如何實現一個跨庫連表SQL生成器?
用戶只需在前端簡單配置下指標,系統即可自動生成大寬表,讓用戶查詢到他所需要的實時數據,數據源支持跨庫并支持多種目標介質。這樣的數據全局實時可視化如何實現?本文從需求分析開始,分享自動生成SQL功能開發中運用到的設計模式和數據結構算法設計。
一 概述
ADC(Alibaba DChain Data Converger)項目的主要目的是做一套工具,用戶在前端簡單配置下指標后,就能在系統自動生成的大寬表里面查詢到他所需要的實時數據,數據源支持跨庫并支持多種目標介質。說的更高層次一點, 數據的全局實時可視化這個事情本身就是解決供應鏈數據“神龍效應”的有效措施(參考施云老師的《供應鏈架構師》[1]一書)。做ADC也是為了這個目標,整個ADC系統架構如下圖所示:
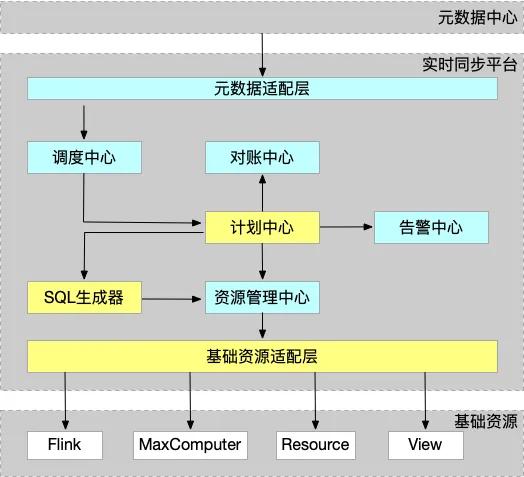
架構解析:
- 初始數據來自于元數據中心。
- 經過元數據適配層后轉換為內部格式數據。
- 調度中心把內部格式的數據傳到計劃中心,計劃中心分析數據需求并建模,通過SQL生成器生成資源和SQL,分別通過告警中心、對賬中心設定監控標準和對賬標準。
- 對賬中心定時對賬,查看數據的對齊情況。
- 告警中心可以針對任務錯誤、延遲高等情況發送報警。
- 資源的生命周期管控在資源管理中心下,view刪除時資源管理中心負責回收資源。
- 基礎資源適配層主要借助集團基礎資源管理能力串聯阿里各類數據服務, 比如阿里云MaxComputer、Flink、阿里云AnalyticDB等。
其中,SQL生成器的上游和下游主要涉及:
- 上游計劃中心
- 配置指標:用戶在前端配置他想看的數據有哪些。
- 生產原始數據:根據用戶輸入得到哪些表作為數據源, 以及它們之間的連接關系。
- 下游Metric適配器
- 把SQL發布到Flink, 根據建表數據建物理表。
本文主要從技術角度介紹下SQL生成器相關的內容。
二 技術實現
在項目實施階段,需要從需求分析、技術方案設計、測試聯調幾個步驟展開工作。本文重點不放在軟件開發流程上, 而是就設計模式選擇和數據結構算法設計做下重點講解。
需求分析
在需求分析階段, 我們明確了自動生成SQL模塊所需要考慮的需求點, 主要包含如下幾點:
- 需要支持多個事實表(流表)、多個維度表連表,其中一個事實表是主表,其他的均為輔助表。
- 維表變動也應當引起最終數據庫更新。
- 主表對輔助表為1:1或N1,也就是說主表的粒度是最細的, 輔表通過唯一鍵來和主表連接。
- 流表中可能存在唯一鍵一致的多張流表, 需要通過全連接關聯。唯一鍵不同的表之間通過左連接關聯。
- 只有連表和UDF,沒有groupby操作。
- 要求同步延時較小,支持多種源和目標介質。由于查詢壓力在目標介質,所以查詢qps沒有要求。
系統流程圖
明確需求后, 我們把SQL生成器總體功能分為兩塊:
- 同步生成SQL和建表數據
- 異步發布SQL和建表
之所以把生成SQL階段做成同步是因為同步階段內存操作為主,如果發現數據有問題無法生成SQL能做到快速失敗。發布階段調用Metrics需要同步等待較長時間, 每個發布步驟要做到有狀態記錄, 可回滾或者重試。所以異步實現。SQL生成器同步階段的整體功能細化到小模塊,如下圖所示:
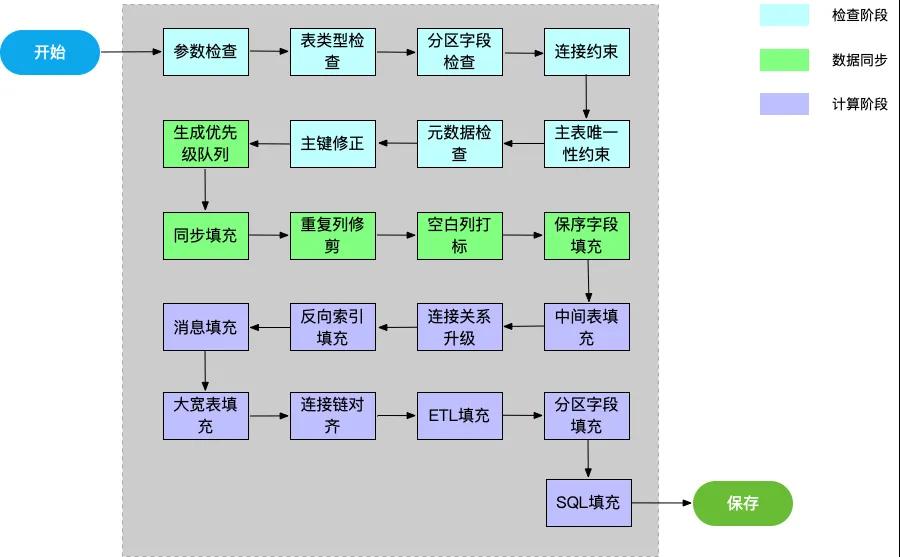
檢查階段
檢查原始數據是否有問題, 無法生成SQL則快速失敗。
- 參數檢查:檢查上游是否提供了基本的參數, 比如事實表信息(可以沒有維表, 但是必須有事實表)。
- 表類型檢查:檢查數據來源類型是否支持。
- 分區字段檢查:是否提供了大寬表分區字段。
- 連接約束:檢查流表,維表連接信息是否正確。
- 主表唯一性約束:檢查主表是否含連接信息,唯一鍵是否有ETL信息。
- 元數據檢查:檢查是否包含HBase配置信息。
- 主鍵修正:修正維表連接鍵, 必須是維表的唯一鍵。
數據同步
同步所有原始表和原始表的連接數據(比如源表同步進來, 生成1:1的HBase表)。
- 生成優先級隊列:生成連接和發布等任務的執行優先級。
- 同步填充:填充源表對應的同步階段HBase表數據,和對應的配置項, 類型轉換(比如源表是MySQL表,字段類型要轉換為HBase的類型), ETL填充, 添加消息隊列(通過發送消息的方式通知下游節點運行)。
- 重復列修剪:刪除重復的列。
- 空白列打標:對于滿足一定條件(比如不需要在大寬表展示, 不是唯一鍵列, 連接鍵列, 保序列)的列打上空白列標識。
- 保序字段填充:如果上游提供了表示數據創建時間的字段, 則用該字段作為數據保序字段, 沒有則填充系統接收到數據的時間作為保序字段。
計算階段
生成大寬表,填充SQL。
- 中間表填充:填充全連接產生的中間表。
- 連接關系升級:會在本文后面說明。
- 反向索引填充:填充“反向索引”信息。
- 消息填充:中間表添加消息隊列(中間表更新可以觸發下游節點)。
- 大寬表填充:填充大寬表數據。
- 連接鏈對齊:中間表和大寬表連接鍵對齊。
- ETL填充:填充大寬表列的ETL信息。
- 分區字段填充:填充大寬表分區字段。
- SQL填充:填充Flink同步表映射SQL語句, Flink計算SQL語句, Flink結果表映射SQL語句。
- 保存:把SQL和建表數據存入數據庫, 之后的請求可以復用已有的數據, 避免重復建表。
異步發布階段會把SQL語句發布到Flink。
添加反向索引的原因
假如有A、B兩表連接,那么連接方式為A表的非主鍵連接B表主鍵。從時序上來說可能有以下三種情況:
- B表數據先于A表數據多天產生
- B表數據后于A表數據多天產生
- B表數據和A表數據同時產生
下面我們就這三種情況逐一分析。
場景1:B表數據先于A表數據多天產生
我們假如B表數據存儲于某個支持高qps的數據庫內,我們可以直接讓A表數據到來時直接連接此表(維表)來實現連表。
場景2:B表數據后于A表數據多天產生
這種場景比較麻煩。A表數據先行產生,因此過早的落庫,導致B表數據到來時即使連接B維表也拿不到數據。這種場景還有一個類似的場景:如果AB連接完成后B發生了更新,如何讓B的更新體現在寬表中?
為了解決這種問題,我們增加了一個“反向索引表”。假如A的主鍵是id,連接鍵是ext_id,那么我們可以將ext_id和id的值存儲在一張表內,當B的數據更新時,用B的主鍵連接這種表的ext_id字段,拉取到所有的A表id字段,并將A表id字段重新流入Flink。
三 設計模式
對系統整體流程有了解以后, 我們再來看看系統的設計模式選擇,選擇設計模式時,我們考慮到數據處理相關的開發工作存在一些共性:
- 拆解后小功能多
- 小功能存在復用情況
- 小功能執行有嚴格的先后順序
需要記錄小功能運行狀態, 流程執行可回滾或者中斷可恢復執行
由于數據處理任務的步奏比較冗長,而且由于每個階段的結果與下階段的執行有關系,又不能分開。
參考 PipeLine(流水線)設計模式[2],綜合考慮后我們系統的整體設計如下圖所示:
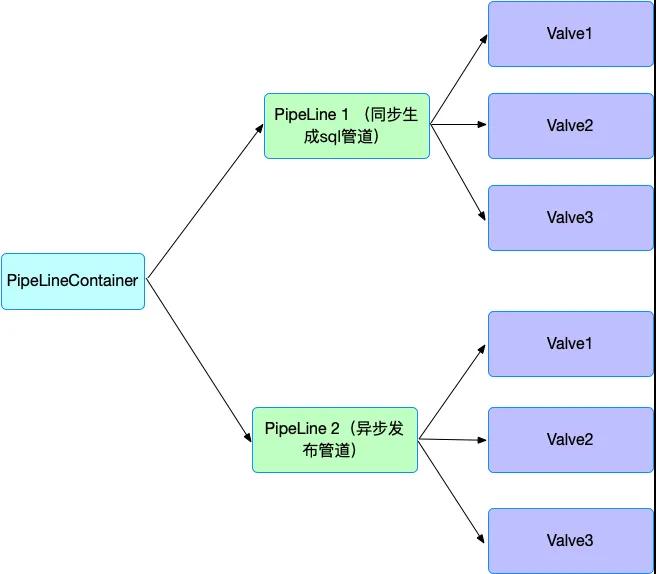
首先有一個全局的PipeLineContainer管理多個pipeLine和pipeline context, 每個pipeline可獨立執行一個任務, 比如pipeline1執行同步生成sql任務。pipeline2執行異步發布任務。發布必須在生成SQL結束后執行, pipeline有狀態并且按一定順序串聯。每個pipeline包含多個可重用的valve(功能)。valve可以重用, 任意組合,方便完成更多的數據處理任務(比如以后如果要支持Tisplus dump平臺接入, 則簡單拼接現有的valve就可以)。
四 數據結構和算法
問題說明
SQL生成器關鍵點, 就是把各個表(Meta節點)之間的關系表示出來。Meta之間的關系分為兩類,分別是全連接關聯和左連接關聯(因為左連接關聯涉及到數據的時序問題, 需要添加反向索引較為復雜, 所以和全連接區分了一下, 為了簡化問題我們先執行全連接, 再執行左連接)。
我們要解決的問題是, 多個數據源同步數據進來之后, 按一定的優先級關聯, 最終得到一個大寬表并需要自動發布。抽象到數據結構層面就是:
每個同步進來的數據源對應一個葉子節點
節點之間有關聯關系,關聯關系有多類并有執行優先級
所有節點和關聯關系組成一棵樹
最終得到一個根節點(大寬表)并發布
算法思路
下面說明下解決該問題的算法思路。
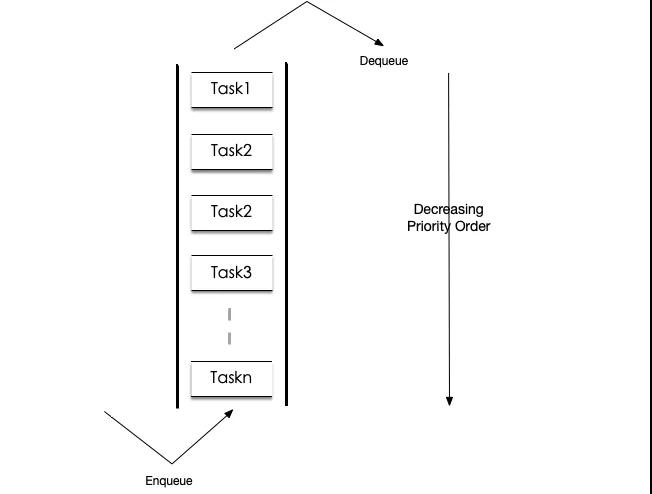
優先級隊列
因為葉子節點之間連接執行優先級不同,先放入優先級隊列。之后每次取出高優先級任務執行。相同優先級任務可以復用, 連續執行多次。優先級隊列示意圖如下:
構建樹
有了優先級隊列的概念, 我們來構建樹。構建主要分以下步驟:
首先得到四種優先級的任務, 優先級從高到低分別為:
- 優先級1, 六個節點的同步任務
- 優先級2,節點1、2、3和節點4、5的Full Join任務
- 優先級3,節點1、4和節點6的Left Join任務
- 優先級4, 發布任務
取優先級1的任務執行,同步進來六個數據源對應六個葉子。
取優先級2的任務并執行得到中間表1,2。
取優先級3的任務并執行,發現節點1、4有父節點, 則執行中間節點1、2分別和節點6 Left Join得到根節點。
取優先級4的任務并執行,發布根節點。
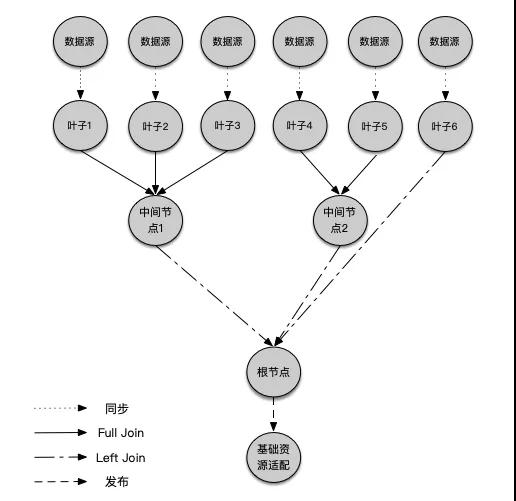
可以看到最終的數據結構是一棵樹, 通過這種方式我們能支持復雜sql的自動構建。進一步抽象, 這種“一個隊列驅動一棵樹生成”的模式可以解決一類問題:
- 問題的解決由一系列不同優先級的任務組成, 任務需要復用。
- 通過從隊列取優先級高的任務的方式構建任務關系樹。
- 最后遍歷樹完成各個節點任務。
五 總結
限于篇幅, 本文重點在于介紹自動生成sql功能開發中運用到的主要數據結構和設計模式思想。
目前我們實現了任意張表關聯sql自動生成并發布, 整體延遲控制在2s以內。之后SQL生成器主要會針對方便接入更多第三方實時計算平臺(比如Tisplus), 降低整體系統延遲工作展開。方便接入主要考驗的是架構的設計, 也是本文著重寫的點(包括數據結構和算法設計、設計模式的選擇)。降低系統延遲則包括消息中間件優化,代碼執行效率提升等。
最后
阿里巴巴供應鏈國際化團隊歡迎廣大有識之士加入,共同打造東半球零售業首選的國際化供應鏈平臺。有意請聯系:pengcheng.wang@alibaba-inc.com
相關鏈接
[1]https://book.douban.com/subject/26995807/
[2]https://blog.csdn.net/buyoufa/article/details/51912262
【本文為51CTO專欄作者“阿里巴巴官方技術”原創稿件,轉載請聯系原作者】