基于Redis配置Celery
作為一個分布式異步計算框架,Celery雖然常用于Web框架中,但也可以單獨使用。 雖然常規搭配的消息隊列是RabbitMQ,但是由于某些情況下系統已經包含了Redis,那就可以復用。

以下撇開Web框架,介紹基于Redis配置Celery任務的方法。
- pip install celery[redis]
項目結構
- $ tree your_project
- your_project
- ├── __init__.py
- ├── main.py
- ├── celery.py
- └── tasks.py
- 0 directories, 4 files
其中,main.py是觸發Task的業務代碼。當然,文件名可以隨意改。celery.py是Celery的app定義的位置,tasks.py是Task定義的位置,文件名不建議修改。
配置Celery
在celery.py中寫入如下代碼:
- from celery import Celery
- from .settings import REDIS_URL
- APP = Celery(
- main=__package__,
- broker=REDIS_URL,
- backend=REDIS_URL,
- include=[f'{__package__}.tasks'],
- )
- APP.conf.update(task_track_started=True)
其中,REDIS_URL從同一的配置settings.py中引入, 形式大概是redis://localhost:6379/0。這里既用Redis來當broker,又用來當backend。即,既當消息隊列,又當結果反饋的數據庫(默認僅保存1天)。
在include=,需要填一個下游worker的包名列表。這里選擇了同一個包的tasks.py文件。
額外設置的task_track_started,是命令Worker反饋STARTED狀態。默認情況下,是無法知道任務什么時候開始執行的。
編寫任務并調用
在tasks.py文件中,添加異步任務的實現。
- from .celery import APP
- @APP.task
- def do_sth():
- pass
在需要發起任務的地方,用.apply_async可以觸發異步調用。即,實際只是向消息隊列發送消息,真正的執行操作在遠程。
- from celery.result import AsyncResult
- from .tasks imprt do_sth
- result = do_sth.apply_async()
- assert isinstance(result, AsyncResult)
運行Worker:
- celery -A your_project worker
運行原理
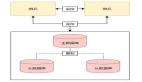
一次Task從觸發到完成,序列圖如下:
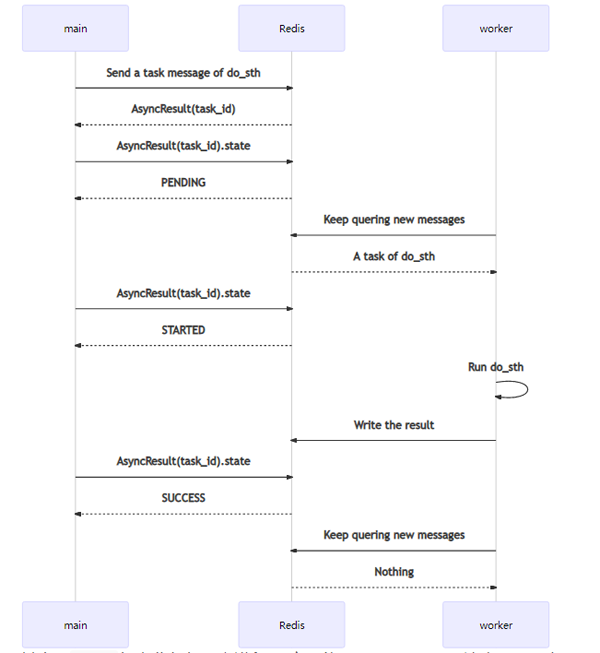
其中,main代表業務代碼主進程。它可能是Django、Flask這類Web服務,也可能是一個其它類型的進程。worker就是指Celery的Worker。
main發送消息后,會得到一個AsyncResult,其中包含task_id。僅通過task_id,也可以自己構造一個AsyncResult,查詢相關信息。其中,代表運行過程的,主要是state。
worker會持續保持對Redis(或其它消息隊列,如RabbitMQ)的關注,查詢新的消息。如果獲得新消息,將其消費后,開始運行do_sth。運行完成會把返回值對應的結果,以及一些運行信息,回寫到Redis(或其它backend,如Django數據庫等)上。在系統的任何地方,通過對應的AsyncResult(task_id)就可以查詢到結果。
Celery Task的狀態
以下是狀態圖:
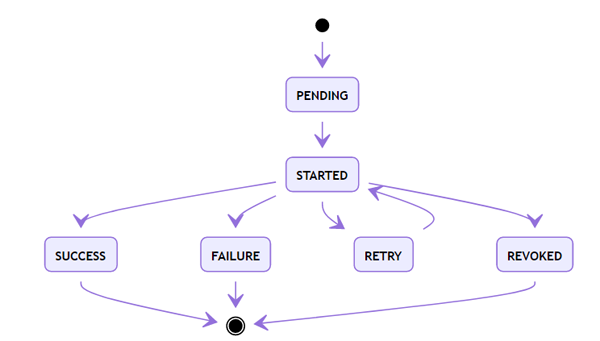
其中,除SUCCESS外,還有失敗(FAILURE)、取消(REVOKED)兩個結束狀態。而RETRY則是在設置了重試機制后,進入的臨時等待狀態。
另外,如果保存在Redis的結果信息被清理(默認僅保存1天),那么任務狀態又會變成PENDING。這在設計上是個巨大的問題,使用時要做對應容錯。
常見控制操作
- result = AsyncResult(task_id)
- # 阻塞等待返回
- result.wait()
- # 取消任務
- result.revoke()
- # 刪除任務記錄
- result.forget()
有時,在業務主進程中需要等待異步運行的結果,這時需要使用wait。如果要取消一個排隊中、或已執行的任務,則可以使用revoke。即使任務已經執行完成,也可以使用revoke,但不會有任何變化。如果需要提前刪除任務記錄,可以使用forget。