













程序員過關斬將--應對高并發系統有沒有通用的解決方案呢?
靈魂拷問:
- 應對高并發系統有沒有一些通用的解決方案呢?
- 這些方案解決了什么問題呢?
- 這些方案有那些優勢和劣勢呢?
對性能孜孜不倦的追求是互聯網技術不斷發展的根本驅動力,從最初的大型機到現在的微型機,在本質上也是為了性能而生。軟件系統也存在類似的現象,一個系統從最初的少量訪問請求到后期的大并發請求,這都需要我們對性能的提升提供一系列解決方案。像最初的淘寶,也僅僅是一個外包做出來的產品,隨著業務的不斷發展,淘寶的并發量指數級增加,同時對系統提出了嚴峻的挑戰,這才逐步造就了現在淘寶這樣可以支撐數千萬人同時在線的高并發系統。
提起應對高并發,每個人都或多或少可以說出幾種解決方案,高并發系統的設計魅力在于我們能夠憑借程序員的聰明才智設計巧妙的方案,從而應對巨大流量的沖擊。從目前已知的方案中,大體可以歸納為以下幾種
提升單機性能
盡可能的提升單機的性能是一個永恒的話題,無論是采用分布式還是其他方案,單機性能的提高,對于一個系統來說只有益處。拿編程語言來說,c或者c++語言編寫的程序理論上會比java ,net,Python寫的程序要高效,當然這需要建立在程序正常運行的情況下。提升單機性能最簡單粗暴的方式就是提升硬件性能,舉一個簡單例子:假如數據庫DB的服務器內存為8G,隨著數據量的增加,你會發現有些sql執行會慢慢的變慢,原因是數據庫的索引或者數據在內存中完全存放不下,需要回寫磁盤,有些查詢在內存中并不能命中,造成了一些sql會在磁盤中查詢數據,這個時候如果把服務器的內存增加到16G,你會發現這些慢sql居然憑空消失了,這是硬件提升性能的一個典型案例。
對于運行的程序也是同樣的道理,盡可能的把程序優化到極致,也許單機就可以達到別人分布式部署的性能效果,當然這需要我們在編寫代碼的時候仔細構思。
“無論什么時候,我覺得提升單機性能都有必要
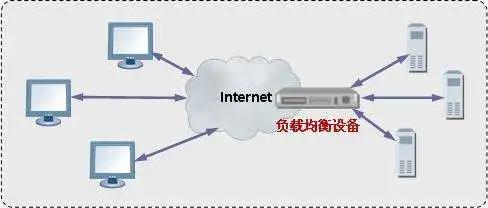
橫向擴展
當一個單機系統無法抵抗巨大流量沖擊的時候,最簡單有效的解決方案之一便是橫向擴展,橫向擴展是指把巨大的流量分割為數個比較小的流量,從而解決高并發系統的性能問題,本質上,橫向擴展屬于分而治之的理論,屬于分布式的概念范疇。
舉一個很簡單的例子,假設目前單機處理請求數為200/s,當每秒的請求數到達1000的時候,單臺機器肯定會遇到瓶頸,這個時候如果處理請求的服務器增加到5臺,甚至更多,這樣便輕松解決了性能問題。當然,能否方便的橫向擴展還要看具體的系統設計,如果系統是無狀態的,理論上橫向擴展是沒問題的,但是一些有狀態的服務,可能會涉及到狀態的遷移等工作,這也是為什么很多架構師提倡無狀態服務的一個原因。
一個應用程序的橫向擴展可以通過負載均衡來實現,像阿里云的SLB服務,nginx的反向代理功能,這些都可以很方便實現應用程序的橫向擴展。但是,像數據庫比如mysql,這樣的DB系統,無限制的橫向擴展可能只是一個目標。大多數DB采用的主從或者多主多從來解決橫向擴展問題,主節點負責寫操作,從節點負責讀操作,當然這里涉及到主從同步的機制,主從同步的延遲等問題,有興趣的同學可以去深入研究一下。
image
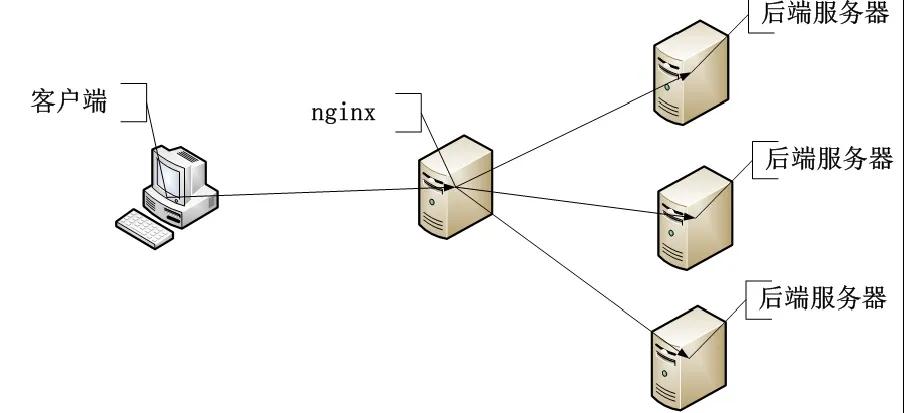
那什么時候該選擇橫向擴展呢?一般來講,在系統的設計之初便會考慮橫向擴展,因為這種方案足夠簡單,可以用堆砌硬件來解決的問題就不是問題。現在我敢說90%以上的系統在第一版上線的時候就做了類似負載均衡的部署方案,其中有很多就利用了nginx的反向代理功能。
image
當然橫向擴展并非沒有負面影響,和單機系統一樣,橫向擴展也要考慮某個節點down掉的問題,所以監控和健康檢查是現在一個系統必備的手段,而且在系統設計之初便會在整體架構之中。就像我前幾篇的文章所說,橫向擴展既然屬于分布式范疇,必然需要考慮分布式系統需要考慮的問題:
分布式系統的問題
緩存除了上面所說的橫向擴展方案,另外一種行之有效并且足夠簡單的便是緩存方案。這一點毋庸置疑,緩存可以遍布在一個系統的各個角落,從操作系統到瀏覽器,從cpu到磁盤,從數據庫到消息隊列,任何稍微復雜的服務和組件中都有緩存的影子。
緩存為什么可以大幅度提高性能的性能呢?這還需要從系統的瓶頸來說,在客戶端一個請求的生命周期中,這個請求的響應時間嚴重受限于最慢的那個環節,這類似于木桶效應(一個木桶可以存的水量,取決于最短那個木板)。
舉一個很簡單的例子:當客戶端請求商城的一個商品信息的時候,請求經過http協議到達服務器的某個端口,服務端程序把請求解包然后去請求數據庫,數據庫不單單在另外一臺服務器上,而且還需要從磁盤中加載數據,所謂的DB緩存沒有命中。在這整個過程中,請求磁盤的過程是最慢的,普通磁盤是由機械手臂,磁頭,轉軸,盤片組成,磁盤在查詢數據的時候,磁頭是需要花費很長時間累尋道的,當然SSD的速度要比普通磁盤快的多,但是相比較內存還是要慢幾個量級。而我們最想要的流程是這樣的:當一個請求到達服務端的時候能盡快的從某個設備上取出信息,然后返給客戶端,這個設備絕不可能是磁盤,這個設備在速度和容量上比較均衡,它應該是內存。
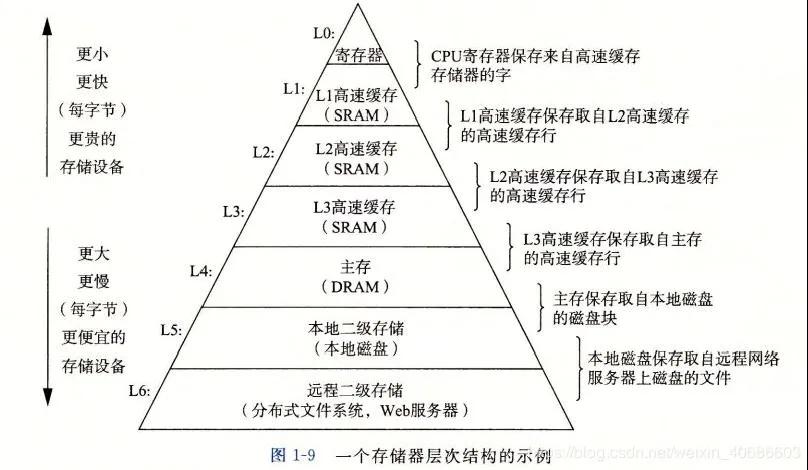
“緩存在語義上要豐富很多,我們可以把任何可以降低響應時間的中間存儲都稱之為緩存。比如CPU的一級緩存,二級緩存,三級緩存,瀏覽器的緩存等。緩存主要解決了上下游設備速度不匹配的問題
image
程序界有一句古話:把數據放在離用戶最近的地方才是最快的。CDN本質上就是做的這件事。對于緩存而言,我們經常會聽到瀏覽器緩存,進程內緩存,進程外緩存等概念。目前針對于服務端一般的緩存策略為采用第三方kv存儲設備,比如redis,Memcache等。當然在對性能極其苛刻的系統中,我還是推薦使用進程內緩存。
異步談到異步,必須要說下同步,同步調用是指調用方要阻塞等待被調用方執行完畢才可以返回。系統現在普遍都會采用多線程的方式來提供系統的吞吐量(多進程的方式現在很少,但不代表沒有,比如:nodejs,nginx),在同步這種方式下,如果被調用方的響應時間過長,會造成調用方的線程長時間處于等待狀態,線程的利用率大幅度降低,線程對于系統來說,是很昂貴的資源,創建大量的線程去應對高并發是不明智的,不僅僅浪費了內存,而且會加大線程上下文cpu切換的成本。
一個高吞吐量的系統,理論上所有的線程都要時時刻刻在工作,而且把cpu資源壓榨到最多。對于一個IO密集型操作來說,采用異步方式可以大大提高系統吞吐量。異步不需要等待被調用方執行完成就可以執行其他的邏輯,在被調用方執行完畢之后通過通知回調的方式反饋給調用方。
“異步本質上是一種編程思想,一種編程模型。他提高的是系統整體的吞吐量,但是請求的響應時間對比同步方式來說會略微加大。
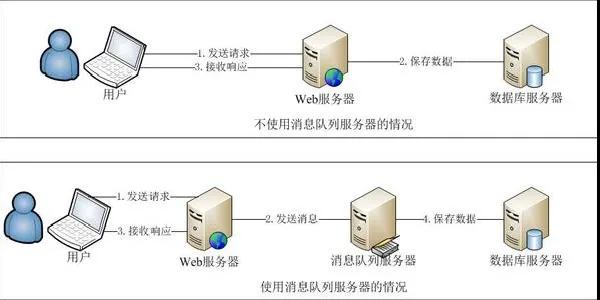
像平時用的最多的消息隊列,在模型上也屬于異步編程模型。調用方會把消息丟到隊列中,然后直接返回去執行其他業務,被調用方接收到消息然后進行處理,然后根據具體的業務看是否需要給予結果回復。有不少秒殺系統會采用消息隊列進行流量削峰,這是異步帶來的優勢之一。
image
在這里我需要多說一句:異步并不是沒有代價,在多數情況下,采用異步會比同步方式編寫更多的代碼,而且查找bug會花費更多的時間。但是對于一個高并發系統來說,異步帶來的益處還是值得的,前提是你正確應用了異步。
本文轉載自微信公眾號「架構師修行之路」,可以通過以下二維碼關注。轉載本文請聯系架構師修行之路公眾號。
















