一年Node.js開發開發經驗總結
寫在前面
不知不覺的,寫Node.js已經一年了。不同于最開始的demo、本地工具等,這一年里,都是用Node.js寫的線上業務。從一開始的Node.js同構直出,到最近的Node接入層,也算是對Node開發入門了吧。目前,我一個人維護了大部分組內流傳下來的Node服務,包括內部系統和線上服務。新增的后臺服務,也是盡可能地使用Node進行開發。本文是一下自己最近的一些小小的總結和思考。
本文不會深入講解Node.js本身的特性,架構等等。我也沒有寫過Node擴展或者庫什么的,對Node.js的了解也并不夠深入。
為何用Node
對于我來說,對于團隊來說,適用Node的原因其實很簡單:開發起來快。熟悉JS的前端同學可以很快上手,節省成本。選一個http server庫起一個server,選擇合適的中間件,匹配好請求路由,看情況合理使用ORM庫鏈接數據庫、增刪改查即可。
Node的適用場景
Node.js 使用了一個事件驅動、非阻塞式 I/O 的模型,使其輕量又高效。這種模型使得Node.js 可以避免了由于需要等待輸入或者輸出(數據庫、文件系統、Web服務器...)響應而造成的 CPU 時間損失。所以,Node.js適合運用在高并發、I/O密集、少量業務邏輯的場景。
對應到平時具體的業務上,如果是內部的系統,大部分僅僅就是需要對某個數據庫進行增刪改查,那么Server端直接就是Node.js一把梭。
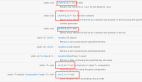
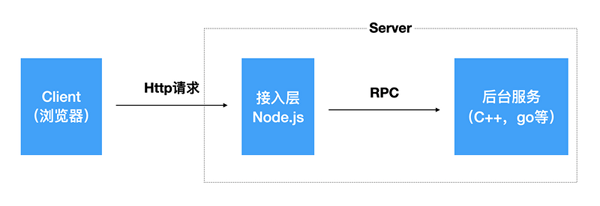
對于線上業務,如果流量不大,并且業務邏輯簡單的情況下,Server端也可以完全使用Node.js。對于流量巨大,復雜度高的項目,一般用Node.js作為接入層,后臺同學負責實現服務。如下圖:
同樣是寫JS,Node.js開發和頁面開發有什么區別
在瀏覽器端開發頁面,是和用戶打交道、重交互,瀏覽器還提供了各種Web Api供我們使用。Node.js主要面向數據,收到請求后,返回具體的數據。這是兩者在業務路徑上的區別。而真正的區別其實是在于業務模型上(業務模型,這是我自己瞎想的一個詞)。直接用圖表示吧。
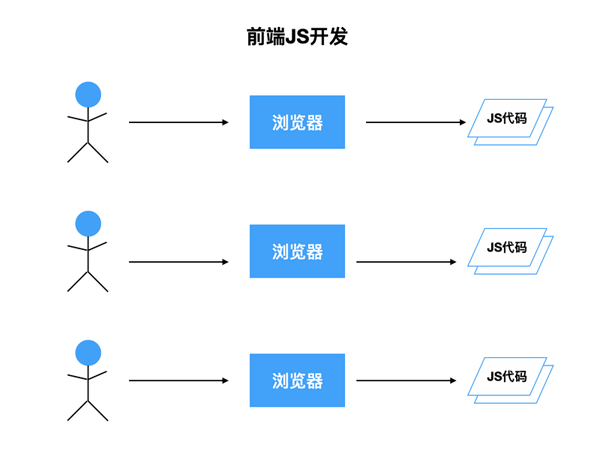
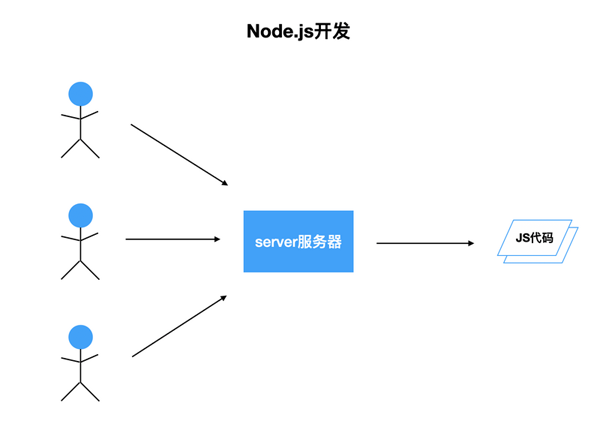
開發頁面時,每一個用戶的瀏覽器上都有一份JS代碼。如果代碼在某種情況下崩了,只會對當前用戶產生影響,并不會影響其他用戶,用戶刷新一下即可恢復。而在Node.js中,在不開啟多進程的情況下,所有用戶的請求,都會走進同一份JS代碼,并且只有一個線程在執行這份JS代碼。如果某個用戶的請求,導致發生錯誤,Node.js進程掛掉,server端直接就掛了。盡管可能有進程守護,掛掉的進程會被重啟,但是在用戶請求量大的情況下,錯誤會被頻繁觸發,可能就會出現server端不停掛掉,不停重啟的情況,對用戶體驗造成影響。
以上,可能是Node.js開發和前端JS開發最大的區別。
Node.js開發時的注意事項
用戶在訪問Node.js服務時,如果某一個請求卡住了,服務遲遲不能返回結果,或者說邏輯出錯,導致服務掛掉,都會帶來大規模的體驗問題。server端的目標,就是要 快速、可靠 地返回數據。
- 緩存
由于Node.js不擅長處理復雜邏輯(JavaScript本身執行效率較低),如果要用Node.js做接入層,應該避免復雜的邏輯。想要快速處理數據并返回,一個至關重要的點:使用緩存。
例如,使用Node做React同構直出,renderToString這個Api,可以說是比較重的邏輯了。如果頁面的復雜度高,每次請求都完整執行renderToString,會長時間占用線程來執行代碼,增加響應時間,降低服務的吞吐量。這個時候,緩存就十分重要了。
實現緩存的主要方式:內存緩存。可以使用Map,WeakMap,WeakRef等實現。參考以下簡單的示例代碼:
- const cache = new Map();
- router.get('/getContent', async (req, res) => {
- const id = req.query.id;
- // 命中緩存
- if(cache.get(id)) {
- return res.send(cache.get(id));
- }
- // 請求數據
- const rsp = await rpc.get(id);
- // 經過一頓復雜的操作,處理數據
- const content = process(rsp);
- // 設置緩存
- cache.set(id, content);
- return res.send(content);
- });
使用緩存時,有一個很重要的問題是:內存緩存如何更新。一種最簡單的方法,開一個定時器,定期刪除緩存,下一次請求到來時,重新設置緩存即可。在上述代碼中,增加如下代碼:
- setTimeout(function() {
- cache.clear();
- }, 1000 * 60); // 1分鐘刪除一次緩存
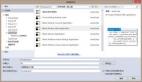
如果server端完全使用Node實現,需要用Node端直接連接數據庫,在數據時效性要求不太高、且流量不太大的情況下,就可以使用上述類似的模型,如下圖。這樣可以降低數據庫的壓力且加快Node的響應速度。
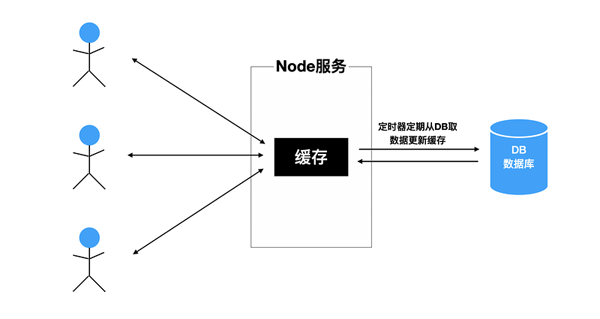
另外,還需要注意內存緩存的大小。如果一直往緩存里寫入新數據,那么內存會越來越大,最終爆掉。可以考慮使用LRU(Least Recently Used)算法來做緩存。開辟一塊內存專門作為緩存區域。當緩存大小達到上限時,淘汰最久未使用的緩存。
內存緩存會隨著進程的重啟而全部失效。
當后臺業務比較復雜,接入層流量,數據量較大時,可以使用如下的架構,使用獨立的內存緩存服務。Node接入層直接從緩存服務取數據,后臺服務直接更新緩存服務。
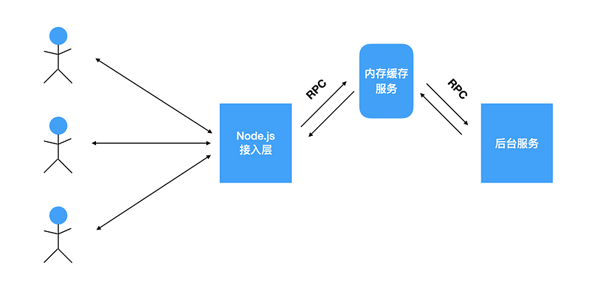
當然,上圖中的架構是最簡單的情形,現實中還需要考慮分布式緩存、緩存一致性的問題。這又是另外一個話題了。
- 錯誤處理
由于Node.js語言的特性,Node服務是比較容易出錯的。而一旦出錯,造成的影響就是服務不可用。因此,對于錯誤的處理十分的重要。
處理錯誤,最常用的就是try catch 了。可是 try catch無法捕獲異步錯誤。Node.js中,異步操作是十分常見的,異步操作主要是在回調函數中暴露錯誤。看一個例子:
- const readFile = function(path) {
- return new Promise((resolve,reject) => {
- fs.readFile(path, (err, data) => {
- if(err) {
- throw err; // catch無法捕獲錯誤,這和Node的eventloop有關。
- // reject(err); // catch可以捕獲
- }
- resolve(data);
- });
- });
- }
- router.get('/xxx', async function(req, res) {
- try {
- const res = await readFile('xxx');
- ...
- } catch (e){
- // 捕獲錯誤處理
- ...
- res.send(500);
- }
- });
上面的代碼中,readFile 中 throw 出來的錯誤,是無法被catch捕獲的。如果我們把 throw err 換成 Promise.reject(err),catch中是可以捕獲到錯誤的。
我們可以把異步操作都Promise化,然后統一使用 async 、try、catch 來處理錯誤。
但是,總會有地方會被遺漏。這個時候,可以使用process來捕獲全局錯誤,防止進程直接退出,導致后面的請求掛掉。示例代碼:
- process.on('uncaughtException', (err) => {
- console.error(`${err.message}\n${err.stack}`);
- });
- process.on('unhandledRejection', (reason, p) => {
- console.error(`Unhandled Rejection at: Promise ${p} reason: `, reason);
- });
關于Node.js中錯誤的捕獲,還可以使用domain模塊。現在這個模塊已經不推薦使用了,我也沒有在項目中實踐過,這里就不展開了。Node.js 近幾年推出的 async_hooks 模塊,也還處于實驗階段,不太建議線上環境直接使用。做好進程守護,開啟多進程,錯誤告警及時修復,養成良好的編碼規范,使用合適的框架,才能提高Node服務的效率及穩定性。
寫在后面
本文總結了Node.js開發一年多以來的實踐總結等。Node.js的開發與前端網頁的開發思路不同,著重點不一樣。我正式開發Node.js的時間也不算太長,一些點并沒有深入的理解,本文僅僅是一些經驗之談。