報表自動化就是連接數據庫?錯,它打開了數據倉庫的大門
我認為的如何逐步做到商業智能,通過報表自動化、數據圖表化、數據可視化、數據挖掘四步走的方式,逐步的讓數據產生價值。
我們主要講報表自動化,但在這之前我們需要有“大量的數據”支持,多次提到“大量的數據”,這些數據就是指我們各種產品在使用、運行過程中存到數據庫的數據,當然也包括日志中的數據,這些數據在我們產品運行過程中生成且同時為產品運行提供服務。
FineReport做的報表
如果是數據庫中的數據,那么還可能出現數據分別存儲在各種庫、表、文件中,他們以最初業務功能的需要進行著“合理”或者早已被多人“吐糟”的方式分布著。
那么,我們報表自動化的實踐就是先要讓一個服務連接上所有的產品數據庫,然后構建出所有表的 entity 用我們熟悉的 JAVA、PHP 等語言完成么?實際上并不是這樣的,在這之前,我們首先要先建立“數據倉庫”。
數據倉庫的設計
數據倉庫的設計方式有很多種,這里主要講一種設計方式 DB-ODS-DW-DM 分層設計,這里引入了四個單詞,由他們構成的數據流如下
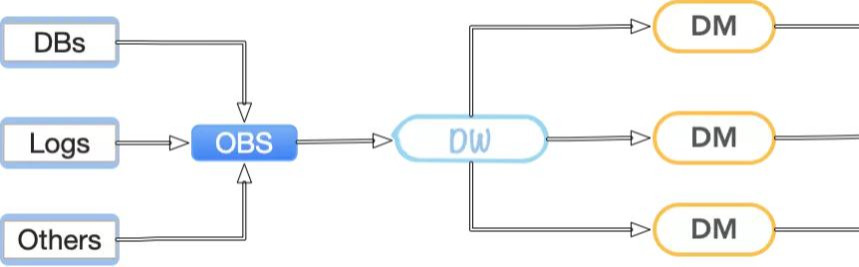
圖中箭頭表示數據的流向,可以看到我們的數據大致是這樣流動的:
- 五湖四海:無論是數據庫里的、日志里的、第三方服務、數據提供方的等等,最初的數據便不再五湖四海
- 海納百川:來自五湖四海的數據匯聚于一點,OBS 承擔著至關重要的一步 -- 收集
- 類聚群分:雜亂無章的堆積終究不便于使用,無論怎樣開門看到了混亂的現場要先收拾一下,分門別類的 -- 整理
- 術業專攻:龐大的倉庫涵蓋了太多的信息,就算我們整理好了也沒有能力自我消化,需要找到專人專才去處理對應的信息,進行加工 -- 分析
- 天道酬勤:經過復雜的收集、整理、分析后,我們終于讓東西產生了價值,可以開始對外輸出了
DB(Data Base)
這里實際上是指我們的產品 / 業務系統的數據層,這里要用層的概念了,他們可能由多個庫構成,這個數據層提供了業務正常運行的支持,如果要做數據倉庫,DB 數據層還需要提供,在一定時間里被 ETL 工具批量拉取數據到 ODS 的支持。
注意這里數據拷貝不是人工拷貝,需要使用 ETL(Extract-Transform-Load)工具,ETL 指數據的抽取、轉換、加載,可以通過 ETL 工具配置數據從源到目標的操作行為并定時觸發,這個后文有所介紹。
OBS(Operational Data Store)
ODS(Operational Data Store),操作性數據,是作為數據庫 DB 到數據倉庫 DW 的一個過渡層 / 中間層。
實際上在做報表自動化時并不是直接從產品庫獲取數據的,是需要先構建數據倉庫的,而數據倉庫的第一步就是先將所有的產品庫的各種數據都 copy 到一個“中間層 OBS”,后續所有的數據倉庫都通過“中間層 OBS”獲取數據,這樣的操作有如下好處:
- 隔離性:將業務系統和數據倉庫隔離
- 冗余:這是數據的第一次冗余,當然也可以說是一次備份,通過一個超大的數據庫涵蓋所有的業務數據
- 匯聚:直接打破業務壁壘,將所有數據匯聚在一起,有利于后續數據梳理時的思考,可以讓自己發揮各種想象
- 降低業務系統壓力:這也是冗余的另一個目的,無論是報表自動化還是數據挖掘,都可能產生對數據庫的大量操作,將業務與數據分析分離,讓兩者性能上不受影響,業務數據庫只需要提供一次性的讀取支持即可
這一層是個大系統層,它的主要作用是將多個源庫內容全部同步到本庫中,ETL 工具會四處拉取數據到這里,考慮到單一職責原則,這一層數據結構一般就不會改變了,往往和源庫的各個表的結構保持一致。
同樣的這一層既然是為了匯總數據,那么數據的寫入只能由 ETL 工具進行,這時候就遇到了源數據庫的內容發生了變化怎么辦?每次拷貝來的數據有重復如何處理?
- 如果需要保留每一次拷貝的樣本,那么可以考慮對每個表增加一個時間字段,來標記每次拷貝的內容,通過這個字段的區分可以解決上述兩個問題。
- 如果資源有限,且對于歷史變動并不在乎,只需要當前狀態,那么可以考慮每次拷貝數據前先刪除 OBS 表內信息,再拉取
- 如果資源有限,且數據量很大很大,又希望快速的拷貝,那么可以考慮現在源數據處增加一些獲取條件,將不變的數據過濾掉,比如如果每天更新一次,那么只需要獲取 created time 或者 updated time 是今天的內容,然后 upsert 到 OBS 對應表
DW(Data Warehouse)
這里講的是數據倉庫的數據倉庫層。。。。
數據倉庫,說到了倉庫我們可以想象一下現實中的各種倉庫的樣子,其實數據倉庫也是類似的。
前面 ODS 無條件的接受了所有的信息,也許他唯一能做的就是通過合理的 table 命名來識別出來每個表是從哪個產品庫來的數據了,簡直是一個超級大的混亂空間,而倉庫主要做的就是“規整”。
數據倉庫的建模(“整理”)方法有多種,范式建模法(Third Normal Form,3NF)、維度建模法(Dimensional Modeling)、實體建模法(Entity Modeling)……
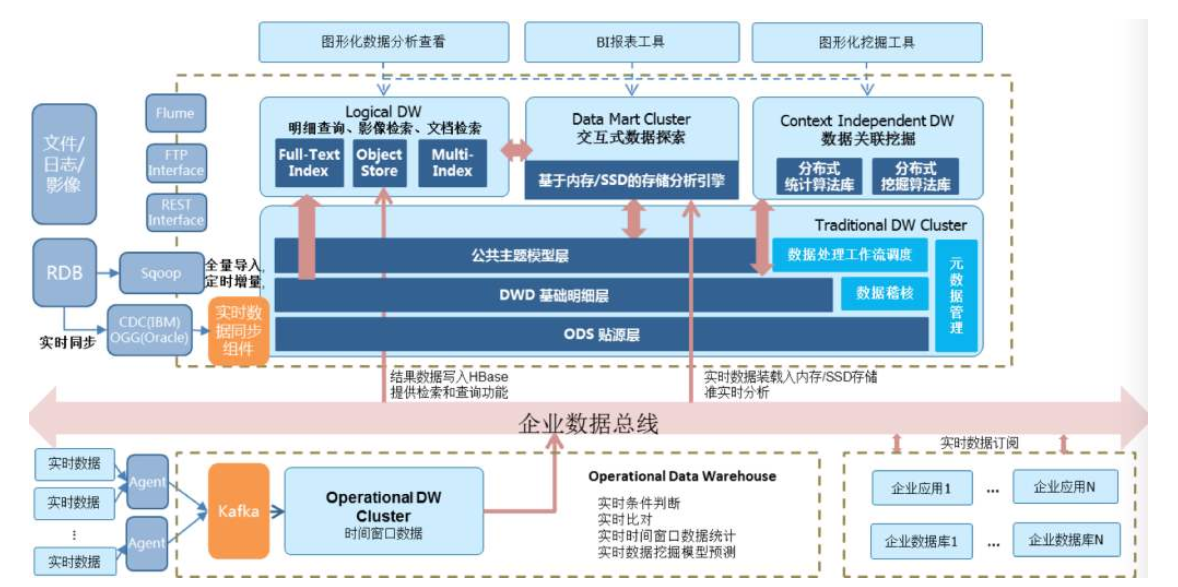
通過各種方式的整理最終的目標是:
- 可讀性:混亂的東西永遠無法知道他們是什么,整理以后可以清晰地理解他們之間的關系。比如維度建模法構建成了事實表和維度表,每一個事實表都是業務主要數據的記錄,其內包含多種事實數據與維度表 id,通過維度表 id 可以進一步的獲得更多的詳細信息,比如時間系列的日期、年月日、星期幾,再比如類型系列的類型中文名、詳細描述信息等等。維度建模的具體情況后文詳細介紹。
- 分類清晰:分分合合,經過 OBS 層將所有數據揉到一起以后,到了 DW 層我們有了一個全新的機會去根據數據之間的關系進行 link,構成一個一個有價值的數據域,當然這個劃分很可能只是通過表名來區分,可能并不會進行分庫。
- 打破業務壁壘:這里的分類主要還是從數據角度出發,可以打破業務已有的壁壘。
- 高質量:對數據重新整理一次,將有用的保留,完全無效已經拋棄的字段可以扔掉。同時高質量也是我們在構建數據倉庫要保證的,我們可以在這一階段刪掉完全無用的字段,但更重要的是詳細的確認有效的信息是否正確、全面。
- 高效率:經過清晰地分類,重新根據數據間關系分類組合,并嚴謹的對待每一條數據,我們具有了一個高質量、清晰可讀、分類明確的數據倉庫,這樣我們就可以更快速的找到我們想要的東西了
注意數據倉庫只是倉庫,存儲了各種東西,它很整潔,但是它并沒有完全的挖掘出存在其內數據的價值,挖掘的步驟就需要下一層了。
DM(Data Mart)
數據集市(Data Mart) ,也叫數據市場,數據集市就是滿足特定的部門或者用戶的需求,按照多維的方式進行存儲,包括定義維度、需要計算的指標、維度的層次等,生成面向決策分析需求的數據立方體。
首先解釋一下前面的圖里為什么有那么多的 DM 數據庫:DM 實際上可以根據業務、部門進行分割了,不同部門 / 業務 / 產品,可以有自己獨有的數據庫。
其次說說這里面裝的是什么:
- DM 庫里往往會裝一些能直接對外輸出的內容,比如最終可以快速的為報表提供查詢服務的數據,還比如各種各樣的指標。
那什么是指標?同比增長率、月度銷售總額、轉換率、平均利潤率、日點擊總數……具體的后面進行更詳細介紹
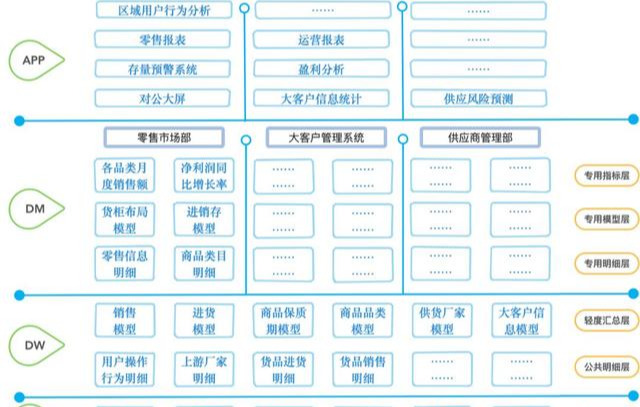
實際上數據倉庫不只是簡單的幾層,比如上圖我“大概”、描述(“假想”)了一個數據倉庫的更復雜一些的模型。
分層的目的,無外乎還是希望各司其職,收集、整理、分析,我們的輸入就是各個數據源拉過來的信息,經過 OBS 囫圇吞棗、DW 建模歸納,最終我們的 DM 層直接對外提供更有價值數據。
本文簡單的介紹了一種數據倉庫的分層設計,主要提及了 OBS 層、DW 層、DM 層,這里過多的說了概念,后面開始拋出細節。比如后面讓我們來聊聊 DW 層建模方法之維度建模。