













鬼畜配音團隊的福音!AI自動生成適配口型,任何語言都可以
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
同樣的臉,放上不同的聲音,還可以做到如此同步。
當DeepFake口型造假,效果是這樣。
有沒有發(fā)現(xiàn)這幾個人語音語調(diào)完全相同。
閉眼一聽,完全猜不到到底是誰?吳恩達?馬斯克?到底是誰在說話?
而和原有的視頻對比,面部變化也不明顯,效果非常自然。

△用YouTube知名數(shù)碼博主Linus配口型
這是一個名為Wav2Lip的模型——用來生成準確的唇語同步視頻的新方法,來自印度海德拉巴大學的新研究。
任何人物身份,甚至包括卡通人物,任何語音和語言,都可以將口型視頻高精度同步到任何目標語音。
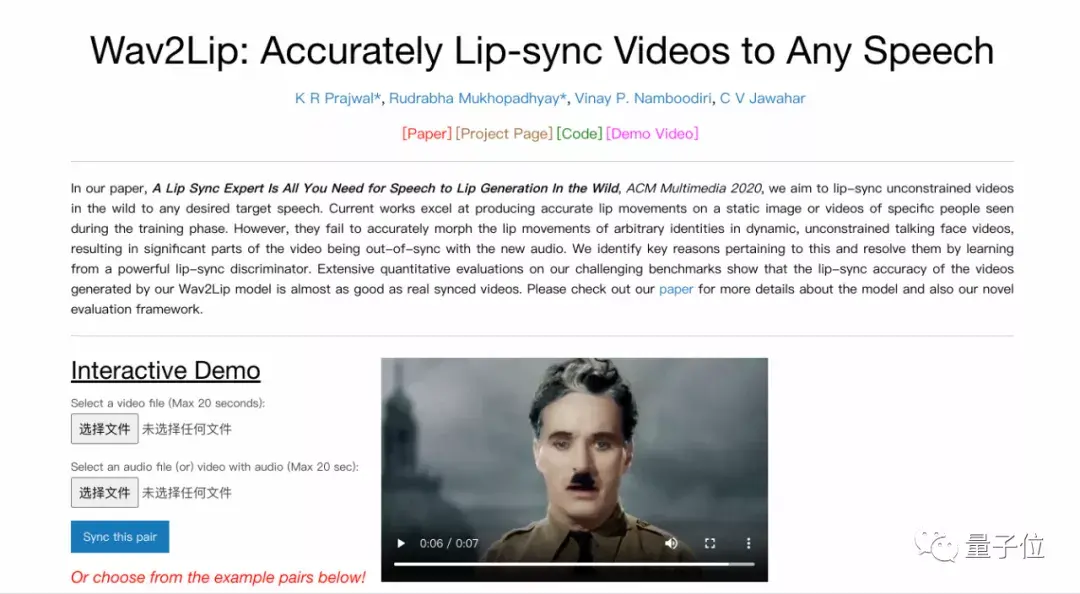
目前該項目已開源,可以去體驗一下Demo版~只需上傳20s的視頻和音頻文件就可以一鍵生成。
這項研究在Reddit上一經(jīng)發(fā)布,21小時內(nèi)就獲得200+的熱度。
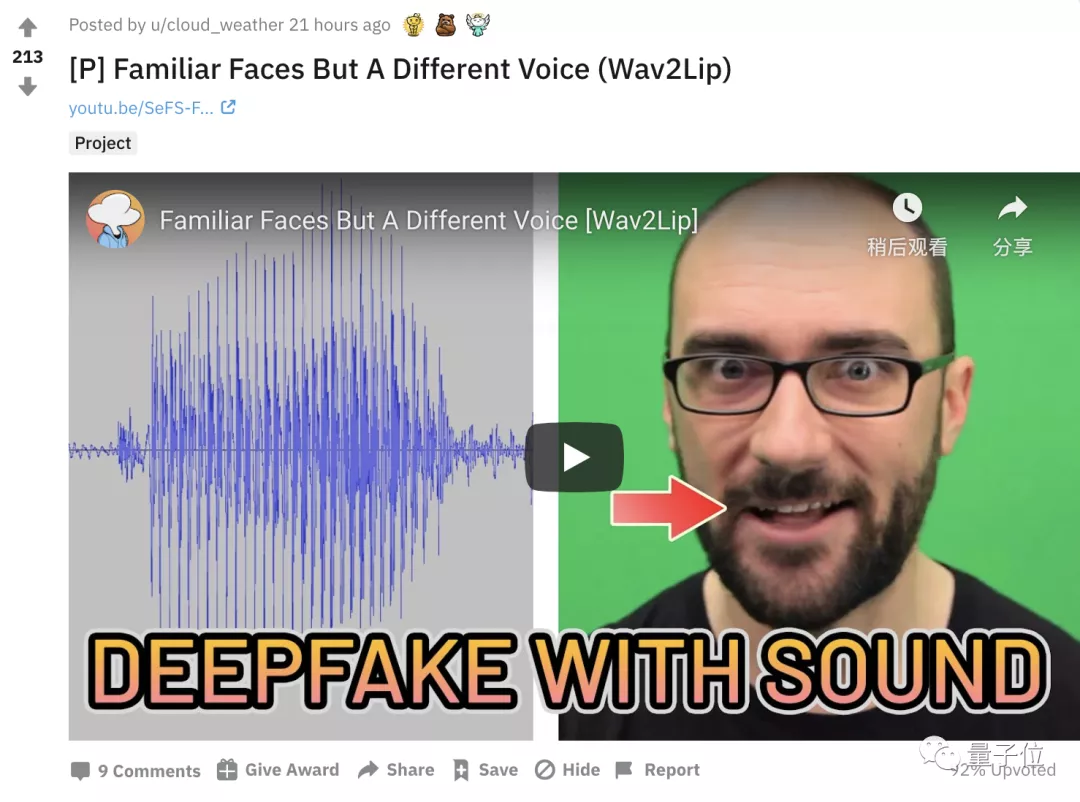
對于這項研究的應用前景,作者說,可以應用在外文在線講座、配音電影、新聞發(fā)布會,讓人物和聲音的融合更加自然,還省去大量的人力物力。
嗯,胥渡吧、淮秀幫這些配音團隊或許可以用的上!
Wav2Lip模型
現(xiàn)有的研究,主要聚焦于在靜態(tài)圖像、或是對視頻中的特定人物生成準確的唇語動作。
但問題在于,無法準確的對動態(tài)圖像,比如正在說話的人物,唇部動作進行變形,從而導致內(nèi)容與新音頻無法做到完全同步。
就像是當你在看音畫不同步的電影時,是不是很難受。
于是,研究人員找到了出現(xiàn)這一問題的關(guān)鍵原因,并通過一個「唇語同步辨別器」來解決。

具體而言,有兩個關(guān)鍵原因,現(xiàn)有研究中所使用的損失函數(shù),即L1重構(gòu)損失和LipGAN中的判別器損失都不能減少錯誤的唇語同步生成。
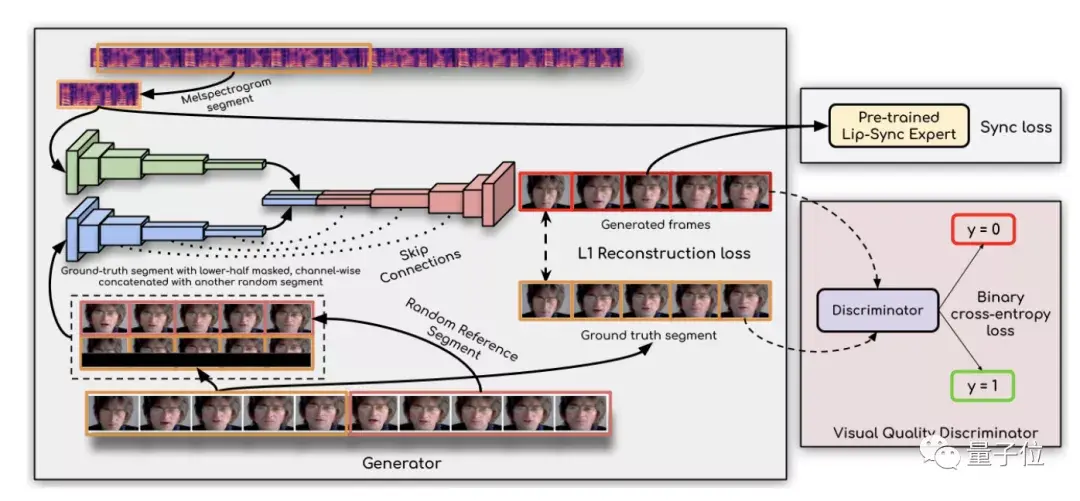
于是,研究人員就直接通過一個預先訓練好的判別器「well-trained lip-sync expert」,來檢測唇語同步的錯誤,這一判別結(jié)果已經(jīng)相當準確。
此外,研究人員還發(fā)現(xiàn),在產(chǎn)生噪聲的面孔上進一步微調(diào),會阻礙判別器測量唇部同步的能力,從而也會影響生成的唇形。
最后,還采用視覺質(zhì)量鑒別器來提高視覺質(zhì)量和同步精度。
舉個例子,黃色和綠色框的是本次提出的模型,紅色框為現(xiàn)有的最佳方法,文字是他們正在說的語句。
可以看到模型產(chǎn)生的唇形比現(xiàn)有的唇形更加準確、自然。
模型訓練結(jié)果
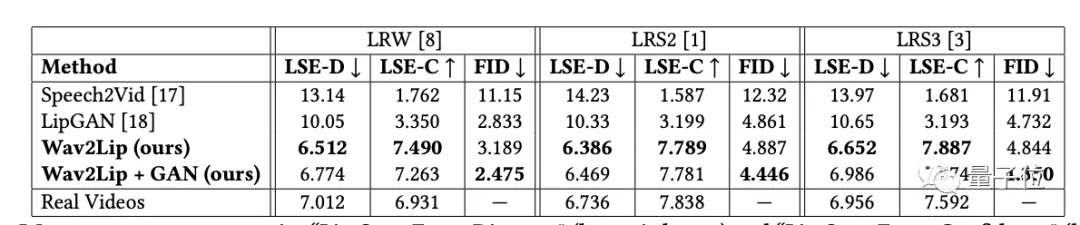
在模型訓練階段,作者提出了兩個新指標, “Lip-Sync Error-Distance”(越低越好)和 “Lip-Sync Error-Confidence”(越高越好),這兩個指標可以測量視頻的中的唇語同步精度。
結(jié)果發(fā)現(xiàn),使用Wav2Lip生成的視頻幾乎和真實的同步視頻一樣好。
需要注意的是,這個模型只在LRS2上的訓練集上進行了訓練,在對其他數(shù)據(jù)集的訓練時需要對代碼進行少量修改。
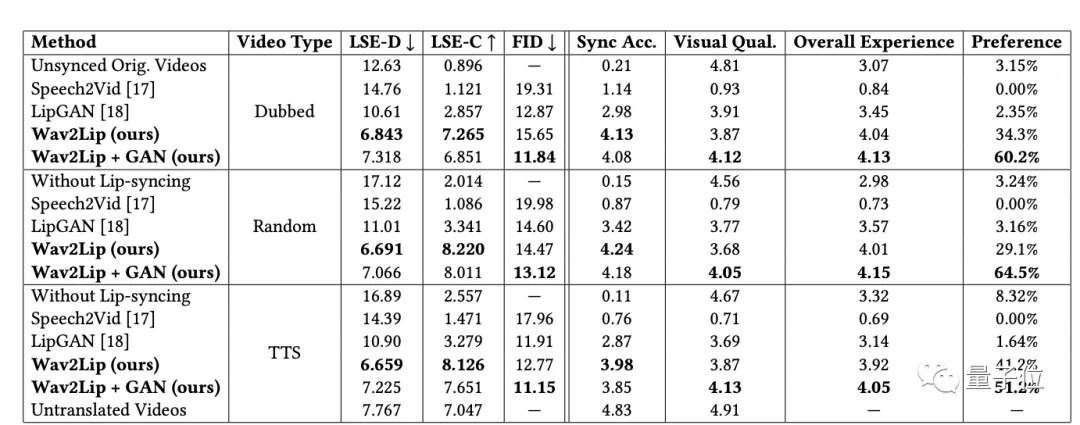
進一步的,還對現(xiàn)實的三種視頻類型進行了評估。
結(jié)果均表明,Wav2Lip模型都能產(chǎn)生高質(zhì)量、準確的唇語同步視頻,不過,在對TTS生成的語音進行唇語同步時,還有改進的空間。
你覺得這項研究如何?
目前,項目已經(jīng)開源,可以自行去體驗一下Demo版哦~
再次提醒:只需上傳20s的視頻和音頻文件,就可以一鍵生成哦!
論文地址:
https://arxiv.org/abs/2008.10010
Demo演示視頻:
https://www.youtube.com/watch?v=SeFS-FhVv3g&feature=youtu.be
GitHub地址:
https://github.com/Rudrabha/Wav2Lip
Demo網(wǎng)址:
https://bhaasha.iiit.ac.in/lipsync/




















