谷歌開源NLP模型可視化工具LIT,模型訓練不再「黑箱」
深度學習模型的訓練就像是「黑箱操作」,知道輸入是什么、輸出是什么,但中間過程就像個黑匣子,這使得研究人員可能花費大量時間找出模型運行不正常的原因。假如有一款可視化的工具,能夠幫助研究人員更好地理解模型行為,這應該是件非常棒的事。
近日,Google 研究人員發布了一款語言可解釋性工具 (Language Interpretability Tool, LIT),這是一個開源平臺,用于可視化和理解自然語言處理模型。
論文地址:https://arxiv.org/pdf/2008.05122.pdf
項目地址:https://github.com/PAIR-code/lit
LIT 重點關注模型行為的核心問題,包括:為什么模型做出這樣的預測?什么時候性能不佳?在輸入變化可控的情況下會發生什么?LIT 將局部解釋、聚合分析和反事實生成集成到一個流線型的、基于瀏覽器的界面中,以實現快速探索和錯誤分析。
該研究支持多種自然語言處理任務,包括探索情感分析的反事實、度量共指系統中的性別偏見,以及探索文本生成中的局部行為。
此外 LIT 還支持多種模型,包括分類、seq2seq 和結構化預測模型。并且它具備高度可擴展性,可通過聲明式、框架無關的 API 進行擴展。
相關 demo,參見視頻:
00:00/00:00倍速
可以針對新穎的工作流程進行重新配置,并且這些組件是獨立的,可移植的,且易于實現。
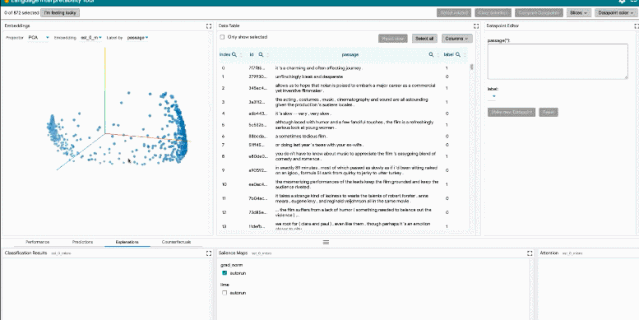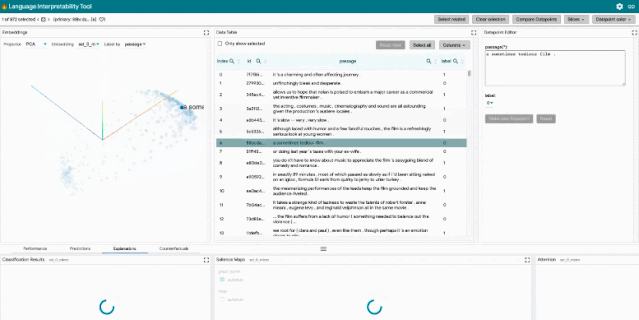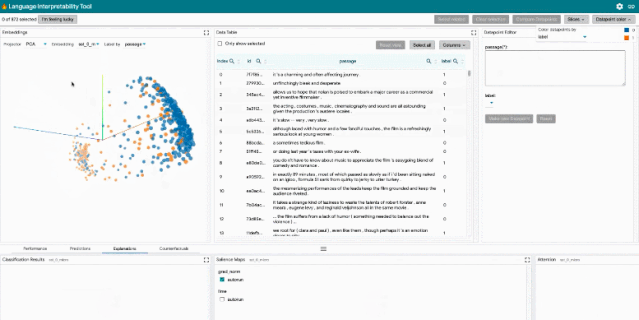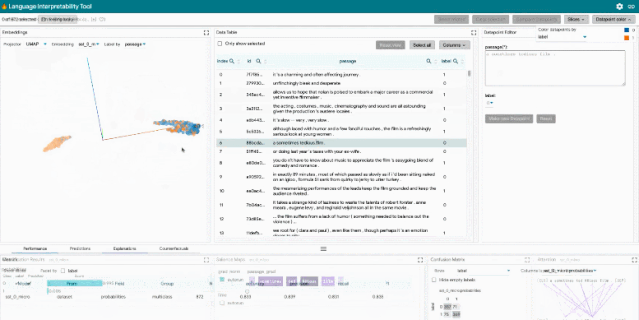
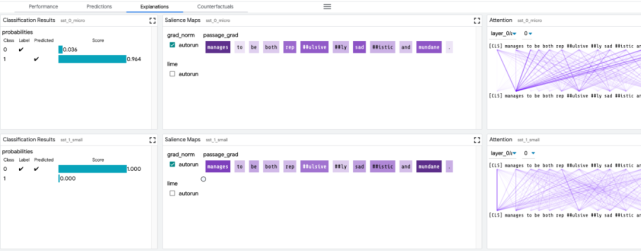
用戶界面
LIT 位于一個單頁 web 應用中,由多個工具欄和包含多個獨立模塊的主體部分組成。如果模塊適用于當前模型和數據集,它們將自動顯示。例如,顯示分類結果的模塊僅在模型返回 MulticlassPreds 時顯示。
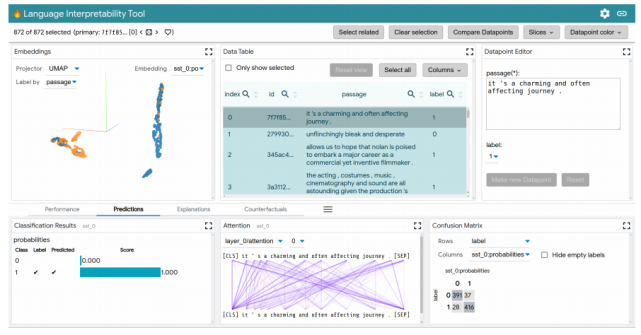
LIT 用戶界面
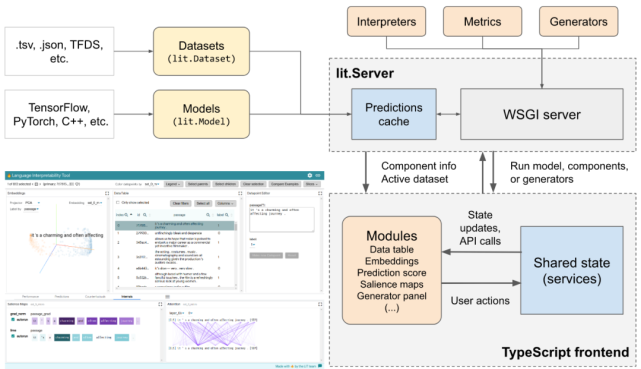
LIT 的布局設計圖。
功能
LIT 通過基于瀏覽器的用戶界面(UI)支持各種調試工作流。功能包括:
局部解釋:通過模型預測的顯著圖、注意力和豐富可視化圖來執行。
聚合分析:包括自定義度量指標、切片和裝箱(slicing and binning),以及嵌入空間的可視化。
反事實生成:通過手動編輯或生成插件進行反事實推理,動態地創建和評估新示例。
并排模式:比較兩個或多個模型,或基于一對示例的一個模型。
高度可擴展性:可擴展到新的模型類型,包括分類、回歸、span 標注,seq2seq 和語言建模。
框架無關:與 TensorFlow、PyTorch 等兼容。
下面我們來看 LIT 的幾個主要模塊:
探索數據集:用戶可以使用不同的標準跨模塊(如數據表和嵌入模塊)交互式地探索數據集,從而旋轉、縮放和平移 PCA 或 UMAP 投影,以探索集群和全局結構。
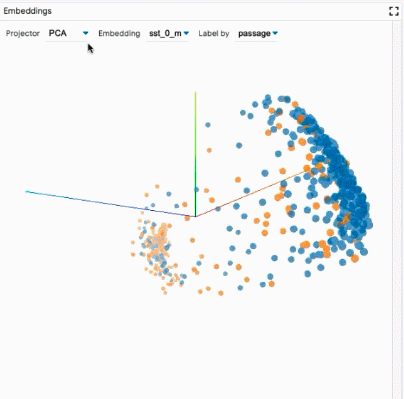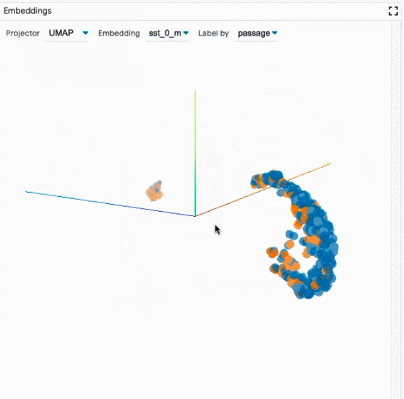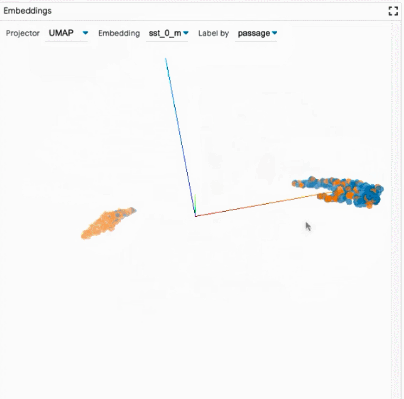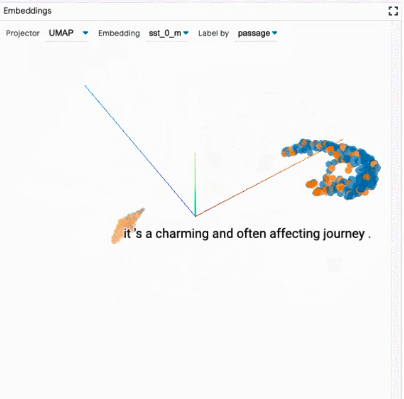
比較模型:通過在全局設置控件中加載多個模型,LIT 可以對它們進行比較。然后復制顯示每個模型信息的子模塊,以便于在兩個模型之間進行比較。其他模塊(如嵌入模塊和度量模塊)同時得到更新,以顯示所有模型的最新信息。
比較數據點:切換到選擇工具欄中的「Compare datapoints」按鈕,使 LIT 進入數據點比較模式。在這種模式下,主數據點選擇作為參考數據點,并且在后續設置中都會以其為參考點進行比較。參考數據點在數據表中以藍色邊框突出顯示。
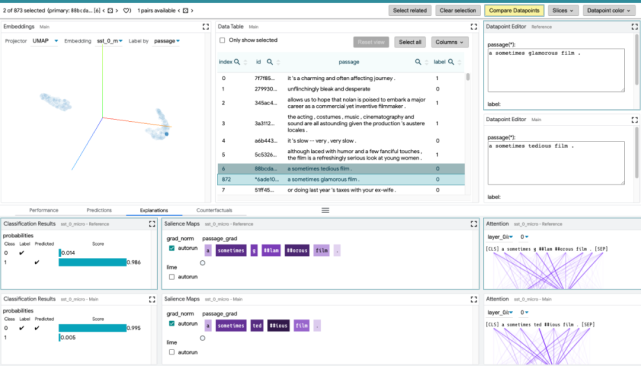
其他模塊的具體細節,參見:https://github.com/PAIR-code/lit/blob/main/docs/user_guide.md
看了上面的介紹,你是不是迫不及待地想要上手試試這個炫酷的可視化工具?下面我們來看它的安裝過程和示例。
安裝教程
下載軟件包并進行 Python 環境配置,代碼如下:
安裝并配置好環境,就可以體驗工具包中自帶的示例。
示例
1. 情緒分類示例
代碼如下:
情緒分類示例是基于斯坦福情感樹庫微調 BERT-tiny 模型,在 GPU 上不到 5 分鐘即可完成。訓練完成后,它將在開發集上啟動 LIT 服務器。
2. 語言建模類示例
要想探索預訓練模型(BERT 或 GPT-2)的預測結果,運行以下代碼:
更多的示例請參考目錄:../lit_nlp/examples。
此外,該項目還提供了添加自己模型和數據的方法。通過創建定制的 demo.py 啟動器,用戶可以輕松地用自己的模型運行 LIT,類似于上述示例目錄../lit_nlp/examples。
完整的添加過程,參見:https://github.com/PAIR-code/lit/blob/main/docs/python_api.md#adding-models-and-data。