
經常有同學問我,我的一個SQL語句使用了索引,為什么還是會進入到慢查詢之中呢?今天我們就從這個問題開始來聊一聊索引和慢查詢。
另外插入一個題外話,個人認為團隊要合理的使用ORM,可以參考 ORM的權衡和抉擇。合理利用的是ORM在面向對象和寫操作方面的優勢,避免聯合查詢上可能產生的坑(當然如果你的Linq查詢能力很強另當別論),因為ORM屏蔽了太多的DB底層的知識內容,對程序員不是件好事,對性能有極致追求,但是ORM理解不透徹的團隊更加要謹慎。
案例剖析
言歸正傳,為了實驗,我創建了如下表:
- CREATE TABLE `T`(
- `id` int(11) NOT NULL,
- `a` int(11) DEFAUT NULL,
- PRIMARY KEY(`id`),
- KEY `a`(`a`)
- ) ENGINE=InnoDB;
該表有三個字段,其中用id是主鍵索引,a是普通索引。
首先SQL判斷一個語句是不是慢查詢語句,用的是語句的執行時間。他把語句執行時間跟long_query_time這個系統參數作比較,如果語句執行時間比它還大,就會把這個語句記錄到慢查詢日志里面,這個參數的默認值是10秒。當然在生產上,我們不會設置這么大,一般會設置1秒,對于一些比較敏感的業務,可能會設置一個比1秒還小的值。
語句執行過程中有沒有用到表的索引,可以通過explain一個語句的輸出結果來看KEY的值不是NULL。
我們看下 explain select * from t;的KEY結果是NULL

(圖一)
explain select * from t where id=2;的KEY結果是PRIMARY,就是我們常說的使用了主鍵索引

(圖二)
explain select a from t;的KEY結果是a,表示使用了a這個索引。

(圖三)
雖然后兩個查詢的KEY都不是NULL,但是最后一個實際上掃描了整個索引樹a。
假設這個表的數據量有100萬行,圖二的語句還是可以執行很快,但是圖三就肯定很慢了。如果是更極端的情況,比如,這個數據庫上CPU壓力非常的高,那么可能第2個語句的執行時間也會超過long_query_time,會進入到慢查詢日志里面。
所以我們可以得出一個結論:是否使用索引和是否進入慢查詢之間并沒有必然的聯系。使用索引只是表示了一個SQL語句的執行過程,而是否進入到慢查詢是由它的執行時間決定的,而這個執行時間,可能會受各種外部因素的影響。換句話來說,使用了索引你的語句可能依然會很慢。
全索引掃描的不足
那如果我們在更深層次的看這個問題,其實他還潛藏了一個問題需要澄清,就是什么叫做使用了索引。
我們都知道,InnoDB是索引組織表,所有的數據都是存儲在索引樹上面的。比如上面的表t,這個表包含了兩個索引,一個主鍵索引和一個普通索引。在InnoDB里,數據是放在主鍵索引里的。如圖所示:
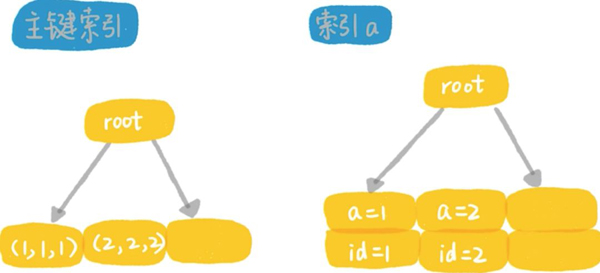
可以看到數據都放在主鍵索引上,如果從邏輯上說,所有的InnoDB表上的查詢,都至少用了一個索引,所以現在我問你一個問題,如果你執行select from t where id>0,你覺得這個語句有用上索引嗎?

我們看上面這個語句的explain的輸出結果顯示的是PRIMARY。其實從數據上你是知道的,這個語句一定是做了全面掃描。但是優化器認為,這個語句的執行過程中,需要根據主鍵索引,定位到第1個滿足ID>0的值,也算用到了索引。
所以即使explain的結果里寫的KEY不是NULL,實際上也可能是全表掃描的,因此InnoDB里面只有一種情況叫做沒有使用索引,那就是從主鍵索引的最左邊的葉節點開始,向右掃描整個索引樹。
也就是說,沒有使用索引并不是一個準確的描述。
- 你可以用全表掃描來表示一個查詢遍歷了整個主鍵索引樹;
- 也可以用全索引掃描,來說明像select a from t;這樣的查詢,他掃描了整個普通索引樹;
- 而select * from t where id=2這樣的語句,才是我們平時說的使用了索引。他表示的意思是,我們使用了索引的快速搜索功能,并且有效的減少了掃描行數。
索引的過濾性要足夠好
根據以上解剖,我們知道全索引掃描會讓查詢變慢,接下來就要來談談索引的過濾性。
假設你現在維護了一個表,這個表記錄了中國14億人的基本信息,現在要查出所有年齡在10~15歲之間的姓名和基本信息,那么你的語句會這么寫,select * from t_people where age between 10 and 15。
你一看這個語句一定要在age字段上開始建立索引了,否則就是個全面掃描,但是你會發現,在你建立索引以后,這個語句還是執行慢,因為滿足這個條件的數據可能有超過1億行。
我們來看看建立索引以后,這個表的組織結構圖:
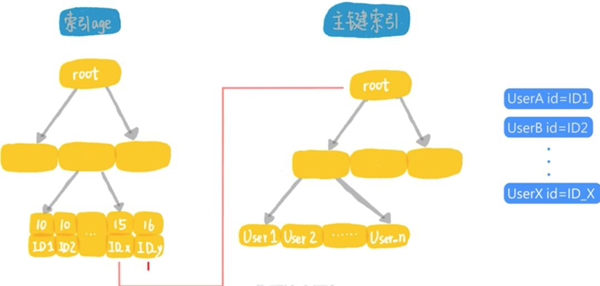
這個語句的執行流程是這樣的:
- 從索引上用樹搜索,取到第1個age等于10的記錄,得到它的主鍵id的值,根據id的值去主鍵索引取整行的信息,作為結果集的一部分返回;
- 在索引age上向右掃描,取下一個id的值,到主鍵索引上取整行信息,作為結果集的一部分返回;
- 重復上面的步驟,直到碰到第1個age大于15的記錄;
你看這個語句,雖然他用了索引,但是他掃描超過了1億行。所以你現在知道了,當我們在討論有沒有使用索引的時候,其實我們關心的是掃描行數。
對于一個大表,不止要有索引,索引的過濾性還要足夠好。
像剛才這個例子的age,它的過濾性就不夠好,在設計表結構的時候,我們要讓所有的過濾性足夠好,也就是區分度足夠高。
回表的代價
那么過濾性好了,是不是表示查詢的掃描行數就一定少呢?
我們再來看一個例子:
如果你的執行語句是 select * from t_people where name='張三' and age=8
t_people表上有一個索引是姓名和年齡的聯合索引,那這個聯合索引的過濾性應該不錯,可以在聯合索引上快速找到第1個姓名是張三,并且年齡是8的小朋友,當然這樣的小朋友應該不多,因此向右掃描的行數很少,查詢效率就很高。
但是查詢的過濾性和索引的過濾性可不一定是一樣的,如果現在你的需求是查出所有名字的第1個字是張,并且年齡是8歲的所有小朋友,你的語句會怎么寫呢?
你的語句要怎么寫?很顯然你會這么寫:select * from t_people where name like '張%' and age=8;
在MySQL5.5和之前的版本中,這個語句的執行流程是這樣的:
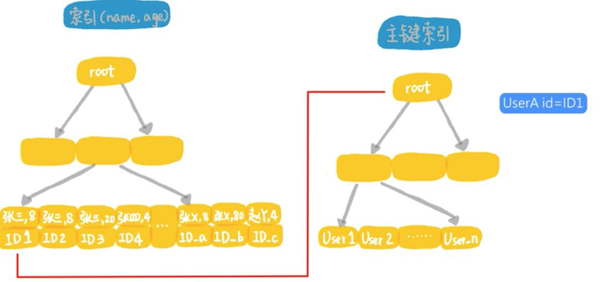
- 首先從聯合索引上找到第1個年齡字段是張開頭的記錄,取出主鍵id,然后到主鍵索引樹上,根據id取出整行的值;
- 判斷年齡字段是否等于8,如果是就作為結果集的一行返回,如果不是就丟棄。
- 在聯合索引上向右遍歷,并重復做回表和判斷的邏輯,直到碰到聯合索引樹上名字的第1個字不是張的記錄為止。
我們把根據id到主鍵索引上查找整行數據這個動作,稱為回表。你可以看到這個執行過程里面,最耗費時間的步驟就是回表,假設全國名字第1個字是張的人有8000萬,那么這個過程就要回表8000萬次,在定位第一行記錄的時候,只能使用索引和聯合索引的最左前綴,最稱為最左前綴原則。
你可以看到這個執行過程,它的回表次數特別多,性能不夠好,有沒有優化的方法呢?
在MySQL5.6版本,引入了index condition pushdown的優化。我們來看看這個優化的執行流程:
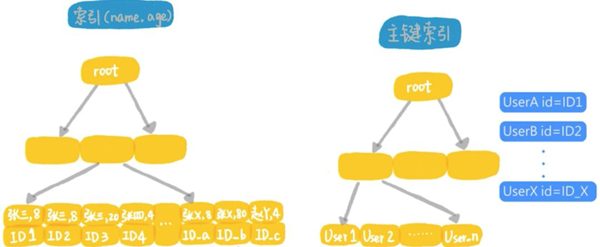
- 首先從聯合索引樹上,找到第1個年齡字段是張開頭的記錄,判斷這個索引記錄里面,年齡的值是不是8,如果是就回表,取出整行數據,作為結果集的一部分返回,如果不是就丟棄;
- 在聯合索引樹上,向右遍歷,并判斷年齡字段后,根據需要做回表,直到碰到聯合索引樹上名字的第1個字不是張的記錄為止;
這個過程跟上面的差別,是在遍歷聯合索引的過程中,將年齡等于8的條件下推到所有遍歷的過程中,減少了回表的次數,假設全國名字第1個字是張的人里面,有100萬個是8歲的小朋友,那么這個查詢過程中在聯合索引里要遍歷8000萬次,而回表只需要100萬次。
虛擬列
可以看到這個優化的效果還是很不錯的,但是這個優化還是沒有繞開最左前綴原則的限制,因此在聯合索引你還是要掃描8000萬行,那有沒有更進一步的優化方法呢?
我們可以考慮把名字的第一個字和age來做一個聯合索引。這里可以使用MySQL5.7引入的虛擬列來實現。對應的修改表結構的SQL語句:
- alter table t_people add name_first varchar(2) generated (left(name,1)),add index(name_first,age);
我們來看這個SQL語句的執行效果:
- CREATE TABLE `t_people`(
- `id` int(11) DEFAULT NULL,
- `name` varchar(20) DEFAUT NULL,
- `name_first` varchar(2) GENERATED ALWAYS AS (left(`name`,1)) VIRTUAL,KEY `name_first`(`name_first`,'age')
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
首先他在people上創建一個字段叫name_first的虛擬列,然后給name_first和age上創建一個聯合索引,并且,讓這個虛擬列的值總是等于name字段的前兩個字節,虛擬列在插入數據的時候不能指定值,在更新的時候也不能主動修改,它的值會根據定義自動生成,在name字段修改的時候也會自動修改。
有了這個新的聯合索引,我們在找名字的第1個字是張,并且年齡為8的小朋友的時候,這個SQL語句就可以這么寫:select * from t_people where name_first='張' and age=8。
這樣這個語句的執行過程,就只需要掃描聯合索引的100萬行,并回表100萬次,這個優化的本質是我們創建了一個更緊湊的索引,來加速了查詢的過程。
總結
本文給你介紹了索引的基本結構和一些查詢優化的基本思路,你現在知道了,使用索引的語句也有可能是慢查詢,我們的查詢優化的過程,往往就是減少掃描行數的過程。
慢查詢歸納起來大概有這么幾種情況:
- 全表掃描
- 全索引掃描
- 索引過濾性不好
- 頻繁回表的開銷
思考
假設業務要求的就是要統計年齡在10-15歲的14億人的數量,不能增加過濾因子,那該怎么辦?(select * from t_people where age between 10 and 15)
假設該統計必須是OLTP,實時展示統計數據,又該怎么解決?


















