













云數據建模:為數據倉庫設計數據庫
為數據倉庫或數據集市設計數據庫本質上與為傳統OLTP系統設計數據庫有很大不同。事實上,對于這些純分析系統來說,許多被普遍接受的設計OLTP數據庫的最佳實踐很可能被認為是最糟糕的實踐。

因此,數據建模人員在設計數據倉庫和數據集市時必須掌握一些新技巧。盡管其中包含的一些建議可能與您感到舒適的內容相反,但請保持開放的心態。請記住,宋飛的喬治·科斯坦扎(GeorgeCostanza)并沒有在紐約洋基隊找到理想的工作,直到他接受了與他所有想法相反的做法,如下面的視頻剪輯所示。所以,放棄任何舊的OLTP設計。
云數據建模:良好的數據庫設計意味著“適當的大小”和節約
正如本博客系列的第1部分一樣,云不是涅盤。是的,它提供了本質上無限可擴展的資源。但你必須為使用它們付費。當您為部署到云端的應用程序做出糟糕的數據庫設計選擇時,您的公司將每月為所有不可避免的低效支付費用。靜態過度配置或動態擴展會在一個糟糕的設計上迅速增加每月的云成本。所以,您真的應該熟悉云提供商的規模與成本計算器。
請看下面的圖1。它顯示了一個只有4TB數據的數據倉庫項目的定價,按照今天的標準,這個價格很低。我選擇了“隨需應變”來支持多達64個虛擬CPU和448GB的內存,因為我希望這個數據倉庫能夠完全或至少大部分位于內存中,以實現閃電般的快速訪問。因此,僅在云中運行這一個數據倉庫每年就需要136000美元。如果我能減少CPU和內存需求,我就能顯著降低成本。所以,我不想為了安全而過度提供。我想從第一天起根據一個良好的數據庫設計來調整這個大小,這個數據庫設計不會因為低效的設計而浪費資源。
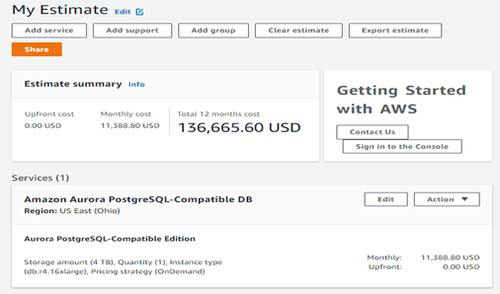
圖1: AWS中4TB數據倉庫的定價
現在,我們將介紹一些數據建模基礎知識,這些基礎知識無論是在本地還是在云中都適用。
要認識和理解的第一件也是最重要的一件事是您現在正在為其設計數據模型的新的、完全不同的目標環境。
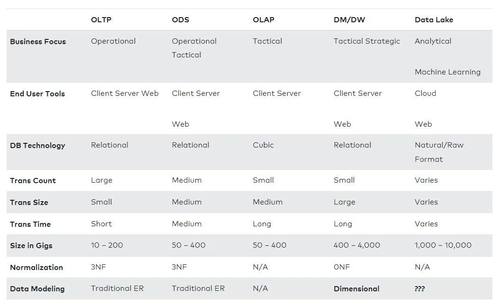
圖2:數據庫設計特征
主要的底層設計原則是,與OLTP系統相比,用戶運行的請求數量相對較少,OLTP系統掃描超大表中的數十萬到數百萬行,并應用聚合函數將數據匯總到少量輸出行中。對于這個目標環境,您不希望像在OLTP系統中那樣規范化數據。事實上,引用電影《年輕的弗蘭肯斯坦》(Young Frankenstein)中的一句話,讓你的大腦工作“abby normal”(艾比正常)會讓你受益匪淺。
星型模式:數據倉庫和數據湖的數據建模和數據庫設計范例
拉爾夫·金博爾(RalphKimball)為此開發了一種數據建模和數據庫設計范式,稱為維度建模和/或星型模式設計。我第一次見到拉爾夫是在20世紀90年代初,當時我參加了他的一次研討會。我當時在埃爾文的老家Logic Works工作,向拉爾夫展示了數據建模工具如何利用他的理想。我在2003年出版了第一本書,展示了我如何使用拉爾夫的技術在Oracle數據庫中創建大型數據倉庫。
星型模式設計實際上非常簡單。只有兩種類型的實體和/或表:
- 維度:較小的非規范化表,其中包含最終用戶查詢的業務描述性列
- 事實:非常大的表,主鍵由相關維度表外鍵列串聯而成,并且具有數字相加的非鍵列,用于最終用戶查詢期間的計算
讓我們以一個簡單的現有OLTP數據模型為例,看看如何將其轉換為星型模式設計。
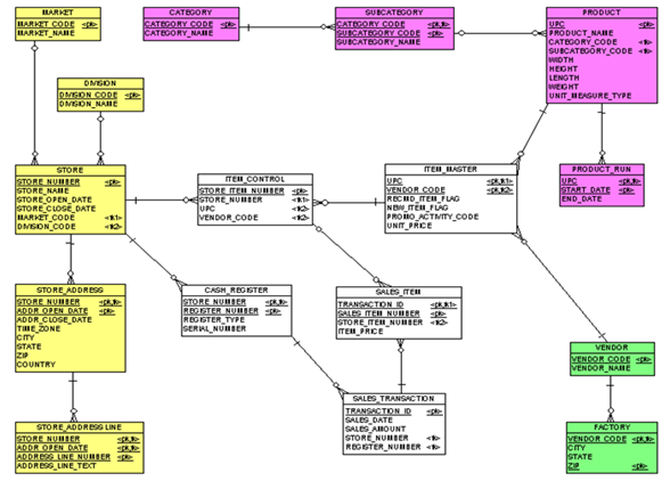
圖3:OLTP銷售點系統的數據模型
這是OLTP便利店銷售點和訂購系統的數據模型。我把它淡化了一點,使之足夠簡單,可以作為一個例子。請注意各種顏色,它們基本上表示此數據模型中類似實體的主題區域。因此,在步驟#1中,我們只需確定所有維度和事實。黃色實體向下展平到store維度,洋紅實體向下展平到product維度。綠色實體根本沒有被納入數據模型,白色實體成為事實。
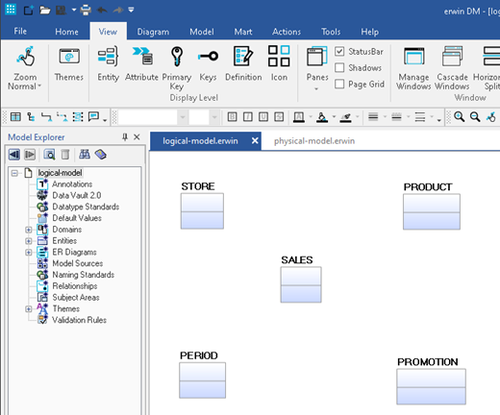
圖4:添加關系之前銷售點系統的邏輯數據模型
那么,這一時期和促銷實體是從哪里來的呢?嗯,在大多數數據倉庫中,您都需要一個時間維度,因為業務用戶希望看到給定日期的數據。所以,你總是會有一些時間維度。促銷實體是新的,因為業務用戶告訴我們,他們希望通過數據倉庫能夠看到的關鍵項目之一是他們的促銷效果如何。
至于第#2步,這很容易——只需添加事實與其所有維度之間的關系。請注意,所有關系都是標識的。看到恒星中心的事實了嗎?因此命名為星型模式。
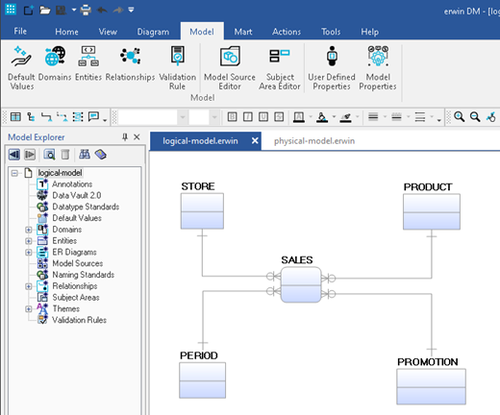
圖5:添加關系后銷售點系統的邏輯數據模型
如果幸運的話,您的數據建模工具將為星形模式設計提供圖表支持。在這里,我們看到歐文提供了這樣一個功能。然而,許多其他數據建模工具不提供此功能。
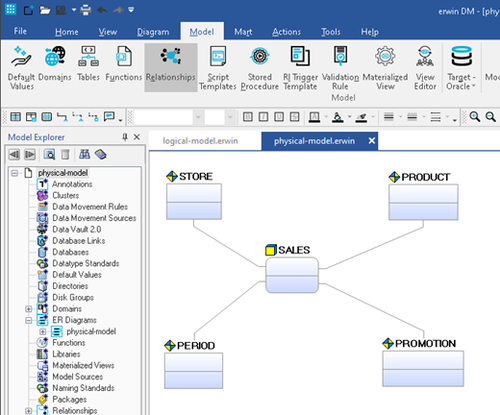
圖6:銷售點系統物理數據模型的星型模式顯示格式
現在只剩下將OLTP數據模型中的所有屬性放置到我們的一個維度或事實中。你最終會得到一個類似這樣的模型。
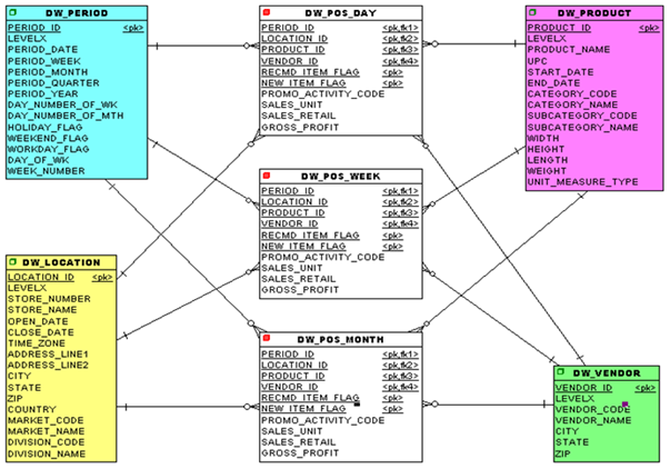
圖7:放置OLTP系統的所有屬性并創建一些新的聚合事實后的星型模式物理數據模型
您可以預掃描和預聚合數據以加快查詢速度
你是否注意到銷售概念被分解為三個獨立的事實?在與業務用戶交談時,我們發現他們通常希望每周或每月報告或分析。因此,我們構建了一些事實,這些事實基本上是基本事實的聚合,因此,我們基本上預掃描和預聚合了一些數據,以加速這些查詢。
創造這樣的綜合事實是很正常的。它們不必像前面的示例中所示的那樣是簡單的基于時間的。它可以是按地區或時區,甚至是按感興趣的產品。例如,本例中的便利店公司有一個德克薩斯總公司和一個啤酒總公司,如圖所示,因為他們的總部位于德克薩斯州,啤酒占所有利潤的30%以上。事實上,“啤酒人”是公司的第三位高管,所以他們應該得到自己的總數。
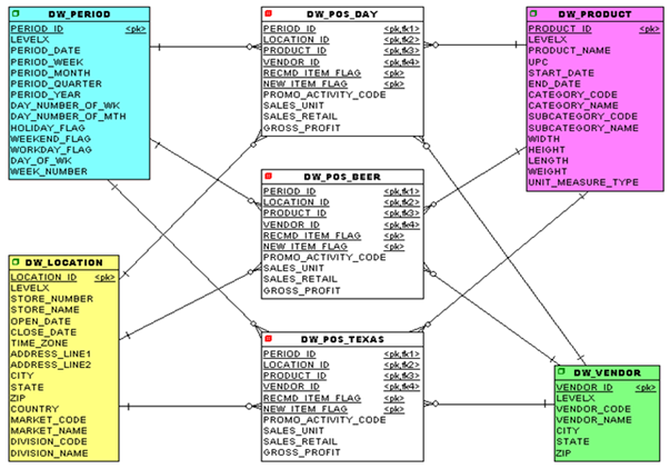
圖8:創建了一些新的、特定于業務且合理的事實后的星型模式物理數據模型
不要阻止優化器看到它是一個星形模式
最后,在星型模式設計中要避免的一件事是snowflaking(這與Snowflake數據庫無關)。許多數據庫優化器識別星型模式,并具有按數量級優化其執行的代碼。但是,您不能向圖片中添加任何使優化器看不到它是星型模式的內容,甚至使其變得復雜。下面是一個雪花添加到我們之前的星型模式模型中的示例。
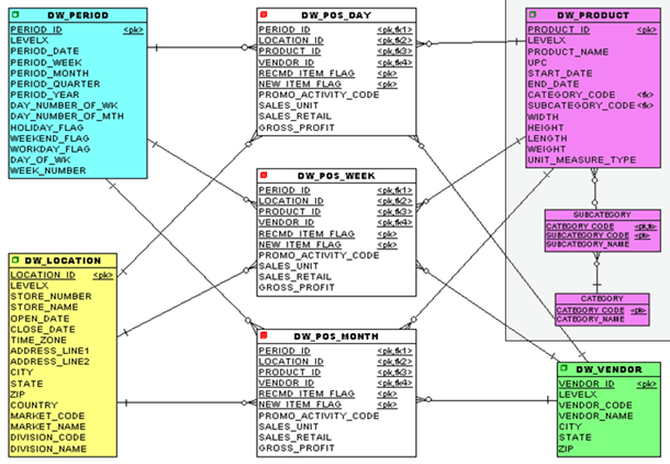
圖9:一個snowflaking的例子使優化器無法看到它是一個星形模式
雖然添加類別和子類別作為規范化工作可能是有意義的,但額外的關系層通常會混淆數據庫優化器,從而導致查詢執行時間大大降低。所以請避免snowflaking。
正如我們在本博客中看到的,數據倉庫的數據建模與OLTP系統的數據建模非常不同。但是,有一些技術可以產生非常成功的數據倉庫,還有一些數據建模工具,如erwin,旨在支持使用此類功能進行建模。



















