騰訊面試官用「B+樹」虐哭我了
我們知道當系統要處理的數據量非常龐大的時候,數據不可能全部存放于內存,需要借助磁盤來完成存儲和檢索。在數據庫中支持很多種索引方式,常見有哈希索引、全文索引和B+樹索引。今天將和大家分享使用B+樹作為索引的優缺點。
面試很多互聯網公司,都會問這個問題,也許我們看過太多面經內容,但是基本上答案千篇一律,對于面試官而言也是基本上聽膩了,是多么希望能聽到不一樣的解答,那么今天希望這篇文章可以給你不一樣的答案。

會話1

會話2
就問登哥傲嬌不傲嬌吧,回到正題,今天分享的幾點如下
目錄
1 數據從磁盤讀寫與內存讀寫有哪些不同
我們平時接觸的有機械硬盤和固態硬盤。內存屬于半導體器件,對于內存,我們知道內存地址就可以通過地址拿到數據,也就是內存的隨機訪問特性。訪問速度快但是貴,所以內存空間一般比較小。
對于磁盤,屬于機械器件。每當磁盤訪問數據的時候,都需要等磁盤盤片旋轉到磁頭,才能讀取相應的數據,即使磁盤的轉速很快,但是和內存的隨機訪問相比還是渣渣。所見,如果是隨機讀寫,其性能差距是非常大的。那如果是順序訪問大量數據的時候,磁盤的性能和內存其實差距就不大了,這是為啥?
磁盤的最小讀寫單位是扇區,現在磁盤扇區一般是4k個字節,對于操作系統,一次性會讀取多個扇區,至此操作系統的最小讀取單位就是塊。每當我們從磁盤讀取一個數據,操作系統就會一次性讀取整個塊,那么對于大量的順序讀寫來說,磁盤效率會比隨機讀寫高很多。
假設現在你有個有序數組,全部以塊的方式存放在磁盤中,現在我們通過二分查找的方式查找元素A。首先我們找到中間元素,并從塊中取出,將其從磁盤放入內存中,然后再內存中進行二分查找。在進行下一步的時候,如果查找的元素在其他塊中,我們需要繼續從磁盤讀出到內存中。這樣反反復復的從磁盤到內存,其效率將非常的低。所以我們需要想辦法讓訪問磁盤的次數盡可能的低。
2 數據和索引分離
我們以公安系統為例。系統中的用戶非常多,每個用戶除了姓名,年齡等基本信息外,當然還有一個唯一標識的ID,我們拿到這個ID,就可以知道對應的基本信息。但是每個用戶的基本信息太多不可能全部存放在內存中,因此考慮存儲于磁盤中。
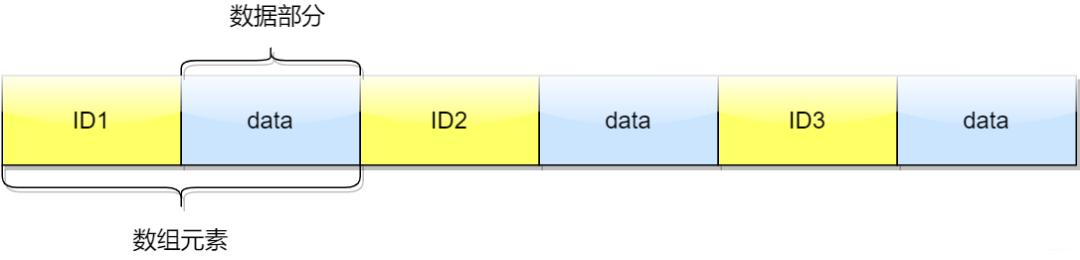
用戶數據
采用有序數組的方式,其中分別存儲用戶ID和用戶信息所在磁盤的位置,這樣我只需要存放兩個元素,直接存放于內存。如下圖所示

有序數組
但是在數據頻繁變化的場景中,有序數組的弊端就出現了。大部分情況還是考慮使用二叉檢索樹或者哈希表的方式。但是哈希表又不支持區間查詢,因此更多的使用二叉檢索樹的方式。如下圖所示

在這里插入圖片描述
如果索引太多,依然不能完全存放于內存中,那我們是不是可以考慮將索引也存放于磁盤中?如何高效的在磁盤中組織索引的結構?這就引入了B+樹
2 B+樹
- 讓節點大小等于塊大小
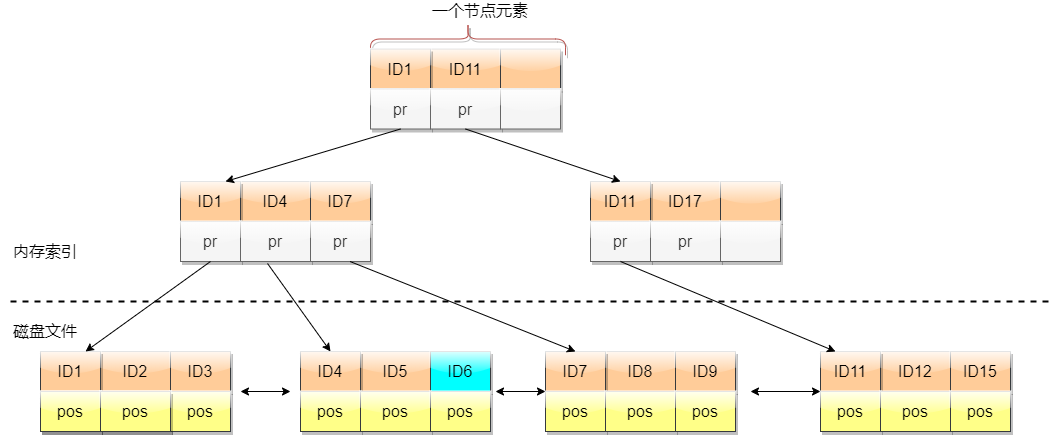
我們知道操作系統在對磁盤進行訪問的時候,通常是按照塊的方式讀取。如果當前你需要讀取的數據只有幾個字節,但是磁盤依然會將整個塊讀出來,這樣子是不是讀寫效率就很低呢。在B+樹中,大佬采用讓一個節點大小等于一個塊的大小,節點中存放的不是一個元素,而是一個有序的數組,這樣充分利用操作系統的套路,使得讀取效率的最大化
- 內部節點與葉子節點
內部節點和葉子節點雖然是一樣的結構,但是其存儲的內容有所區別。內部節點存放key以及維持樹形結構的指針,它并不存放key對應的數據。而葉子節點存放key和對應的數據,不存放維持樹形結構的指針,這樣使得節點空間的利用最大化。
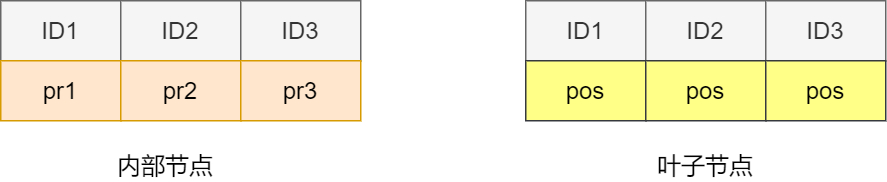
內部節點與葉子節點
- B+樹使用雙向鏈表的方式,具有良好的范圍查詢能力和靈活的調整能力
綜上三點,B+樹是一顆完全平衡的m階多叉樹。

m階多叉樹
3 B+樹的檢索方案
剛才吹了一波B+樹多么的牛逼,到底是怎么檢索的?具體的查找過程是這樣的:我們先確認要尋找的查詢值,位于數組中哪兩個相鄰元素中間,然后我們將第一個元素對應的指針讀出,獲得下一個 block 的位置。讀出下一個 block 的節點數據后,我們再對它進行同樣處理。這樣,B+ 樹會逐層訪問內部節點,直到讀出葉子節點。對于葉子節點中的數組,直接使用二分查找算法,我們就可以判斷查找的元素是否存在。如果存在,我們就可以得到該查詢值對應的存儲數據。如果這個數據是詳細信息的位置指針,那我們還需要再訪問磁盤一次,將詳細信息讀出
B+樹是一個m階的多叉樹,所以B+樹中的一個節點可以存放m個元素的數組,ok,這樣的話,只需要幾層的b+樹就可以索引數據量很大的數了。比如1個2k的節點可以存放200個元素,那么一個4層的B+樹就能存放200^4,即16億個元素。
如果只有四層,意味著我們最多訪問磁盤4次,假設目前每個節點為2k,那么第一層就一個節點也就2k,第二層節點最多200個元素,一共就是0.8M。第三層200^2,也就是40000個節點,一共80M。對于當前的計算機而言,我們完全可以將前面三層存放于內存中,只需要將第四層存放于磁盤中,這樣我們只需要和磁盤打一次交道就分手,也就是面試想知道的為什么要分為內部節點與葉子節點。
4 B+樹如何進行動態的調整
上面介紹了B+樹的結構和查詢原理,現在我們看看B+樹增加和刪除是怎么個情況
現在我們以三個元素的B+樹 為例,假設目前我們要插入ID為6=5的元素,第一步先查找對應的葉子節點,如果葉子節點沒有滿,直接插入即可
插入元素6
如果我們插入的元素是10?按道理我們應該插入到9后面,但是節點已經滿了,所以我們需要采取其他的方式。方法是將此葉子節點進行分裂,即生成一個新的節點,然后將數據在兩個節點中平分。

節點分裂
很明顯,葉子節點的分裂影響到了父節點,如果父節點也是滿的,也要進行分裂

節點分裂
總結
從大問題拆分為小問題并逐個解決是我們在生活學習重要的本領,比較復雜的B+樹其實也就是基本的數據結構(數組,鏈表,樹)組成,其檢索過程實際上就是二分查找,所以如果B+樹完全載入內存,它的檢索效率和有序數組/二叉檢索樹差不多,但是卻更加復雜。B+樹最大的優點在于它將索引存放在磁盤,讓檢索技術擺脫了內存限制,另外通過將索引和數據分離的方式,將索引的數組大小保持在較小范圍,這樣精簡索引。
本文轉載自微信公眾號「我是程序員小賤」,可以通過以下二維碼關注。轉載本文請聯系我是程序員小賤公眾號。