














隨著互聯網上各種 UGC 越來越多,各種原創性的長文本內容也不斷地涌現出來。例如,在人工智能領域的三大頂會之一的 ICML,許多論文的長度都達到了二三十頁。因此,如何快速的從長文本中提取出有用的信息,成為困擾許多包括科研人員在內的互聯網網民的難題。
在 2012 年結束的人工智能領域頂會 AAAI 2012 上,來自中國浙江大學的研究團隊,發表了一篇題為 Document Summarization Based on Data Reconstruction 的論文。該篇論文提出了 DSDR 算法,描述了如何利用貪心算法進行文本摘要提取的方法。論文下載地址在這里:Document Summarization Based on Data Reconstruction (nju.edu.cn)。下面我們介紹一下他們的方法。
所謂的文本自動摘要問題,本質上就是從原始的長文本中抽取一個文本的子集合,使得利用這個子集合的線性組合能盡可能的恢復出原始文本。我們按照如下方式定義文本自動摘要問題:
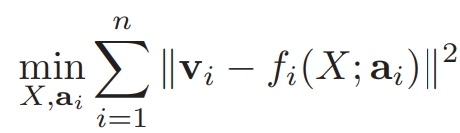
其中, f 是線性組合摘要句子之后的轉換函數。X 是摘要生成的句子,a 是線性組合的系數,而 v 是原始文本,也就是輸入數據。
首先,f 可以是線性組合,也就是:
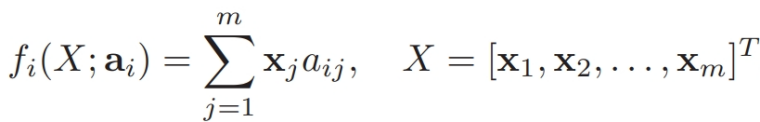
因此,文本自動摘要問題轉換成為了下述問題:
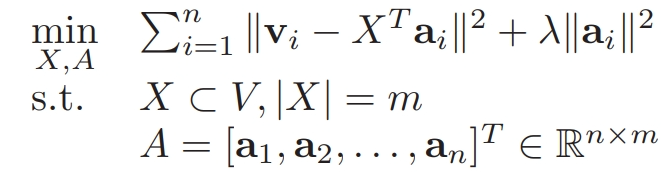
上述損失函數公式,等價于下面的公式:
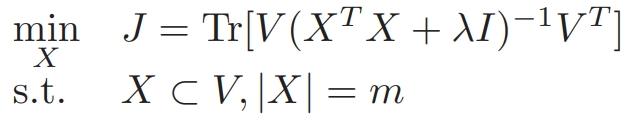
利用貪心算法,我們設計了如下損失函數:
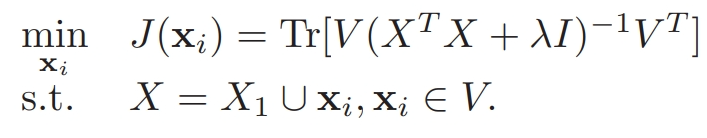
整個算法的偽代碼流程如下所示:

在上面介紹的算法中,線性組合的系數 a 有可能是負數,為了保證 a 非負,我們重構了算法的損失函數:
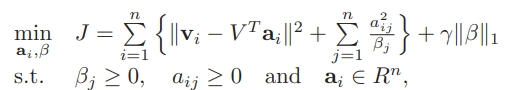
經過重新設計之后,算法的偽代碼如下:

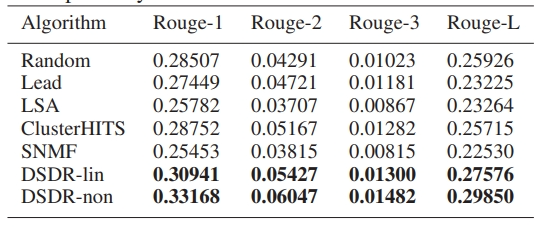
通過對比實驗,我們發現新設計的算法,取得了優異的實驗結果:
文本自動摘要,對于閱讀長篇幅的文本,比如博士畢業論文、咨詢報告、審計報告等內容,非常有幫助。對于趕時間的當代人來說,文本自動摘要無疑是隨身辦公的文書利器。希望通過本文,廣大的互聯網從業者能夠有所收獲。
作者介紹
汪昊,前 Funplus 人工智能實驗室負責人。曾在 ThoughtWorks, 豆瓣,百度,新浪,網易等公司有超過 13 年的技術研發和技術高管經驗。先后在科技公司上線過 10 余款成功的商業產品。擔任過創業公司的 CTO和技術副總裁。精通數據挖掘、計算機圖形學和數字博物館領域的技術、技術管理和技術變現等內容。在國際學術會議和期刊如 IEEE TVCG 和 IEEE / ACM ASONAM 上發表論文 39 篇,獲得最佳論文獎 1 次(IEEE SMI 2008)和最佳論文報告獎 4 次(ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 / ICSIM 2024)。




















