譯者 | 朱先忠
審校 | 重樓
本文將通過一個最小但功能強大的實例教程,引導你進入異步機器學習推理開發領域。
簡介
大多數機器學習服務教程都專注于實時同步服務的介紹,這允許對預測請求做出即時響應。然而,這種方法可能難以應對流量激增,對于長時間運行的任務來說并不理想。因此,類似于這樣的任務還需要更強大的機器來快速響應;否則,一旦客戶端或服務器發生故障,預測結果通常會丟失。
在本文中,我們將演示如何使用分布式任務調度框架Celery和開源分布式鍵值對數據庫Redis作為異步工作線程來運行機器學習模型。試驗中,我們將使用微軟開源的統一視覺基礎模型Florence 2,這是一種以其令人印象深刻的性能而聞名的視覺語言模型。本教程將提供一個最小但功能強大的示例;當然,您可以根據自己的實戰場景進一步進行調整和擴展。
您可以在下面鏈接處查看該應用程序的演示:
https://coral-app-qdy8z.ondigitalocean.app/
總體來看,我們提供的解決方案的核心基于Celery框架,這是一個支持我們實現客戶端/工作線程邏輯的Python庫。它允許我們將計算工作分配給許多工作線程,從而提高機器學習推理應用場景對高負載和不可預測負載的可擴展性。
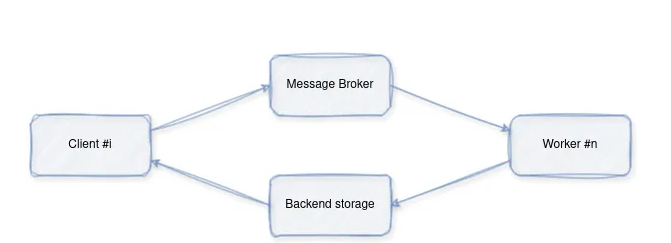
總體運行流程如下:
- 客戶端向代理管理的隊列(在我們的示例中為Redis)提交一個帶有一些參數的任務。
- 由一個(或多個工作線程)持續監控隊列,并在任務到來時接收任務。然后,它執行它們并將結果保存在后端存儲中。
- 客戶端可以通過輪詢后端或訂閱任務的通道,使用其id獲取任務的結果。
簡化實例
讓我們從一個簡化的例子開始:
圖片由作者本人提供
首先,通過如下命令運行Redis:
Docker run -p 6379:6379 redis下面給出的是工作線程代碼:
from celery import Celery
#配置Celery以使用Redis作為代理和后端
app = Celery(
"tasks", broker="redis://localhost:6379/0", backend="redis://localhost:6379/0"
)
# 定義一個簡單的任務
@app.task
def add(x, y):
return x + y
if __name__ == "__main__":
app.worker_main(["worker", "--loglevel=info"])相應的客戶端代碼如下:
from celery import Celery
app = Celery("tasks", broker="redis://localhost:6379/0", backend="redis://localhost:6379/0")
print(f"{app.control.inspect().active()=}")
task_name = "tasks.add"
add = app.signature(task_name)
print("Gotten Task")
#向工作線程發送一個任務
result = add.delay(4, 6)
print("Waiting for Task")
result.wait()
#得到結果
print(f"Result: {result.result}")運行上面代碼,將給出了我們期望的結果:“Result: 10”。
實戰案例
下面,我們繼續討論構建一個真正的基于Florence 2模型服務的實用型案例。
具體地說,我們將構建一個多容器圖像字幕應用程序,該應用程序使用Redis進行任務排隊,使用Celery進行任務分發,并使用本地卷或谷歌云存儲實現潛在的圖像存儲。該應用程序的設計包含幾個核心組件:模型推理、任務分配、客戶端交互和文件存儲。
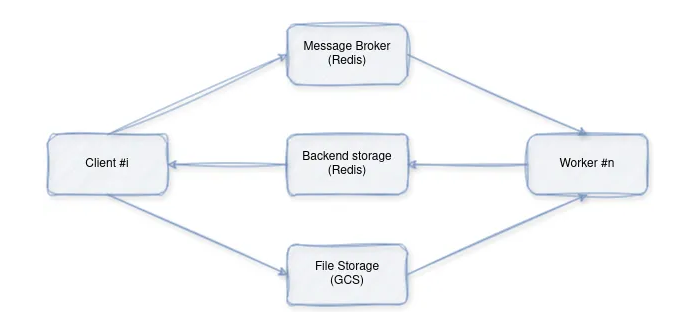
架構概述
圖片由作者本人提供
各組件分工如下:
- 客戶端(Client):通過將圖像字幕請求發送給工作線程(通過代理)來發起圖像字幕請求。
- 工作線程(Worker):接收請求,下載圖像,使用預訓練的模型進行推理,并返回結果。
- 分布式鍵值對數據庫Redis:充當消息代理,促進客戶端和工作線程之間的通信。
- 文件存儲:圖像文件的臨時存儲。
接下來,我們進行各組件功能的更具體的剖析。
1.模型推理(Model.py)
首先,實現依賴關系和初始化:
import os
from io import BytesIO
import requests
from google.cloud import storage
from loguru import logger
from modeling_florence2 import Florence2ForConditionalGeneration
from PIL import Image
from processing_florence2 import Florence2Processor
model = Florence2ForConditionalGeneration.from_pretrained(
"microsoft/Florence-2-base-ft"
)
processor = Florence2Processor.from_pretrained("microsoft/Florence-2-base-ft")上面代碼完成的任務如下:
- 導入圖像處理、Web請求、谷歌云存儲交互和日志記錄所需的庫。
- 初始化預訓練的Florence-2模型和處理器以生成圖像字幕。
然后,進行圖像下載(Download_Image):
def download_image(url):
if url.startswith("http://") or url.startswith("https://"):
#處理HTTP/HTTPS URL
#…(從URL下載圖像的代碼)…
elif url.startswith("gs://"):
#處理谷歌云存儲路徑
#…(從GCS下載圖像的代碼)。
else:
#處理本地文件路徑
# ... (code to open image from local path) ...歸納一下的話,上面代碼完成的任務如下:
- 從提供的URL下載圖像。
- 支持HTTP/HTTPS URL、谷歌云存儲路徑(gs://)和本地文件路徑。
接下來,執行推理(run_Inference):
def run_inference(url, task_prompt):
# …(使用donan_image函數下載圖像的代碼)。
try:
# …(打開和處理圖像的代碼)。
inputs = processor(text=task_prompt, images=image, return_tensors="pt")
except ValueError:
#錯誤處理
# …(使用模型生成字幕的代碼)。
generated_ids = model.generate(
input_ids=inputs["input_ids"],
pixel_values=inputs["pixel_values"],
#……(模型生成參數)。
)
#…(解碼生成的字幕的代碼)。
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]
#…(后處理生成的字幕的代碼)。
parsed_answer = processor.post_process_generation(
generated_text, task=task_prompt, image_size=(image.width, image.height)
)
return parsed_answer上面代碼實現了編排圖像字幕的過程,具體實現如下:
- 使用download_image下載圖像。
- 為模型準備圖像和任務提示。
- 使用加載的Florence-2模型生成字幕。
- 對生成的字幕進行解碼和后處理。
- 返回最終字幕。
2.任務分配(worker.py)
首先,進行Celery設置:
import os
from celery import Celery
# ... 其他導入...
#從環境變量中獲取Redis URL或使用默認值
REDIS_URL = os.getenv("REDIS_URL", "redis://localhost:6379/0")
# 將Celery配置為使用Redis,作為代理和后端
app = Celery("tasks", broker=REDIS_URL, backend=REDIS_URL)
# ... (Celery配置) ...這段代碼完成的任務是:將Celery設置為使用Redis作為任務分發的消息代理。
接下來,定義任務(inference_task):
@app.task(bind=True, max_retries=3)
def inference_task(self, url, task_prompt):
#……(日志記錄和錯誤處理)。
return run_inference(url, task_prompt)
上面代碼具體實現了:
l 定義將由Celery工作線程執行的推理任務。
l 此任務從model.py調用run_inference函數。
最后,執行工作線程:
if __name__ == "__main__":
app.worker_main(["worker", "--loglevel=info", "--pool=solo"])啟動一個監聽并執行任務的Celery工作線程。
3.客戶端交互(Client.py)
首先,實現Celery連接:
import os
from celery import Celery
#從環境變量中獲取Redis URL或使用默認值
REDIS_URL = os.getenv("REDIS_URL", "redis://localhost:6379/0")
#將Celery配置為使用Redis作為代理和后端
app = Celery("tasks", broker=REDIS_URL, backend=REDIS_URL)使用Redis作為消息代理建立與Celery的連接。
接下來,進行任務提交(send_inference_Task):
def send_inference_task(url, task_prompt):
task = inference_task.delay(url, task_prompt)
print(f"Task sent with ID: {task.id}")
# 等待結果
result = task.get(timeout=120)
return result上述代碼完成了兩項任務:
- 向Celery工作線程發送圖像字幕任務(推理任務)。
- 等待工作線程完成任務并檢索結果。
再接下來,實現Docker集成(Docker compose.yml)。
這一步主要是使用Docker Compose定義多容器設置:
- redis:運行redis服務器進行消息代理。
- model:構建和部署模型推理工作線程。
- app:構建和部署客戶端應用程序。
此處花朵圖片由RoonZ nl在Unsplash(https://unsplash.com/photos/yellow-and-blue-petaled-flower-vjDbHCjHlEY?utm_cnotallow=creditCopyText&utm_medium=referral&utm_source=unsplash)上提供
- flower:運行一個基于Web的Celery任務監控工具。
圖片由作者本人提供
其實,您可以使用以下一句命令運行上面完整的棧操作:
docker-compose up小結
至此,整個任務完成!歸納一下,我們剛剛探索了使用Celery、Redis和Florence 2構建異步機器學習推理系統的全過程。具體地說,本文演示了如何有效地使用Celery進行任務分配,使用Redis進行消息代理,使用Florence 2模型進行圖像字幕處理。通過采用異步工作流方案,您可以處理大量請求,提高性能,并增強ML推理應用程序的整體彈性。最后,我們提供的Docker Compose設置允許您使用單個命令來自行運行整個系統。
準備好下一步操作了嗎?將本文介紹的這種架構部署到云端可能會遇到一系列挑戰。
項目源碼地址:https://github.com/CVxTz/celery_ml_deploy
項目演示地址: https://coral-app-qdy8z.ondigitalocean.app/
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Asynchronous Machine Learning Inference with Celery, Redis, and Florence 2,作者:Youness Mansar
鏈接:https://towardsdatascience.com/asynchronous-machine-learning-inference-with-celery-redis-and-florence-2-be18ebc0fbab。