優于人類參考摘要,OpenAI用人類反饋提升了摘要生成質量
隨著語言模型越來越強大,用于特定任務的數據和度量標準越來越成為訓練和評估的瓶頸。例如,摘要模型通常被訓練用來預測人類參考摘要,并使用 ROUGE 進行評估,但是這些度量指標都沒有觸及真正的關注點——摘要質量。
近日,OpenAI 的一項研究表明,人們可以通過訓練模型來優化人類偏好,進而顯著提升摘要質量。具體而言,研究者收集了一個人類摘要比較的大型、高質量數據集,訓練了一種模型來預測人類偏好的摘要,并使用該模型作為獎勵函數通過強化學習來微調摘要策略。

論文鏈接:https://arxiv.org/pdf/2009.01325.pdf
項目地址:https://github.com/openai/summarize-from-feedback
研究者將該方法應用于 Reddit 帖子的摘要生成,結果顯示該研究的模型顯著優于人類參考摘要,以及僅通過監督學習進行微調的更大規模的模型。
研究中的模型還可以遷移至 CNN/DM 新聞文章,在不進行任何特定新聞微調的情況下生成幾乎和人類參考摘要一樣好的結果。
最后,研究者進行了擴展分析,以理解人類反饋數據集和微調模型。該研究確保獎勵模型能夠泛化到新數據集上,并且優化獎勵模型的結果要比根據人類要求優化的 ROUGE 更佳。
該研究的主要貢獻有:
研究表明,在英文摘要生成上,基于人類反饋的訓練顯著優于強大的基準訓練;
人類反饋模型相較于監督模型能夠更好地泛化到新的領域;
對其策略和獎勵模型進行了擴展實驗分析。
接下來詳細解讀 OpenAI 采用的研究方法以及相應的實驗細節和結果。
方法與實驗細節
高階方法
研究者采用的方法適用于批處理設置。從一個初始策略開始,該策略通過對所需數據集(以 Reddit TL;DR 摘要數據集為示例)的監督學習進行微調。整個過程(如下圖 2 所示)由可以迭代重復的三個步驟組成:
基于現有策略中收集樣本,并將比較結果發送給人類;
從人類比較中學習獎勵模型;
針對獎勵模型優化策略。
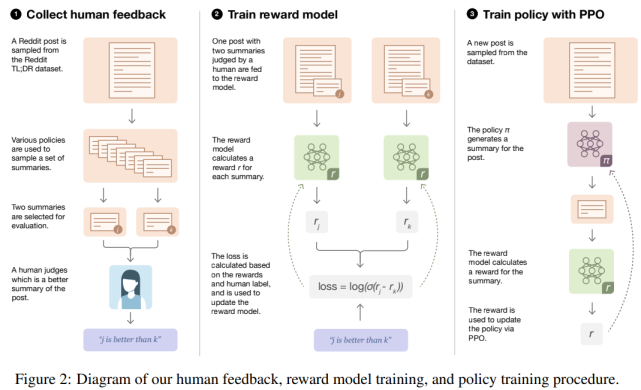
人類反饋、獎勵模型訓練和策略訓練整體流程圖。
數據集和任務
研究者使用 TL;DR 摘要數據集,它包含來自 reddit.com 上涉及各種主題(subreddit)約 300 萬個帖子,以及原始發帖人(TL; DR)撰寫的帖子摘要。
此外,研究者還對該數據集進行了過濾(請參閱附錄 A)以確保數據集質量,包括使用一般人群可以理解的 subreddit 白名單。
研究者將 ground-truth 任務定義為生成一個模型,其中該模型生成長度少于 48 個 token 且盡可能好的摘要。此外,判斷摘要質量的標準是:摘要如何忠實地將原文傳達給一個只能閱讀摘要而不閱讀文章的讀者。
收集人類反饋
先前根據人類反饋對語言模型進行微調的研究表明[66]:我們希望自身模型學習的質量與人類標簽者實際評估的質量之間存在不匹配。這導致了模型生成摘要在標簽者看來質量是好的,但在研究人員看來,質量卻很低。
與 [66] 相比,研究者實現了兩個改進來提高人類數據質量。首先,完全過渡到離線設置,在這里交替發送大量的比較數據給人工標簽者,然后根據累積收集的數據重新訓練模型;其次,與標簽者保持親密關系:給他們詳細的指導,在共享的聊天室中回答他們的問題,并定期對他們的表現提供反饋。
模型
研究者使用的所有模型都是 GPT-3 風格的 Transformer 解碼器,并對具有 13 億(1.3B)和 67 億(6.7B)參數的模型進行人類反饋實驗。與 [12,44] 類似,研究者從預訓練模型開始,以自動回歸預測大型文本語料庫中的下一個 token。
接著,通過監督學習對這些模型進行微調,根據過濾后的 TL; DR 數據集預測摘要(詳細信息參見附錄 B)。使用這些監督模型對初始摘要進行抽樣,以收集比較結果,初始化策略和獎勵模型,并作為評估基準。
最后,為了訓練獎勵模型,研究者從一個監督基準開始,然后添加一個隨機初始化線性頭(linear head)輸出一個標量值。
研究者想要利用訓練得到的獎勵模型,來訓練一個能夠生成基于人類判斷的高質量輸出的策略。
實驗
根據人類反饋生成 Reddit 帖子的摘要
與規模更大的監督策略相比,基于人工反饋訓練的策略更可取。在 TL;DR 數據集上評估人工反饋策略的主要結果如下圖 1 所示:
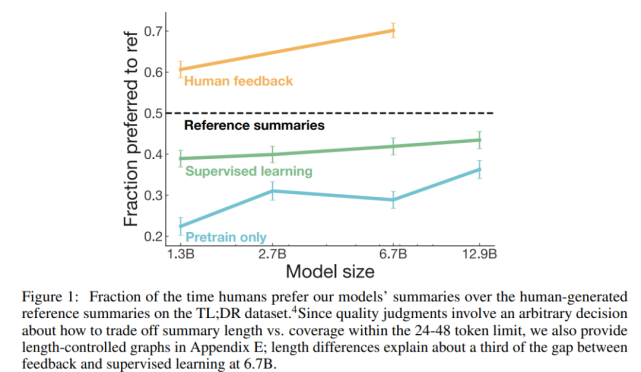
研究者衡量策略質量采用的指標是該數據集中由該策略生成的人們偏好的參考摘要所占的百分比。從圖中可以看到,基于人工反饋訓練的策略顯著優于監督基準策略,并且 1.3B 的人工反饋模型也顯著優于其 10 倍規模的監督模型(兩者相對于參考摘要的原始偏好得分為 61% vs 43%)。
控制摘要長度
在判斷摘要質量時,摘要長度是一個混淆因子(confounding factor)。摘要的目標長度是摘要生成任務的隱式部分,并且根據簡潔性與涵蓋性之間的預期權衡來判斷生成長摘要還是短摘要。
該研究中的模型學會了生成更長的摘要,因此長度在質量改進中起到了很大的作用。
策略如何在基準上實現提升?
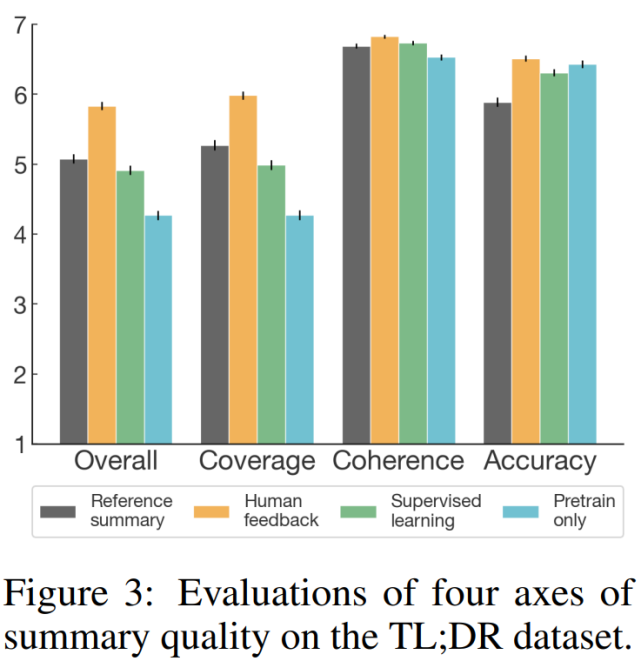
為了更好地了解該模型生成摘要與參考摘要和監督基準摘要三者之間的質量比較,研究者進行了一項補充分析,其中人類標簽員使用 7-point 李克特量表(Likert scale)從四個指標(整體表現、涵蓋性、連貫性和準確性)對摘要質量進行了評估。評估結果如下圖 3 所示,表明從所有指標,特別是涵蓋性來看,人類反饋模型優于監督基準模型。
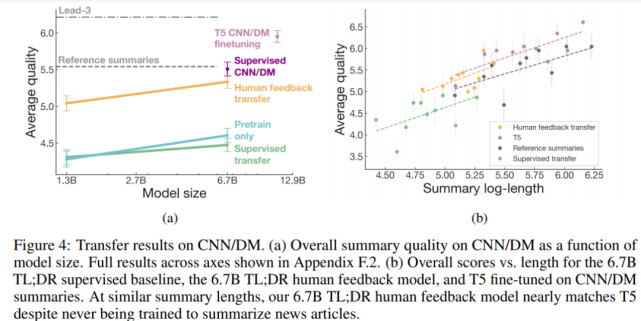
具備生成新聞文章摘要的遷移性
如下圖 4 所示,人類反饋模型還可以在沒有任何進一步訓練的情況下,生成優秀的 CNN/DM 新聞文章摘要。
具體來講,人類反饋模型在 TL;DR 數據集上顯著優于通過監督學習訓練的模型,以及僅在預訓練語料庫上訓練的模型。盡管生成的摘要更短,6.7B 人類反饋模型的效果幾乎相當于在 CNN/DM 參考摘要上進行微調的 6.7B 模型。
理解獎勵模型
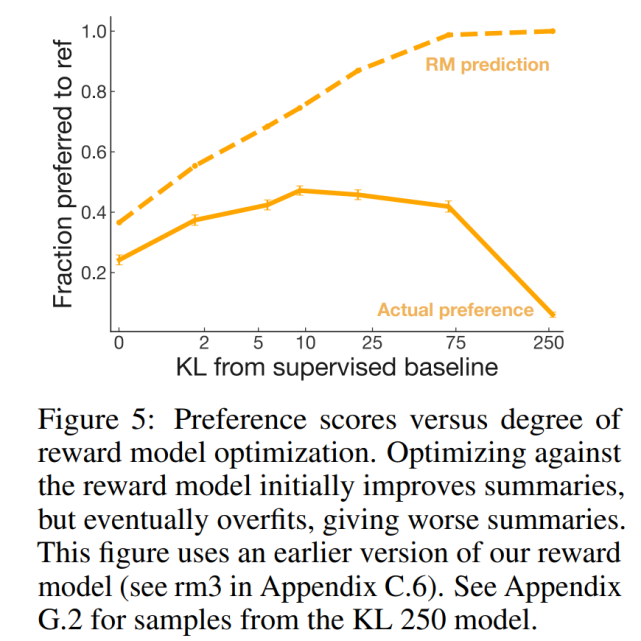
優化獎勵模型
根據該研究的獎勵模型進行優化應該使該研究的策略和人的偏好保持一致。但是獎勵模型并不能完美地代表標簽偏好。雖然該研究希望獎勵模型能夠泛化到訓練期間不可見的摘要,但尚不清楚在獎勵模型開始進行無用的評估之前,獎勵模型能夠優化多少。
為了回答這個問題,研究者創建了一系列針對獎勵模型的早期版本進行優化的策略,這些策略都具有不同程度的優化強度,并要求標簽者對將其樣本與參考摘要進行比較。
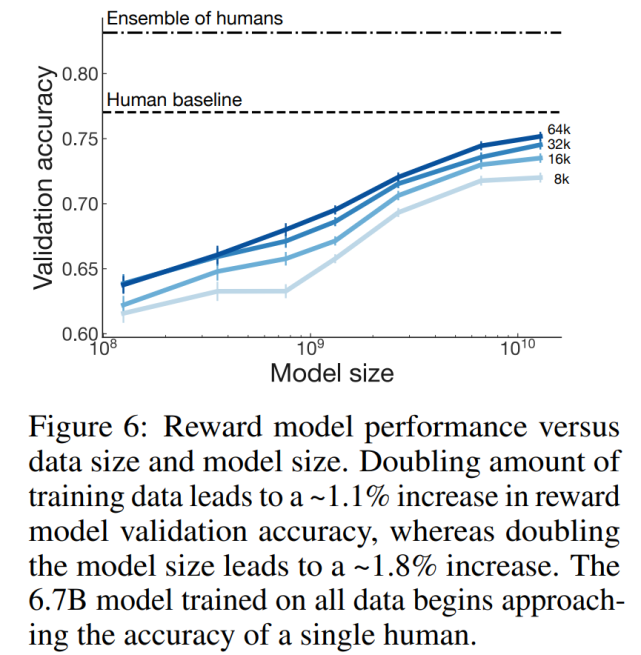
獎勵模型如何隨著模型和數據量的增加進行擴展?
研究者進行了控制變量實驗以確定數據量和模型大小如何影響獎勵模型的性能。研究者訓練了 7 個獎勵模型,從 160M 到 13B 參數,從 8k 到 64k 的人類比較數據。
該研究發現,訓練數據量增加一倍會導致獎勵模型驗證集準確率增加大約 1.1%,而模型大小增加一倍則會導致增加大約 1.8%。具體如下圖 6 所示:
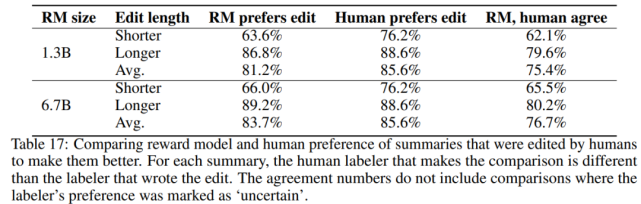
獎勵模型學到了什么?
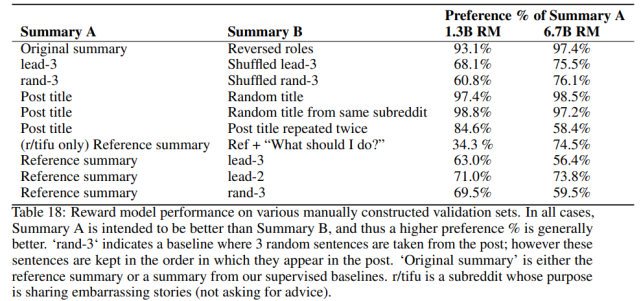
研究者在幾個驗證集中評估了該獎勵模型,在下表 17 中給出了完整結果:
研究者發現該獎勵模型泛化到評估 CNN/DM 摘要,具體如下表 18 所示:
分析用于摘要的自動度量指標
研究者研究了各種自動度量指標如何很好地預測人類的偏好,并將其與 RM 進行比較。具體來講,研究者在基線監督模型下檢查了 ROUGE、摘要長度、從帖子中復制的數量以及對數概率。
如下圖 7 所示,使用簡單的優化方案優化 ROGUE 并不能持續提高質量,與針對獎勵模型的優化相比,針對 ROGUE 的優化不僅可以更快達到峰值,而且質量比率也大大降低。