













SQL:我為什么慢你心里沒數(shù)嗎?
SQL 語句執(zhí)行慢的原因是面試中經(jīng)常會被問到的,對于服務(wù)端開發(fā)來說也是必須要關(guān)注的問題。
在生產(chǎn)環(huán)境中,SQL 執(zhí)行慢是很嚴重的事件。那么如何定位慢 SQL、慢的原因及如何防患于未然。接下來帶著這些問題讓我們開啟本期之旅!
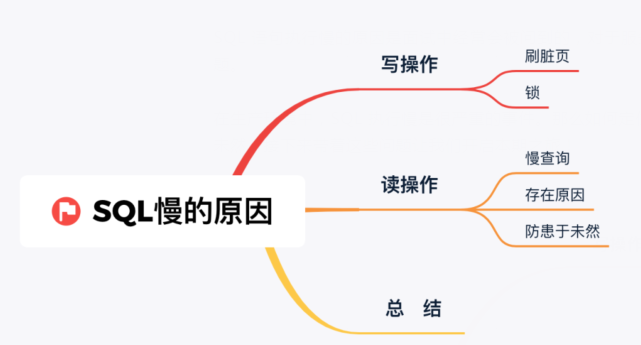
- 思維導(dǎo)圖 -
寫操作
作為后端開發(fā),日常操作數(shù)據(jù)庫最常用的是寫操作和讀操作。讀操作我們下邊會講,這個分類里我們主要來看看寫操作時為什么會導(dǎo)致 SQL 變慢。
刷臟頁
臟頁的定義是這樣的:內(nèi)存數(shù)據(jù)頁和磁盤數(shù)據(jù)頁不一致時,那么稱這個內(nèi)存數(shù)據(jù)頁為臟頁。
那為什么會出現(xiàn)臟頁,刷臟頁又怎么會導(dǎo)致 SQL 變慢呢?那就需要我們來看看寫操作時的流程是什么樣的。
對于一條寫操作的 SQL 來說,執(zhí)行的過程中涉及到寫日志,內(nèi)存及同步磁盤這幾種情況。
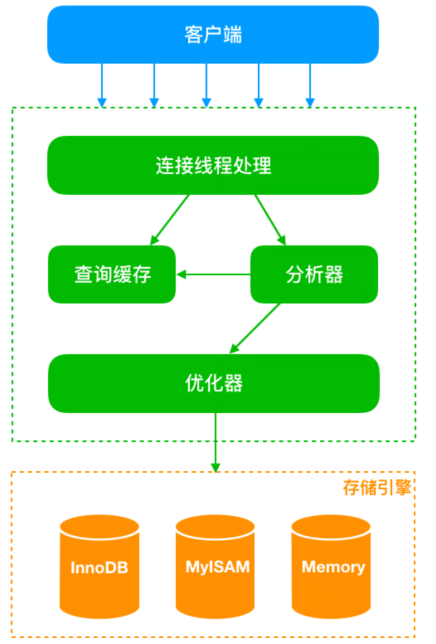
- Mysql 架構(gòu)圖 -
這里要提到一個日志文件,那就是 redo log,位于存儲引擎層,用來存儲物理日志。在寫操作的時候,存儲引擎(這里討論的是 Innodb)會將記錄寫入到 redo log 中,并更新緩存,這樣更新操作就算完成了。后續(xù)操作存儲引擎會在適當?shù)臅r候把操作記錄同步到磁盤里。
看到這里你可能會有個疑問,redo log 不是日志文件嗎,日志文件就存儲在磁盤上,那寫的時候豈不很慢嗎?
其實,寫redo log 的過程是順序?qū)懘疟P的,磁盤順序?qū)憸p少了尋道等時間,速度比隨機寫要快很多( 類似Kafka存儲原理),因此寫 redo log 速度是很快的。
好了,讓我們回到開始時候的問題,為什么會出現(xiàn)臟頁,并且臟頁為什么會使 SQL 變慢。你想想,redo log 大小是一定的,且是循環(huán)寫入的。在高并發(fā)場景下,redo log 很快被寫滿了,但是數(shù)據(jù)來不及同步到磁盤里,這時候就會產(chǎn)生臟頁,并且還會阻塞后續(xù)的寫入操作。SQL 執(zhí)行自然會變慢。
鎖
寫操作時 SQL 慢的另一種情況是可能遇到了鎖,這個很容易理解。舉個例子,你和別人合租了一間屋子,只有一個衛(wèi)生間,你們倆同時都想去,但對方比你早了一丟丟。那么此時你只能等對方出來后才能進去。
對應(yīng)到 Mysql 中,當某一條 SQL 所要更改的行剛好被加了鎖,那么此時只有等鎖釋放了后才能進行后續(xù)操作。
但是還有一種極端情況,你的室友一直占用著衛(wèi)生間,那么此時你該怎么整,總不能尿褲子吧,多丟人。對應(yīng)到Mysql 里就是遇到了死鎖或是鎖等待的情況。這時候該如何處理呢?
Mysql 中提供了查看當前鎖情況的方式:

通過在命令行執(zhí)行圖中的語句,可以查看當前運行的事務(wù)情況,這里介紹幾個查詢結(jié)果中重要的參數(shù):
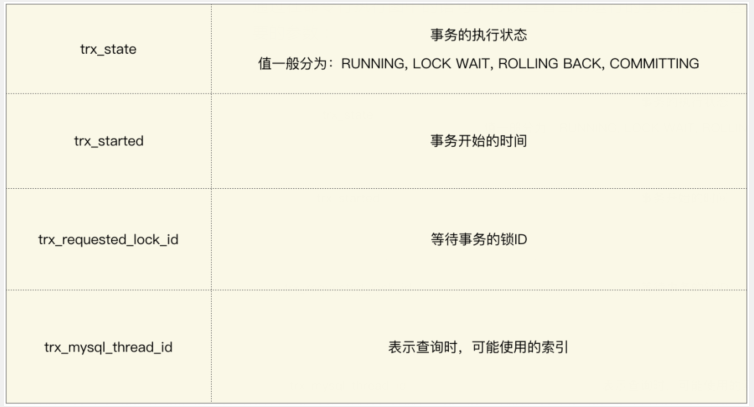
當前事務(wù)如果等待時間過長或出現(xiàn)死鎖的情況,可以通過 「kill 線程ID」 的方式釋放當前的鎖。
這里的線程 ID 指表中 trx_mysql_thread_id 參數(shù)。
讀操作
說完了寫操作,讀操作大家可能相對來說更熟悉一些。SQL 慢導(dǎo)致讀操作變慢的問題在工作中是經(jīng)常會被涉及到的。
慢查詢
在講讀操作變慢的原因之前我們先來看看是如何定位慢 SQL 的。Mysql 中有一個叫作慢查詢?nèi)罩镜臇|西,它是用來記錄超過指定時間的 SQL 語句的。默認情況下是關(guān)閉的,通過手動配置才能開啟慢查詢?nèi)罩具M行定位。
具體的配置方式是這樣的:
查看當前慢查詢?nèi)罩镜拈_啟情況:
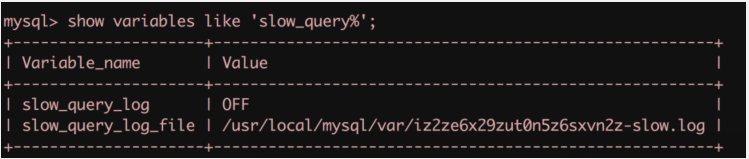
- 開啟慢查詢?nèi)罩?臨時):

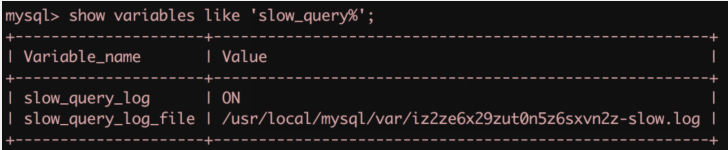
注意這里只是臨時開啟了慢查詢?nèi)罩荆绻?mysql 重啟后則會失效。可以 my.cnf 中進行配置使其永久生效。
存在原因
知道了如何查看執(zhí)行慢的 SQL 了,那么我們接著看讀操作時為什么會導(dǎo)致慢查詢。
(1)未命中索引
SQL 查詢慢的原因之一是可能未命中索引,關(guān)于使用索引為什么能使查詢變快以及使用時的注意事項,網(wǎng)上已經(jīng)很多了,這里就不多贅述了。
(2)臟頁問題
另一種還是我們上邊所提到的刷臟頁情況,只不過和寫操作不同的是,是在讀時候進行刷臟頁的。
是不是有點懵逼,別急,聽我娓娓道來:
為了避免每次在讀寫數(shù)據(jù)時訪問磁盤增加 IO 開銷,Innodb 存儲引擎通過把相應(yīng)的數(shù)據(jù)頁和索引頁加載到內(nèi)存的緩沖池(buffer pool)中來提高讀寫速度。然后按照最近最少使用原則來保留緩沖池中的緩存數(shù)據(jù)。
那么當要讀入的數(shù)據(jù)頁不在內(nèi)存中時,就需要到緩沖池中申請一個數(shù)據(jù)頁,但緩沖池中數(shù)據(jù)頁是一定的,當數(shù)據(jù)頁達到上限時此時就需要把最久不使用的數(shù)據(jù)頁從內(nèi)存中淘汰掉。但如果淘汰的是臟頁呢,那么就需要把臟頁刷到磁盤里才能進行復(fù)用。
你看,又回到了刷臟頁的情況,讀操作時變慢你也能理解了吧?
防患于未然
知道了原因,我們?nèi)绾蝸肀苊饣蚓徑膺@種情況呢?
首先來看未命中索引的情況:
不知道大家有沒有使用 Mysql 中 explain 的習(xí)慣,反正我是每次都會用它來查看下當前 SQL 命中索引的情況。避免其帶來一些未知的隱患。
這里簡單介紹下其使用方式,通過在所執(zhí)行的 SQL 前加上 explain 就可以來分析當前 SQL 的執(zhí)行計劃:

執(zhí)行后的結(jié)果對應(yīng)的字段概要描述如下圖所示:
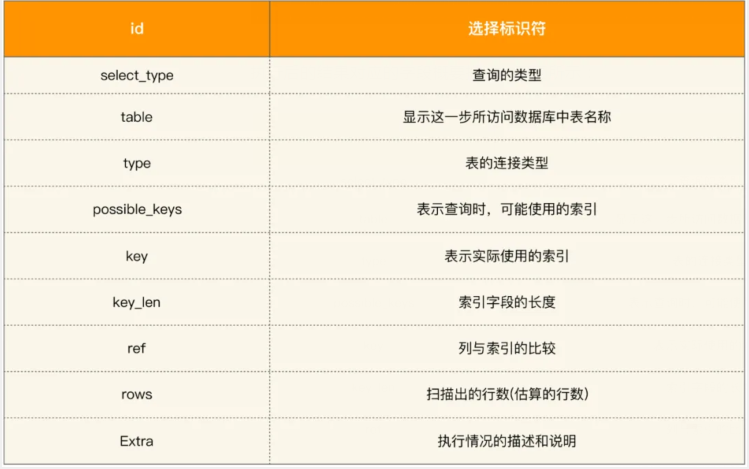
這里需要重點關(guān)注以下幾個字段:
1、type
表示 MySQL 在表中找到所需行的方式。其中常用的類型有:ALL、index、range、 ref、eq_ref、const、system、NULL 這些類型從左到右,性能逐漸變好。
- ALL:Mysql 遍歷全表來找到匹配的行;
- index:與 ALL 區(qū)別為 index 類型只遍歷索引樹;
- range:只檢索給定范圍的行,使用一個索引來選擇行;
- ref:表示上述表的連接匹配條件,哪些列或常量被用于查找索引列上的值;
- eq_ref:類似ref,區(qū)別在于使用的是否為唯一索引。對于每個索引鍵值,表中只有一條記錄匹配,簡單來說,就是多表連接中使用 primary key 或者 unique key作為關(guān)聯(lián)條件;
- const、system:當 Mysql 對查詢某部分進行優(yōu)化,并轉(zhuǎn)換為一個常量時,使用這些類型訪問。如將主鍵置于 where 列表中,Mysql 就能將該查詢轉(zhuǎn)換為一個常量,system 是 const類型的特例,當查詢的表只有一行的情況下,使用system;
- NULL:Mysql 在優(yōu)化過程中分解語句,執(zhí)行時甚至不用訪問表或索引,例如從一個索引列里選取最小值可以通過單獨索引查找完成。
2、possible_keys
查詢時可能使用到的索引(但不一定會被使用,沒有任何索引時顯示為 NULL)。
3、key
實際使用到的索引。
4、rows
估算查找到對應(yīng)的記錄所需要的行數(shù)。
5、Extra
比較常見的是下面幾種:
- Useing index:表明使用了覆蓋索引,無需進行回表;
- Using where:不用讀取表中所有信息,僅通過索引就可以獲取所需數(shù)據(jù),這發(fā)生在對表的全部的請求列都是同一個索引的部分的時候,表示mysql服務(wù)器將在存儲引擎檢索行后再進行過濾;
- Using temporary:表示MySQL需要使用臨時表來存儲結(jié)果集,常見于排序和分組查詢,常見 group by,order by;
- Using filesort:當Query中包含 order by 操作,而且無法利用索引完成的排序操作稱為“文件排序”。
對于刷臟頁的情況,我們需要控制臟頁的比例,不要讓它經(jīng)常接近 75%。同時還要控制 redo log 的寫盤速度,并且通過設(shè)置 innodb_io_capacity 參數(shù)告訴 InnoDB 你的磁盤能力。
總結(jié)
寫操作
- 當 redo log 寫滿時就會進行刷臟頁,此時寫操作也會終止,那么 SQL 執(zhí)行自然就會變慢。
- 遇到所要修改的數(shù)據(jù)行或表加了鎖時,需要等待鎖釋放后才能進行后續(xù)操作,SQL 執(zhí)行也會變慢。
讀操作
- 讀操作慢很常見的原因是未命中索引從而導(dǎo)致全表掃描,可以通過 explain 方式對 SQL 語句進行分析。
- 另一種原因是在讀操作時,要讀入的數(shù)據(jù)頁不在內(nèi)存中,需要通過淘汰臟頁才能申請新的數(shù)據(jù)頁從而導(dǎo)致執(zhí)行變慢。























