卷積神經網絡實戰——使用keras識別貓咪
在近些年,深度學習領域的卷積神經網絡(CNNs或ConvNets)在各行各業為我們解決了大量的實際問題。但是對于大多數人來說,CNN仿佛戴上了神秘的面紗。我經常會想,要是能將神經網絡的過程分解,看一看每一個步驟是什么樣的結果該有多好!這也就是這篇博客存在的意義。
高級CNN
首先,我們要了解一下卷積神經網絡擅長什么。CNN主要被用來找尋圖片中的模式。這個過程主要有兩個步驟,首先要對圖片做卷積,然后找尋模式。在神經網絡中,前幾層是用來尋找邊界和角,隨著層數的增加,我們就能識別更加復雜的特征。這個性質讓CNN非常擅長識別圖片中的物體。
CNN是什么
CNN是一種特殊的神經網絡,它包含卷積層、池化層和激活層。
卷積層
要想了解什么是卷積神經網絡,你首先要知道卷積是怎么工作的。想象你有一個5*5矩陣表示的圖片,然后你用一個3*3的矩陣在圖片中滑動。每當3*3矩陣經過的點就用原矩陣中被覆蓋的矩陣和這個矩陣相乘。這樣一來,我們可以使用一個值來表示當前窗口中的所有點。下面是一個過程的動圖:
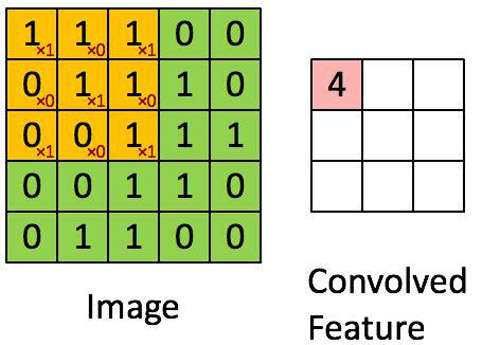
正如你所見的那樣,特征矩陣中的每一個項都和原圖中的一個區域相關。
在圖中像窗口一樣移動的叫做核。核一般都是方陣,對于小圖片來說,一般選用3*3的矩陣就可以了。每次窗口移動的距離叫做步長。值得注意的是,一些圖片在邊界會被填充零,如果直接進行卷積運算的話會導致邊界處的數據變小(當然圖片中間的數據更重要)。
卷積層的主要目的是濾波。當我們在圖片上操作時,我們可以很容易得檢查出那部分的模式,這是由于我們使用了濾波,我們用權重向量乘以卷積之后的輸出。當訓練一張圖片時,這些權重會不斷改變,而且當遇到之前見過的模式時,相應的權值會提高。來自各種濾波器的高權重的組合讓網絡預測圖像的內容的能力。 這就是為什么在CNN架構圖中,卷積步驟由一個框而不是一個矩形表示; 第三維代表濾波器。
注意事項:
卷積運算后的輸出無論在寬度上還是高度上都比原來的小
核和圖片窗口之間進行的是線性的運算
濾波器中的權重是通過許多圖片學習的
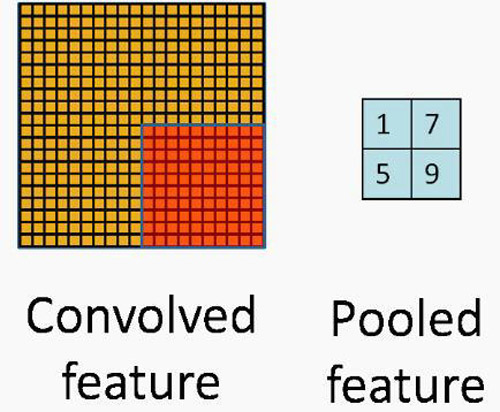
池化層
池化層和卷積層很類似,也是用一個卷積核在圖上移動。唯一的不同就是池化層中核和圖片窗口的操作不再是線性的。
***池化和平均池化是最常見的池化函數。***池化選取當前核覆蓋的圖片窗口中***的數,而平均池化則是選擇圖片窗口的均值。
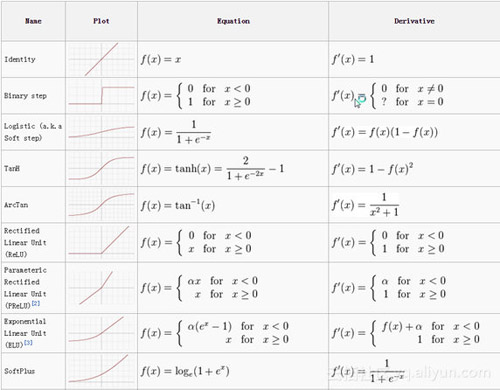
激活層
在CNN中,激活函數和其他網絡一樣,函數將數值壓縮在一個范圍內。下面列出了一些常見的函數。
在CNN中最常用的是relu(修正線性單元)。人們有許多喜歡relu的理由,但是最重要的一點就是它非常的易于實現,如果數值是負數則輸出0,否則輸出本身。這種函數運算簡單,所以訓練網絡也非常快。
回顧:
CNN中主要有三種層,分別是:卷積層、池化層和激活層。
卷積層使用卷積核和圖片窗口相乘,并使用梯度下降法去優化卷積核。
池化層使用***值或者均值來描述一個圖形窗口。
激活層使用一個激活函數將輸入壓縮到一個范圍中,典型的[0,1][-1,1]。
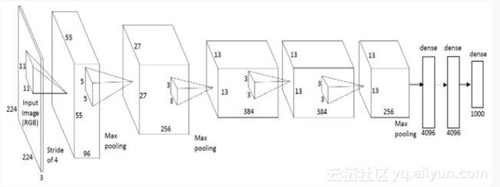
CNN是什么樣的呢?
在我們深入了解CNN之前,讓我們先補充一些背景知識。早在上世紀90年代,Yann LeCun就使用CNN做了一個手寫數字識別的程序。而隨著時代的發展,尤其是計算機性能和GPU的改進,研究人員有了更加豐富的想象空間。 2010年斯坦福的機器視覺實驗室發布了ImageNet項目。該項目包含1400萬帶有描述標簽的圖片。這個幾乎已經成為了比較CNN模型的標準。目前,***的模型在這個數據集上能達到94%的準確率。人們不斷的改善模型來提高準確率。在2014年GoogLeNet 和VGGNet成為了***的模型,而在此之前是ZFNet。CNN應用于ImageNet的***個可行例子是AlexNet,在此之前,研究人員試圖使用傳統的計算機視覺技術,但AlexNet的表現要比其他一切都高出15%。讓我們一起看一下LeNet:
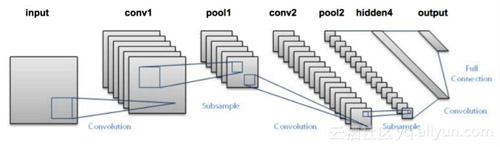
這個圖中并沒有顯示激活層,整個的流程是:
輸入圖片 →卷積層 →Relu → ***池化→卷積層 →Relu→ ***池化→隱藏層 →Softmax (activation)→輸出層。
讓我們一起看一個實際的例子
下圖是一個貓的圖片:
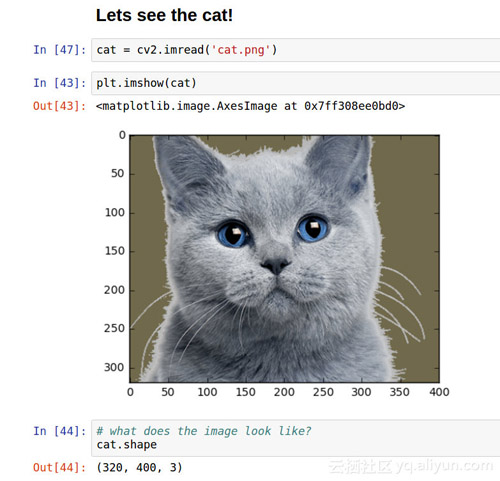
這張圖長400像素寬320像素,有三個通道(rgb)的顏色。
那么經過一層卷積運算之后會變成什么樣子呢?
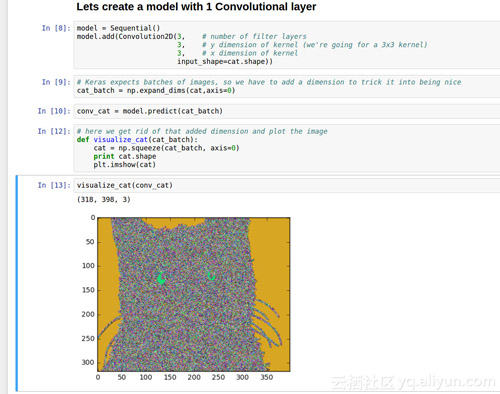
這是用一個3*3的卷積核和三個濾波器處理的效果(如果我們有超過3個的濾波器,那么我可以畫出貓的2d圖像。更高維的話就很難處理)
我們可以看到,圖中的貓非常的模糊,因為我們使用了一個隨機的初始值,而且我們還沒有訓練網絡。他們都在彼此的頂端,即使每層都有細節,我們將無法看到它。但我們可以制作出與眼睛和背景相同顏色的貓的區域。如果我們將內核大小增加到10x10,會發生什么呢?
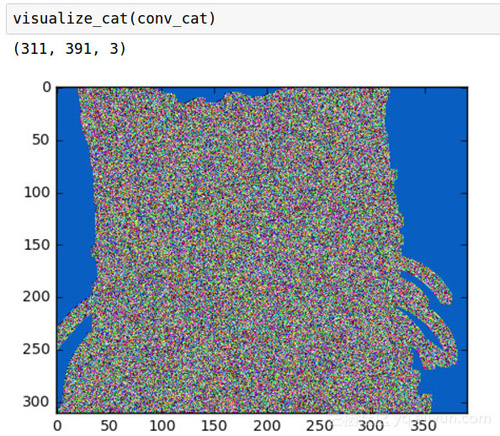
我們可以看到,由于內核太大,我們失去了一些細節。還要注意,從數學角度來看,卷積核越大,圖像的形狀會變得越小。
如果我們把它壓扁一點,我們可以更好的看到色彩通道會發生什么?
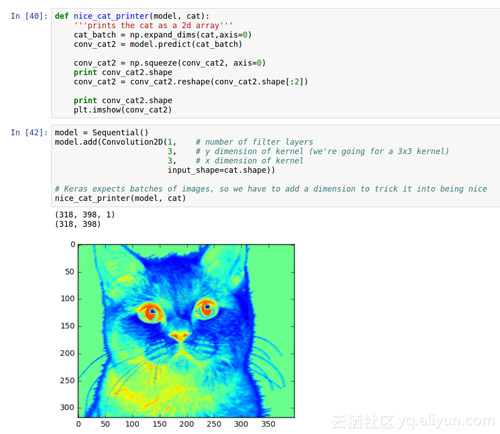
這張看起來好多了!現在我們可以看到我們的過濾器看到的一些事情。看起來紅色替換掉了黑色的鼻子和黑色眼睛,藍色替換掉了貓邊界的淺灰色。我們可以開始看到圖層如何捕獲照片中的一些更重要的細節。
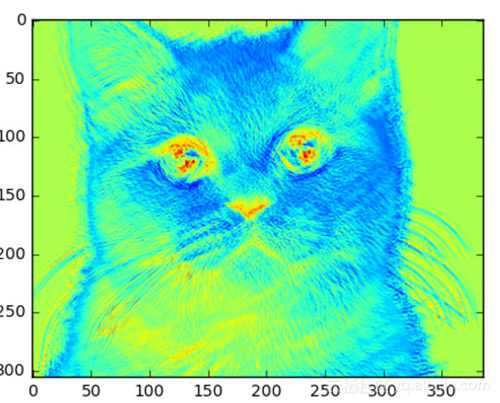
如果我們增加內核大小,我們得到的細節就會越來越明顯,當然圖像也比其他兩個都小。
增加一個激活層
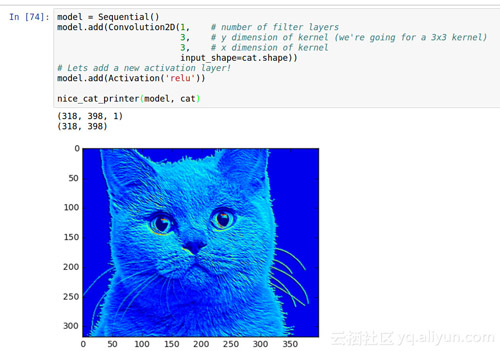
我們通過添加一個relu,去掉了很多不是藍色的部分。
增加一個池化層
我們添加一個池化層(擺脫激活層***限度地讓圖片更加更容易顯示)。
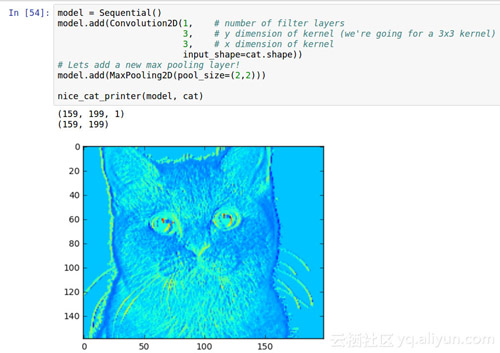
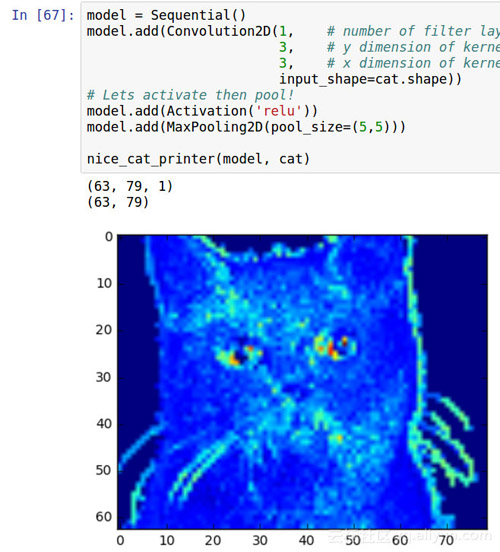
正如預期的那樣,貓咪變成了斑駁的,而我們可以讓它更加斑駁。
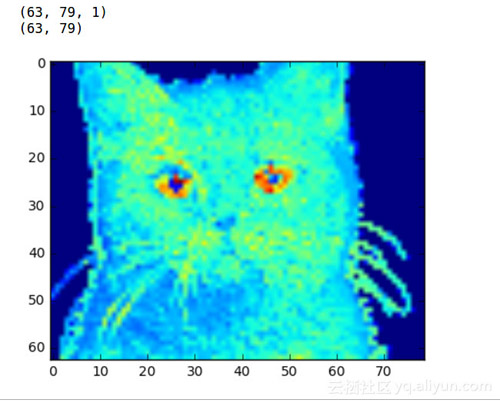
現在圖片大約成了原來的三分之一。
激活和***池化
LeNet
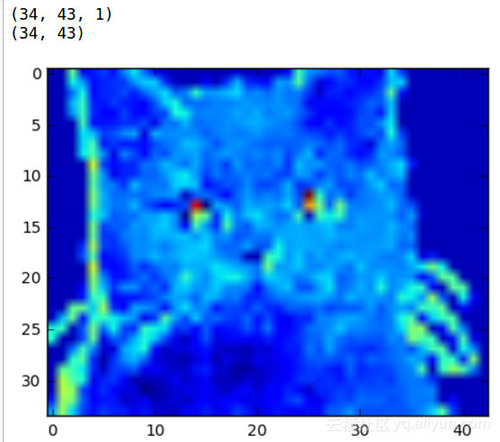
如果我們將貓咪的圖片放到LeNet模型中做卷積和池化,那么效果會怎么樣呢?
總結
ConvNets功能強大,因為它們能夠提取圖像的核心特征,并使用這些特征來識別包含其中的特征的圖像。即使我們的兩層CNN,我們也可以開始看到網絡正在對貓的晶須,鼻子和眼睛這樣的地區給予很多的關注。這些是讓CNN將貓與鳥區分開的特征的類型。
CNN是非常強大的,雖然這些可視化并不***,但我希望他們能夠幫助像我這樣正在嘗試更好地理解ConvNets的人。