零散的MySQL基礎總是記不住?看這一篇如何拯救你
前言
在日常開發(fā)中,一些不常用且又比較基礎的知識,過了一段時間之后,總是容易忘記或者變得有點模棱兩可。本篇主要記錄一些關于MySQL數(shù)據(jù)庫比較基礎的知識,以便日后快速查看。

SQL命令
SQL命令分可以分為四組:DDL、DML、DCL和TCL。四組中包含的命令分別如下
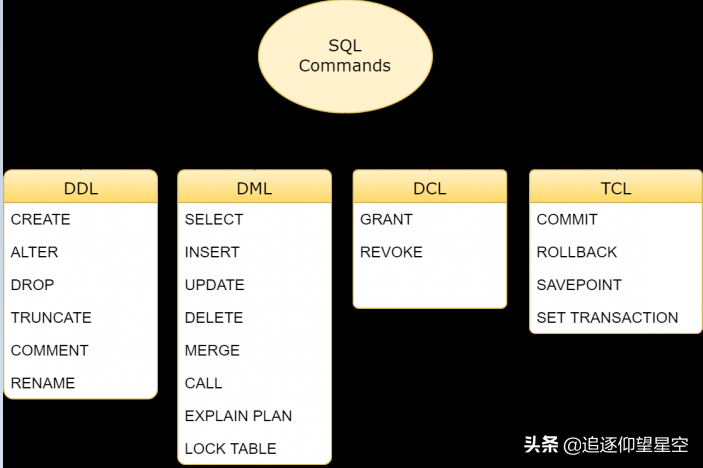
DDL
DDL是數(shù)據(jù)定義語言(Data Definition Language)的簡稱,它處理數(shù)據(jù)庫schemas和描述數(shù)據(jù)應如何駐留在數(shù)據(jù)庫中。
- CREATE:創(chuàng)建數(shù)據(jù)庫及其對象(如表,索引,視圖,存儲過程,函數(shù)和觸發(fā)器)
- ALTER:改變現(xiàn)有數(shù)據(jù)庫的結構
- DROP:從數(shù)據(jù)庫中刪除對象
- TRUNCATE:從表中刪除所有記錄,包括為記錄分配的所有空間都將被刪除
- COMMENT:添加注釋
- RENAME:重命名對象
常用命令如下:
- # 建表
- CREATE TABLE sicimike (
- id int(4) primary key auto_increment COMMENT '主鍵ID',
- name varchar(10) unique,
- age int(3) default 0,
- identity_card varchar(18)
- # PRIMARY KEY (id) // 也可以通過這種方式設置主鍵
- # UNIQUE KEY (name) // 也可以通過這種方式設置唯一鍵
- # key/index (identity_card, col1...) // 也可以通過這種方式創(chuàng)建索引
- ) ENGINE = InnoDB;
- # 設置主鍵
- alter table sicimike add primary key(id);
- # 刪除主鍵
- alter table sicimike drop primary key;
- # 設置唯一鍵
- alter table sicimike add unique key(column_name);
- # 刪除唯一鍵
- alter table sicimike drop index column_name;
- # 創(chuàng)建索引
- alter table sicimike add [unique/fulltext/spatial] index/key index_name (identity_card[(len)] [asc/desc])[using btree/hash]
- create [unique/fulltext/spatial] index index_name on sicimike(identity_card[(len)] [asc/desc])[using btree/hash]
- example: alter table sicimike add index idx_na(name, age);
- # 刪除索引
- alter table sicimike drop key/index identity_card;
- drop index index_name on sicimike;
- # 查看索引
- show index from sicimike;
- # 查看列
- desc sicimike;
- # 新增列
- alter table sicimike add column column_name varchar(30);
- # 刪除列
- alter table sicimike drop column column_name;
- # 修改列名
- alter table sicimike change column_name new_name varchar(30);
- # 修改列屬性
- alter table sicimike modify column_name varchar(22);
- # 查看建表信息
- show create table sicimike;
- # 添加表注釋
- alter table sicimike comment '表注釋';
- # 添加字段注釋
- alter table sicimike modify column column_name varchar(10) comment '姓名';
DML
DML是數(shù)據(jù)操縱語言(Data Manipulation Language)的簡稱,包括最常見的SQL語句,例如SELECT,INSERT,UPDATE,DELETE等,它用于存儲,修改,檢索和刪除數(shù)據(jù)庫中的數(shù)據(jù)。
- 分頁
- -- 查詢從第11條數(shù)據(jù)開始的連續(xù)5條數(shù)據(jù)
- select * from sicimike limit 10, 5
- group by
默認情況下,MySQL中的分組(group by)語句,不要求select返回的列,必須是分組的列或者是一個聚合函數(shù)。如果select查詢的列不是分組的列,也不是聚合函數(shù),則會返回該分組中第一條記錄的數(shù)據(jù)。對比下面兩條SQL語句,第二條SQL語句中,cname既不是分組的列,也不是以聚合函數(shù)的形式出現(xiàn)。所以在liming這個分組中,cname取的是第一條數(shù)據(jù)。
- mysql> select * from c;
- +-----+-------+----------+
- | CNO | CNAME | CTEACHER |
- +-----+-------+----------+
- | 1 | 數(shù)學 | liming |
- | 2 | 語文 | liming |
- | 3 | 歷史 | xueyou |
- | 4 | 物理 | guorong |
- | 5 | 化學 | liming |
- +-----+-------+----------+
- 5 rows in set (0.00 sec)
- mysql> select cteacher, count(cteacher), cname from c group by cteacher;
- +----------+-----------------+-------+
- | cteacher | count(cteacher) | cname |
- +----------+-----------------+-------+
- | guorong | 1 | 物理 |
- | liming | 3 | 數(shù)學 |
- | xueyou | 1 | 歷史 |
- +----------+-----------------+-------+
- 3 rows in set (0.00 sec)
- having
having關鍵字用于對分組后的數(shù)據(jù)進行篩選,功能相當于分組之前的where,不過要求更嚴格。過濾條件要么是一個聚合函數(shù)( ... having count(x) > 1),要么是出現(xiàn)在select后面的列(select col1, col2 ... group by x having col1 > 1)
- 多表更新
- update tableA a inner join tableB b on a.xxx = b.xxx set a.col1 = xxx, b.col1 = xxx where ...多表刪除
- 多表刪除
- delete a, b from tableA a inner join tableB b on a.xxx = b.xxx where a.col1 = xxx and b.col1 = xxx
DCL
DCL是數(shù)據(jù)控制語言(Data Control Language)的簡稱,它包含諸如GRANT之類的命令,并且主要涉及數(shù)據(jù)庫系統(tǒng)的權限,權限和其他控件。
- GRANT :允許用戶訪問數(shù)據(jù)庫的權限
- REVOKE:撤銷用戶使用GRANT命令賦予的訪問權限
TCL
TCL是事務控制語言(Transaction Control Language)的簡稱,用于處理數(shù)據(jù)庫中的事務
- COMMIT:提交事務
- ROLLBACK:在發(fā)生任何錯誤的情況下回滾事務
范式
數(shù)據(jù)庫規(guī)范化,又稱正規(guī)化、標準化,是數(shù)據(jù)庫設計的一系列原理和技術,以減少數(shù)據(jù)庫中數(shù)據(jù)冗余,增進數(shù)據(jù)的一致性。關系模型的發(fā)明者埃德加·科德最早提出這一概念,并于1970年代初定義了第一范式、第二范式和第三范式的概念,還與Raymond F. Boyce于1974年共同定義了第三范式的改進范式——BC范式。除外還包括針對多值依賴的第四范式,連接依賴的第五范式、DK范式和第六范式。
現(xiàn)在數(shù)據(jù)庫設計最多滿足3NF,普遍認為范式過高,雖然具有對數(shù)據(jù)關系更好的約束性,但也導致數(shù)據(jù)關系表增加而令數(shù)據(jù)庫IO更易繁忙,原來交由數(shù)據(jù)庫處理的關系約束現(xiàn)更多在數(shù)據(jù)庫使用程序中完成。
第一范式
定義:數(shù)據(jù)庫中的所有字段(列)都是單一屬性,不可再分的。這個單一屬性由基本的數(shù)據(jù)類型所構成,如整型、浮點型、字符串等。第一范式是為了保證列的原子性。

上表不滿足第一范式,其中的地址列是可以再拆分的,可以拆分成省、市、區(qū)等

第二范式
定義:數(shù)據(jù)庫中的表不存在非關鍵字段對任一關鍵字字段的部分函數(shù)依賴部分函數(shù)依賴是指存在著組合關鍵字中的某一關鍵字決定非關鍵字的情況第二范式在滿足了第一范式的基礎上,消除非主鍵列對聯(lián)合主鍵的部分依賴

上面這張表中想要設置主鍵,只能是商品名稱和供應商名稱一起組成聯(lián)合主鍵。但是價格和分類只依賴于商品名稱,供應商電話只依賴于供應商名稱,所以上面的表不滿足第二范式,可以改成如下形式:
商品信息表

供應商信息表

商品-供應商關聯(lián)表

第三范式
定義:所有非主鍵屬性都只和候選鍵有相關性,也就是說非主鍵屬性之間應該是獨立無關的。第三范式是在滿足了第二范式的基礎上,消除列與列之間的傳遞依賴。

在上面的表中,商品的分類描述依賴分類,而分類依賴商品名稱,而不是分類描述直接依賴商品名稱。這樣就形成了傳遞依賴,所以不符合第三范式。可以改成如下形式
商品表

商品分類表

數(shù)據(jù)庫設計時,遵循范式和反范式一直以來是一個頗受爭議的問題。遵循范式對數(shù)據(jù)關系更好的約束性,并且減少數(shù)據(jù)冗余,可以更好地保證數(shù)據(jù)一致性。而反范式則是為了獲得更好的性能。所以范式還是反范式并沒有明確的標準,適合自己業(yè)務場景的才是最好的。
反范式設計時,需要考慮以下幾個問題,分別是插入異常、更新異常和刪除異常。
- 插入異常:如果某個實體隨著另一個實體的存在而存在,即缺少某個實體是無法表示這個實體,那么這個表就存在插入異常。
- 更新異常:如果更改表所對應的某個實體實例的單獨屬性時,需要將多行更新,那么就說明這個表存在更新異常
- 刪除異常:如果刪除表的某一行來表示某實體實例失效時,導致另一個不同實體實例信息丟失,那么這個表就存在刪除異常
以違反第二范式的表為例

如果可樂第二制造廠這個供應商尚未開始供貨,表中就不存在第二條記錄,也就無法記錄供應商的電話,這樣就存在插入異常;如果需要把可樂的價格提高,需要更新表中的多條記錄,這樣就存在更新異常;如果刪除可樂第二制造廠的供貨信息,那么該供應商的電話也就丟失了,這樣就存在刪除異常。
一般存在插入異常的表,都會存在更新異常和刪除異常。
橫表縱表
SQL腳本
- # 橫表
- CREATE TABLE `table_h2z` (
- `name` varchar(32) DEFAULT NULL,
- `chinese` int(11) DEFAULT NULL,
- `math` int(11) DEFAULT NULL,
- `english` int(11) DEFAULT NULL
- ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
- /*Data for the table `table_h2z` */
- insert into `table_h2z`(`name`,`chinese`,`math`,`english`) values
- ('mike',45,43,87),
- ('lily',53,64,88),
- ('lucy',57,75,75);
- # 縱表
- CREATE TABLE `table_z2h` (
- `name` varchar(32) DEFAULT NULL,
- `subject` varchar(8) NOT NULL DEFAULT '',
- `score` int(11) DEFAULT NULL
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- /*Data for the table `table_z2h` */
- insert into `table_z2h`(`name`,`subject`,`score`) values
- ('mike','chinese',45),
- ('lily','chinese',53),
- ('lucy','chinese',57),
- ('mike','math',43),
- ('lily','math',64),
- ('lucy','math',75),
- ('mike','english',87),
- ('lily','english',88),
- ('lucy','english',75);
橫表轉縱表
- SELECT NAME, 'chinese' AS `subject`, chinese AS `score` FROM table_h2z
- UNION ALL
- SELECT NAME, 'math' AS `subject`, math AS `score` FROM table_h2z
- UNION ALL
- SELECT NAME, 'english' AS `subject`, english AS `score` FROM table_h2z
執(zhí)行結果
- +------+---------+-------+
- | name | subject | score |
- +------+---------+-------+
- | mike | chinese | 45 |
- | lily | chinese | 53 |
- | lucy | chinese | 57 |
- | mike | math | 43 |
- | lily | math | 64 |
- | lucy | math | 75 |
- | mike | english | 87 |
- | lily | english | 88 |
- | lucy | english | 75 |
- +------+---------+-------+
- 9 rows in set (0.00 sec)
縱表轉橫表
- SELECT NAME,
- SUM(CASE `subject` WHEN 'chinese' THEN score ELSE 0 END) AS chinese,
- SUM(CASE `subject` WHEN 'math' THEN score ELSE 0 END) AS math,
- SUM(CASE `subject` WHEN 'english' THEN score ELSE 0 END) AS english
- FROM table_z2h
- GROUP BY NAME
執(zhí)行結果
- +------+---------+------+---------+
- | name | chinese | math | english |
- +------+---------+------+---------+
- | lily | 53 | 64 | 88 |
- | lucy | 57 | 75 | 75 |
- | mike | 45 | 43 | 87 |
- +------+---------+------+---------+
- 3 rows in set (0.00 sec)