













漫談在人工智能時代網絡入侵檢測器的安全風險之逃逸攻擊
導語
近年來,隨著人工智能的蓬勃發展,機器學習技術在網絡入侵檢測領域得到了廣泛的應用。然而,機器學習模型存在著對抗樣本的安全威脅,導致該類網絡入侵檢測器在對抗環境中呈現出特定的脆弱性。本文主要概述由對抗樣本造成的逃逸攻擊,分為上下兩篇。上篇從基本概念出發介紹逃逸攻擊的工作機理,下篇則介紹一些針對逃逸攻擊的防御措施。希望能讓讀者更清晰的認知基于機器學習的網絡入侵檢測器所存在的安全風險。
當網絡入侵檢測器遇到機器學習
網絡入侵檢測系統(Network Intrusion Detection System,NIDS)通過采集網絡流量等信息,發現被監控網絡中違背安全策略、危及系統安全的行為,是一種重要的安全防護手段。面對日益復雜的網絡環境,傳統NIDS所存在的缺點日益突出,例如系統占用資源過多、對未知攻擊檢測能力差、需要人工干預等。在此背景下,研究人員迫切地探尋新的解決方案,并將目光投向了發展迅速的機器學習技術。基于機器學習的網絡入侵檢測器是將網絡入侵檢測的問題建模成一個針對網絡流量的分類問題,從而使用一些機器學習的方法精練出分類模型進行分類預測。目前,多種機器學習算法,例如決策樹、支持向量機、深度神經網絡等,被用于區分入侵流量和良性流量,并取得了良好的實驗結果。
什么是對抗樣本
2013年,Szegedy等人首次在深度神經網絡(Deep Neural Network,DNN)中發現了對抗樣本,并引起了機器學習社區的廣泛討論。對抗樣本是指通過對原始的輸入樣本添加輕微的擾動所產生的輸入樣本,該樣本與原始樣本相近,卻能夠在不改變機器學習分類模型的情況下,導致目標模型輸出錯誤的分類結果。事實上,從傳統的機器學習模型到深度學習模型,再到強化學習模型,都存在對抗樣本的問題。鑒于目前機器學習技術已滲透到圖像識別、自然語言處理、惡意軟件檢測等多個領域,對抗樣本的發現為狂熱的機器學習應用浪潮帶來了一定的沖擊。
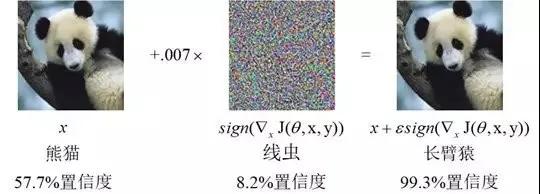
圖1 一種對抗樣本示意圖
逃逸攻擊
針對基于機器學習的NIDS,攻擊者可利用對抗樣本來逃逸NIDS對入侵流量的檢測,這種攻擊被稱為逃逸攻擊(或對抗樣本攻擊、對抗攻擊等)。圖2展示了一種經典的逃逸攻擊流程。NIDS部署在被保護網絡的邊界,通過提取數據包或網絡流的特征形成輸入樣本,然后利用機器學習分類模型來識別該樣本是否屬于入侵流量。在發動逃逸攻擊時,攻擊者首先捕獲入侵流量所形成的輸入樣本,通過一定的手段來生成對抗樣本,然后回放依據對抗樣本產生的入侵流量。由于機器學習分類模型的脆弱性,該流量被NIDS錯誤分類成良性流量,從而到達受害網絡。
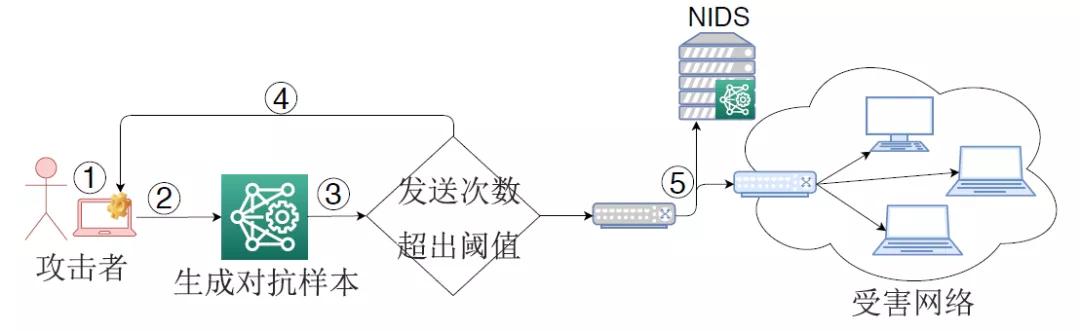
圖2 一種逃逸攻擊示意圖
威脅模型
由攻擊者發起的逃逸攻擊可以從四個維度來刻畫,分別是敵手知識、敵手能力、敵手目標、攻擊策略。其中敵手知識是指攻擊者掌握目標機器學習模型的背景信息量,包括模型的訓練數據、特征集合、模型結構及參數、學習算法及決策函數、目標模型中可用的反饋信息等。根據敵手知識,可將逃逸攻擊分為以下兩類:
(1)白盒攻擊。攻擊者在完全了解目標模型的情況下發起攻擊。在此情況下,目標模型的網絡架構及參數值、為樣本提取的特征集合、使用的訓練方法等信息都暴露給了攻擊者,另外在某些情況下還包括目標模型所使用的訓練數據集。
(2)黑盒攻擊。發起攻擊時,攻擊者僅對目標模型具有有限的知識,例如攻擊者可獲取模型的輸入和輸出的格式和數值范圍,但是不知道機器學習模型的網絡架構、訓練參數和訓練算法等。在此情況下,攻擊者一般通過傳入輸入數據來觀察輸出、判斷輸出與目標模型進行交互。
對逃逸攻擊而言,攻擊者可不具備操縱目標模型、操縱目標模型的訓練數據的能力。但是敵手能力必須包括可操縱目標模型的測試數據,即攻擊者能夠對用于測試模型的網絡流量進行修改,這種修改可以在網絡流(Flow)層進行也可以在數據包(Packet)層。對于逃逸攻擊,敵手目的是影響目標機器學習模型的完整性(Integrity)。具體地講,逃逸攻擊的敵手目標包括以下幾類:
(1)減小置信度:減小輸入分類的置信度,從而引起歧義。
(2)無目標誤分類:將輸出分類更改為與原始類不同的任何類。
(3)有目標的誤分類:強制將輸出分類為特定的目標類。
(4)源到目的誤分類:強制將特定的輸入的輸出分類為特定的目標類。
根據敵手知識和敵手目的將逃逸攻擊的威脅模型進行整合,結果如圖3所示。可以看出,黑盒模式下的有目標攻擊將會極大地增加攻擊難度。
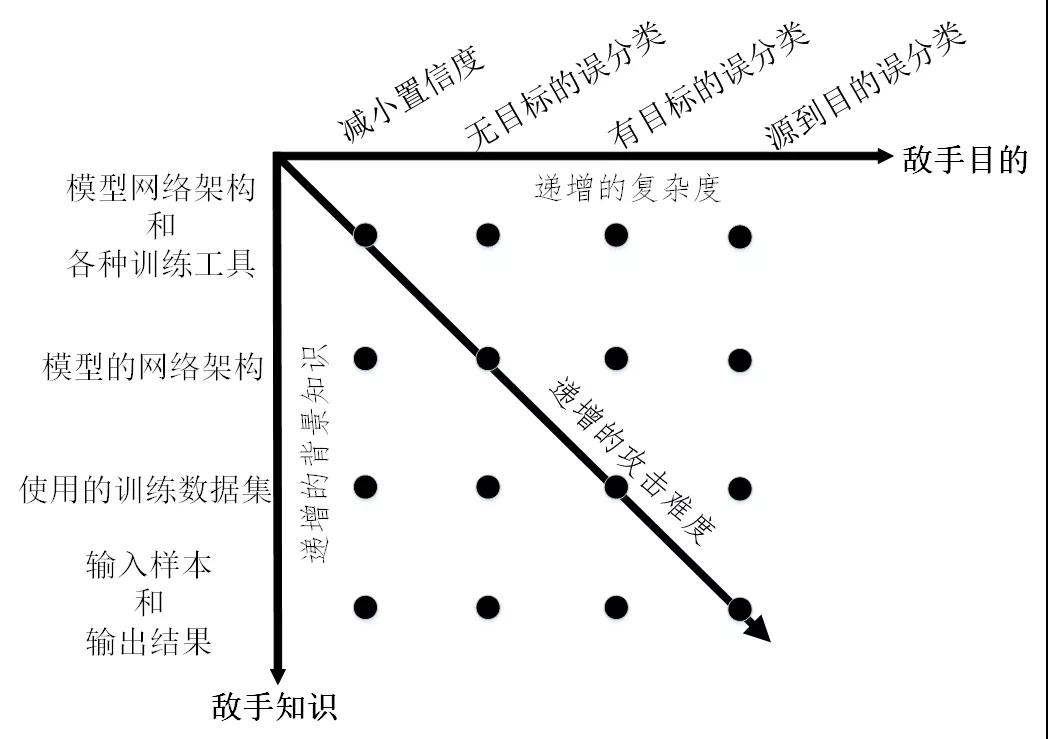
圖3 逃逸攻擊的威脅模型分類
常見的攻擊策略
逃逸攻擊的核心在于如何構造能夠使機器學習模型產生誤分類的對抗樣本。針對基于機器學習的網絡入侵檢測器,目前研究人員已提出多種生成對抗樣本的方法,主要包括以下幾類:
(1)基于梯度的方法。該類方法僅適用于白盒攻擊。在圖像識別領域,Goodfellow等人[15]提出了快速梯度符號(FGSM)法,該方法假設攻擊者完全了解目標模型,通過在梯度的反方向上添加擾動增大樣本與原始樣本的決策距離,從而快速生成對抗樣本。隨后,改進的方法例如PGD、BIM、JSMA等相繼被提出。在此基礎上,研究工作[1]-[6]都采用了這類方法來對修改網絡流層上特征,進而生成針對網絡入侵檢測器的對抗樣本。
(2)基于優化的方法。該類方法即存在于白盒攻擊又存在于黑盒攻擊。Szegedy等人[16]首次將尋找最小可能的攻擊擾動轉化為一個優化問題,并提出使用L-BFGS來解決這個分析。這種方法攻擊成功率高,但計算成本也高。Carlini等人[17]對其進行了改進,提出了攻擊效果更好的目標函數,并通過改變變量解決邊界約束問題,被稱為C&W攻擊。研究工作[4]-[6]都采用了這種方法來生成攻擊NIDS的對抗樣本。此外,文獻[12][13]研究在黑盒模式下生成對抗樣本的問題,同樣將其轉化為一種優化問題,并分別采用遺傳算法和粒子群算法來解決,從而快速搜索出對抗樣本。
(3)基于生成對抗網絡的方法。該類方法常見于發動黑盒攻擊。研究工作[7]-[9]均建立生成對抗網絡(Generative Adversarial Network,GAN)來生成對抗樣本。一般地,目標NIDS作為GAN的檢測器,GAN的生成器則用于產生對抗擾動,并且GAN檢測器對輸入樣本的預測得分將用來訓練GAN的生成器。特別地,生成網絡一旦訓練完畢,就可以有效地為任何樣本生成擾動而不需要向目標NIDS發送任何問詢。
(3)基于決策的方法。該類方法適用于在黑盒模式下發動攻擊。在真實的逃逸攻擊中,攻擊者很少能夠獲取目標模型的預測值,針對目標模型僅給出類別標簽的情況,Peng等人[14]提出了改進的邊界攻擊方法來生成DDoS攻擊的對抗樣本。該方法的主要思想是通過迭代地修改輸入樣本來逼近目標模型的決策邊界。此外,研究工作[10]同樣采用基于決策的思想,借助有限的目標NIDS的反饋,不斷的在數據包層次上或網絡流層次上修改NIDS的原始輸入樣本,從而生成逃逸的變異樣本。與其它方法相比,該類方法需要的模型信息更少、實用性更高,但是需要向目標NIDS發送大量的問詢,需要更高的攻擊代價。
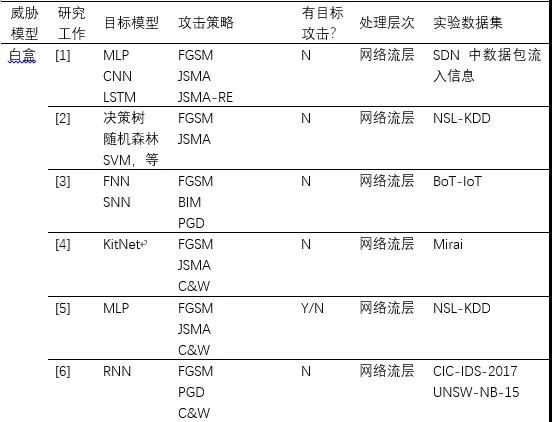
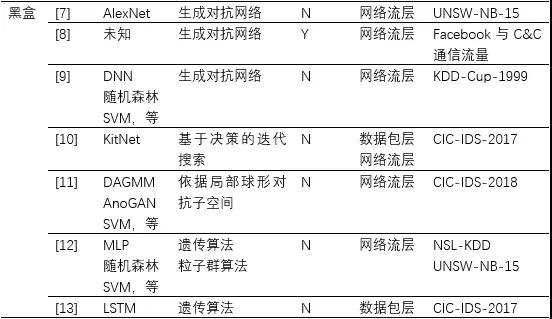
表1 逃逸攻擊的相關研究工作
小結:
機器學習為網絡入侵檢測提供了新的解決思路,同時也帶來了新的安全隱患。在機器學習成為網絡安全利器的道路上,攻擊與防御之間博弈不斷升級,“機器學習+網絡安全”的研究依然任重道遠。
參考文獻
[1] Chi-Hsuan Huang, Tsung-Han Lee, Lin-huang Chang,等. Adversarial Attacks on SDN-Based Deep Learning IDS System[C]. International Conference on Mobile & Wireless Technology. Springer, Singapore, 2018.
[2] M. Rigaki. Adversarial Deep Learning Against Intrusion Detection Classifiers. Dissertation, 2017.
[3] Ibitoye O, Shafiq O, Matrawy A, et al. Analyzing Adversarial Attacks against Deep Learning for Intrusion Detection in IoT Networks[C]. global communications conference, 2019.
[4] Clements J, Yang Y, Sharma A A, et al. Rallying Adversarial Techniques against Deep Learning for Network Security.[J]. arXiv: Cryptography and Security, 2019.
[5] Wang Z. Deep Learning-Based Intrusion Detection With Adversaries[J]. IEEE Access, 2018: 38367-38384.
[6] Hartl A, Bachl M, Fabini J, et al. Explainability and Adversarial Robustness for RNNs.[J]. arXiv: Learning, 2019.
[7] 潘一鳴, 林家駿. 基于生成對抗網絡的惡意網絡流生成及驗證[J]. 華東理工大學學報(自然科學版), 2019, 45(02):165-171.
[8] Rigaki M, Garcia S. Bringing a GAN to a Knife-Fight: Adapting Malware Communication to Avoid Detection[C]. ieee symposium on security and privacy, 2018: 70-75.
[9] Usama M, Asim M, Latif S, et al. Generative Adversarial Networks For Launching and Thwarting Adversarial Attacks on Network Intrusion Detection Systems[C]. international conference on wireless communications and mobile computing, 2019: 78-83.
[10] Hashemi, M. J., Cusack, G, et al. Towards Evaluation of NIDSs in Adversarial Setting. the 3rd ACM CoNEXT Workshop on Big Data, Machine Learning and Artificial Intelligence for Data
Communication Networks. 2019: 14-21.
[11] Kuppa A, Grzonkowski S, Asghar M R, et al. Black Box Attacks on Deep Anomaly Detectors[C]. availability, reliability and security, 2019.
[12] Alhajjar, E, Paul M and Nathanie D. B. Adversarial Machine Learning in Network Intrusion Detection Systems. arXiv preprint arXiv:2004.11898 (2020).
[13] Huang W, Peng X, Shi Z, et al. Adversarial Attack against LSTM-based DDoS Intrusion Detection System. arXiv preprint arXiv:2613.1684 (2020).
[14] Peng X, Huang W, Shi Z, et al. Adversarial Attack Against DoS Intrusion Detection: An Improved Boundary-Based Method[C]. international conference on tools with artificial intelligence, 2019.
[15] Goodfellow I J , Shlens J , Szegedy C . Explaining and harnessing adversarial examples[C]// ICML. 2015.
[16] Szegedy, C, et al. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199 (2013).
[17] Carlini N , Wagner D . Towards Evaluating the Robustness of Neural Networks[J]. 2016.

【本文為51CTO專欄作者“中國保密協會科學技術分會”原創稿件,轉載請聯系原作者】























