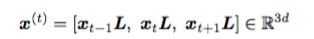用Keras+LSTM+CRF的實踐命名實體識別NER
文本分詞、詞性標注和命名實體識別都是自然語言處理領域里面很基礎的任務,他們的精度決定了下游任務的精度,其實在這之前我并沒有真正意義上接觸過命名實體識別這項工作,雖然說讀研期間斷斷續續也參與了這樣的項目,但是畢業之后始終覺得一知半解的感覺,最近想重新撿起來,以實踐為學習的主要手段來比較系統地對命名實體識別這類任務進行理解、學習和實踐應用。
當今的各個應用里面幾乎不會說哪個任務會沒有深度學習的影子,很多子任務的發展歷程都是驚人的相似,最初大部分的研究和應用都是集中在機器學習領域里面,之后隨著深度學習模型的發展,也被廣泛應用起來了,命名實體識別這樣的序列標注任務自然也是不例外的,早就有了基于LSTM+CRF的深度學習實體識別的相關研究了,只不過與我之前的方向不一致,所以一直沒有化太多的時間去關注過它,最近正好在學習NER,在之前的相關文章中已經基于機器學習的方法實踐了簡單的命名實體識別了,這里以深度學習模型為基礎來實現NER。
命名實體識別屬于序列標注任務,其實更像是分類任務,NER是在一段文本中,將預先定義好的實體類型識別出來。
NER是一種序列標注問題,因此他們的數據標注方式也遵照序列標注問題的方式,主要是BIO和BIOES兩種。這里直接介紹BIOES,明白了BIOES,BIO也就掌握了。
先列出來BIOES分別代表什么意思:
- B,即Begin,表示開始
- I,即Intermediate,表示中間
- E,即End,表示結尾
- S,即Single,表示單個字符
- O,即Other,表示其他,用于標記無關字符
比如對于下面的一句話:
- 姚明去哈爾濱工業大學體育館打球了
標注結果為:
- 姚明 去 哈爾濱工業大學 體育館 打球 了
- B-PER E-PER O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG E-ORG B-LOC I-LOC E-LOC O O O
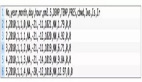
簡單的溫習就到這里了,接下來進入到本文的實踐部分,首先是數據集部分,數據集來源于網絡獲取,簡單看下樣例數據,如下所示:
train_data部分樣例數據如下所示:
- 當 O
- 希 O
- 望 O
- 工 O
- 程 O
- 救 O
- 助 O
- 的 O
- 百 O
- 萬 O
- 兒 O
- 童 O
- 成 O
- 長 O
- 起 O
- 來 O
- , O
- 科 O
- 教 O
- 興 O
- 國 O
- 蔚 O
- 然 O
- 成 O
- 風 O
- 時 O
- , O
- 今 O
- 天 O
- 有 O
- 收 O
- 藏 O
- 價 O
- 值 O
- 的 O
- 書 O
- 你 O
- 沒 O
- 買 O
- , O
- 明 O
- 日 O
- 就 O
- 叫 O
- 你 O
- 悔 O
- 不 O
- 當 O
- 初 O
- !O
test_data部分樣例數據如下所示:
- 高 O
- 舉 O
- 愛 O
- 國 O
- 主 O
- 義 O
- 和 O
- 社 O
- 會 O
- 主 O
- 義 O
- 兩 O
- 面 O
- 旗 O
- 幟 O
- , O
- 團 O
- 結 O
- 全 O
- 體 O
- 成 O
- 員 O
- 以 O
- 及 O
- 所 O
- 聯 O
- 系 O
- 的 O
- 歸 O
- 僑 O
- 、 O
- 僑 O
- 眷 O
- , O
- 發 O
- 揚 O
- 愛 O
- 國 O
- 革 O
- 命 O
- 的 O
- 光 O
- 榮 O
- 傳 O
- 統 O
- , O
- 為 O
- 統 O
- 一 O
- 祖 O
- 國 O
- 、 O
- 振 O
- 興 O
- 中 B-LOC
- 華 I-LOC
- 而 O
- 努 O
- 力 O
- 奮 O
- 斗 O
- ;O
簡單了解訓練集數據和測試集數據結構后就可以進行后面的數據處理,主要的目的就是生成特征數據,核心代碼實現如下所示:
- with open('test_data.txt',encoding='utf-8') as f:
- test_data_list=[one.strip().split('\t') for one in f.readlines() if one.strip()]
- with open('train_data.txt',encoding='utf-8') as f:
- train_data_list=[one.strip().split('\t') for one in f.readlines() if one.strip()]
- char_list=[one[0] for one in test_data_list]+[one[0] for one in train_data_list]
- label_list=[one[-1] for one in test_data_list]+[one[-1] for one in train_data_list]
- print('char_list_length: ', len(char_list))
- print('label_list_length: ', len(label_list))
- print('char_num: ', len(list(set(char_list))))
- print('label_num: ', len(list(set(label_list))))
- char_count,label_count={},{}
- #字符頻度統計
- for one in char_list:
- if one in char_count:
- char_count[one]+=1
- else:
- char_count[one]=1
- for one in label_list:
- if one in label_count:
- label_count[one]+=1
- else:
- label_count[one]=1
- #按頻度降序排序
- sortedsorted_char=sorted(char_count.items(),key=lambda e:e[1],reverse=True)
- sortedsorted_label=sorted(label_count.items(),key=lambda e:e[1],reverse=True)
- #字符-id映射關系構建
- char_map_dict={}
- label_map_dict={}
- for i in range(len(sorted_char)):
- char_map_dict[sorted_char[i][0]]=i
- char_map_dict[str(i)]=sorted_char[i][0]
- for i in range(len(sorted_label)):
- label_map_dict[sorted_label[i][0]]=i
- label_map_dict[str(i)]=sorted_label[i][0]
- #結果存儲
- with open('charMap.json','w') as f:
- f.write(json.dumps(char_map_dict))
- with open('labelMap.json','w') as f:
- f.write(json.dumps(label_map_dict))
代碼實現的很清晰,關鍵的部分也都有對應的注釋內容,這里就不多解釋了,核心的思想就是將字符或者是標簽類別數據映射為對應的index數據,這里我沒有對頻度設置過濾閾值,有的實現里面會過濾掉只出現了1次的數據,這個可以根據自己的需要進行對應的修改。
charMap數據樣例如下所示:
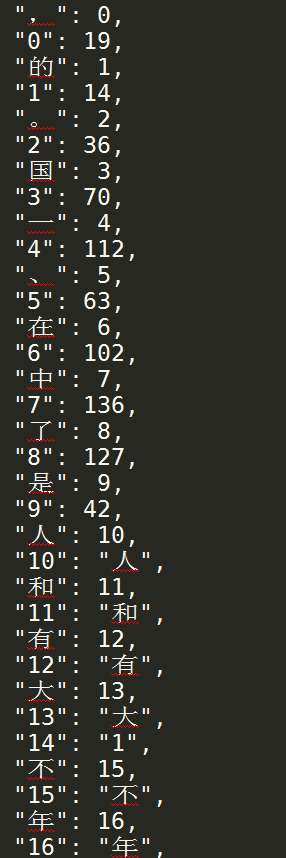
labelMap數據樣例如下所示:
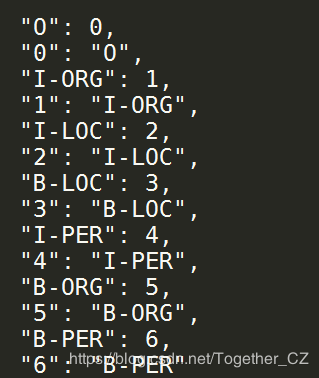
在生成上述映射數據之后,就可以對原始的文本數據進行轉化計算,進而生成我們所需要的特征數據了,核心代碼實現如下所示:
- X_train,y_train,X_test,y_test=[],[],[],[]
- #訓練數據集
- for i in range(len(trainData)):
- one_sample=[one.strip().split('\t') for one in trainData[i]]
- char_list=[O[0] for O in one_sample]
- label_list=[O[1] for O in one_sample]
- char_vec=[char_map_dict[char_list[v]] for v in range(len(char_list))]
- label_vec=[label_map_dict[label_list[l]] for l in range(len(label_list))]
- X_train.append(char_vec)
- y_train.append(label_vec)
- #測試數據集
- for i in range(len(testData)):
- one_sample=[one.strip().split('\t') for one in testData[i]]
- char_list=[O[0] for O in one_sample]
- label_list=[O[1] for O in one_sample]
- char_vec=[char_map_dict[char_list[v]] for v in range(len(char_list))]
- label_vec=[label_map_dict[label_list[l]] for l in range(len(label_list))]
- X_test.append(char_vec)
- y_test.append(label_vec)
- feature={}
- feature['X_train'],feature['y_train']=X_train,y_train
- feature['X_test'],feature['y_test']=X_test,y_test
- #結果存儲
- with open('feature.json','w') as f:
- f.write(json.dumps(feature))
到這里我們已經得到了我們所需要的特征數據,且已經劃分好了測試集數據和訓練集數據。
接下來就可以構建模型了,這里為了簡化實現,我采用的是Keras框架,相比于原生態的Tensorflow框架來說,上手門檻更低,核心代碼實現如下所示:
- #加載數據集
- with open('feature.json') as f:
- F=json.load(f)
- X_train,X_test,y_train,y_test=F['X_train'],F['X_test'],F['y_train'],F['y_test']
- #數據對齊操作
- X_train = pad_sequences(X_train, maxlen=max_len, value=0)
- y_train = pad_sequences(y_train, maxlen=max_len, value=-1)
- y_train = np.expand_dims(y_train, 2)
- X_test = pad_sequences(X_test, maxlen=max_len, value=0)
- y_test = pad_sequences(y_test, maxlen=max_len, value=-1)
- y_test = np.expand_dims(y_test, 2)
- #模型初始化、訓練
- if not os.path.exists(saveDir):
- os.makedirs(saveDir)
- #模型初始化
- model = Sequential()
- model.add(Embedding(voc_size, 256, mask_zero=True))
- model.add(Bidirectional(LSTM(128, return_sequences=True)))
- model.add(Dropout(rate=0.5))
- model.add(Dense(tag_size))
- crf = CRF(tag_size, sparse_target=True)
- model.add(crf)
- model.summary()
- model.compile('adam', loss=crf.loss_function, metrics=[crf.accuracy])
- #訓練擬合
- history=model.fit(X_train,y_train,batch_size=100,epochs=500,validation_data=[X_test,y_test])
- model.save(saveDir+'model.h5')
- #模型結構可視化
- try:
- plot_model(model,to_file=saveDir+"model_structure.png",show_shapes=True)
- except Exception as e:
- print('Exception: ', e)
- #結果可視化
- plt.clf()
- plt.plot(history.history['acc'])
- plt.plot(history.history['val_acc'])
- plt.title('model accuracy')
- plt.ylabel('accuracy')
- plt.xlabel('epochs')
- plt.legend(['train','test'], loc='upper left')
- plt.savefig(saveDir+'train_validation_acc.png')
- plt.clf()
- plt.plot(history.history['loss'])
- plt.plot(history.history['val_loss'])
- plt.title('model loss')
- plt.ylabel('loss')
- plt.xlabel('epochs')
- plt.legend(['train', 'test'], loc='upper left')
- plt.savefig(saveDir+'train_validation_loss.png')
- scores=model.evaluate(X_test,y_test,verbose=0)
- print("Accuracy: %.2f%%" % (scores[1]*100))
- modelmodel_json=model.to_json()
- with open(saveDir+'structure.json','w') as f:
- f.write(model_json)
- model.save_weights(saveDir+'weight.h5')
- print('===Finish====')
訓練完成后,結構目錄文件結構如下所示:

模型結構圖如下所示:
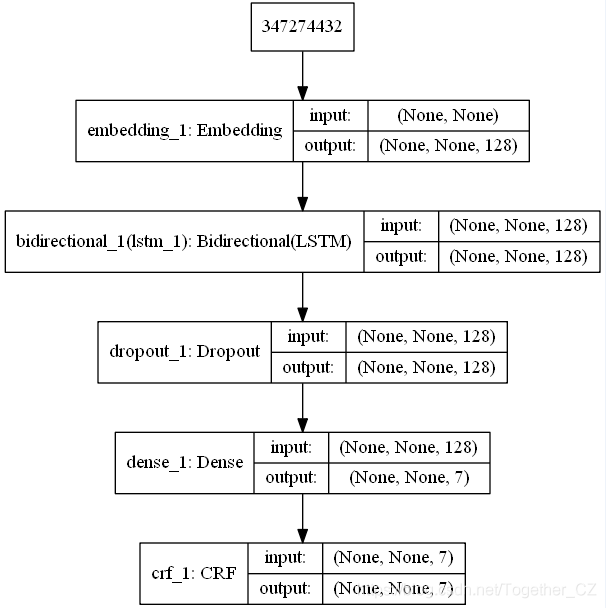
訓練過程中準確度曲線如下所示:
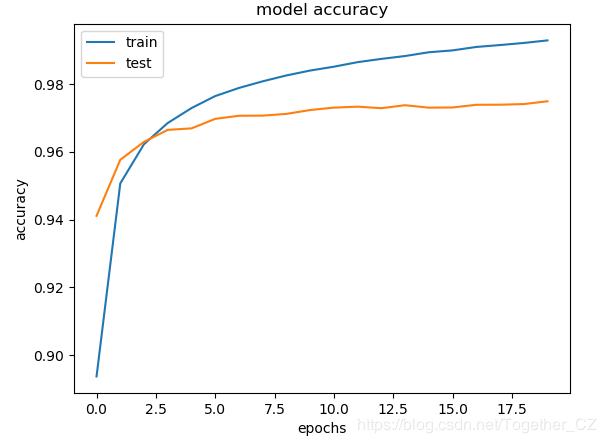
訓練過程中損失值曲線如下所示:
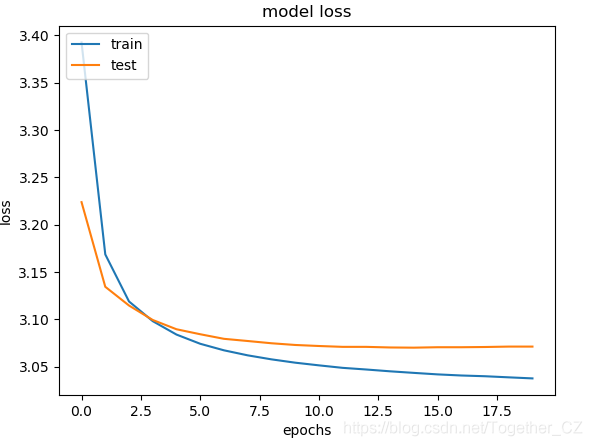
由于訓練計算資源占用比較大,且時間比較長,我這里只是簡單地設置了20次的迭代計算,這個可以根據自己的實際情況設置更高的或者是更低的迭代次數來實現不同的需求。
簡單的預測實例如下所示:


到這里,本文的實踐就結束了,后面有時間繼續深入研究,希望對您有所幫助,祝您工作順利,學有所成!