面試官:如何設計一個分布式 ID 生成器
作者:李華
分布式系統中設計分布式 ID 對于確保訂單、用戶或記錄等實體的唯一性至關重要。
分布式系統中設計分布式 ID 對于確保訂單、用戶或記錄等實體的唯一性至關重要。
分布式 ID 的設計需求
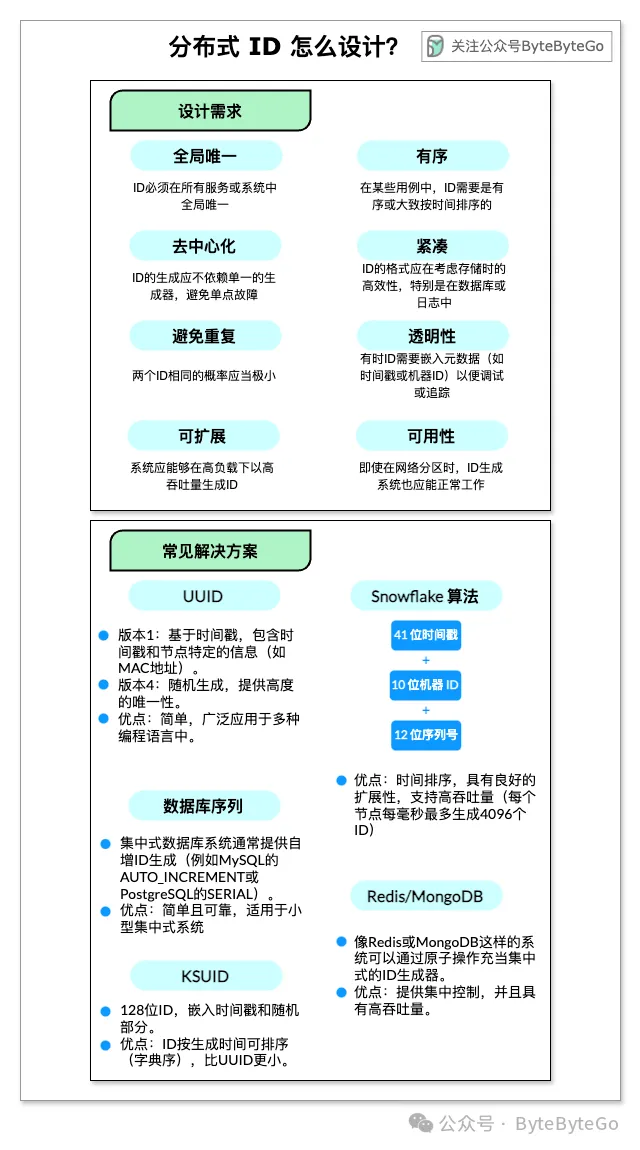
- 唯一性:ID 必須在所有服務或系統中全局唯一。
- 可擴展性:系統應能夠在高負載下以高吞吐量生成 ID。
- 排序性:在某些用例中,ID 需要是有序或大致按時間排序的(例如用于排序)。
- 避免碰撞:兩個 ID 相同的概率應當極小。
- 去中心化:ID 的生成應不依賴單一的生成器,避免單點故障。
- 可用性:即使在網絡分區時,ID 生成系統也應能正常工作。
- 緊湊性:ID 的格式應在存儲時高效,特別是在數據庫或日志中。
- 透明性:有時 ID 需要嵌入元數據(如時間戳或機器 ID )以便調試或追蹤。
常見的分布式 ID 解決方案
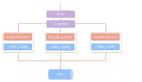
(1) UUID(通用唯一標識符)
- 版本1:基于時間戳,包含時間戳和節點特定的信息(如 MAC 地址)。
- 版本4:隨機生成,提供高度的唯一性。
- 優點:簡單,廣泛應用于多種編程語言中。
- 缺點:無序,較大(128位),不能輕易按生成時間排序。
- 適用場景:適用于排序要求不高的分布式系統,如對象存儲或用戶 ID。
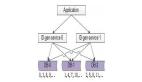
(2) Snowflake 算法(Twitter)
一個 64 位的 ID,包含以下部分:
- 41 位用于時間戳(從某個自定義的紀元開始的毫秒數)。
- 10 位用于機器 ID(數據中心或節點 ID)。
- 12 位用于序列號(確保同一毫秒內生成的多個 ID 是唯一的)。
- 優點:時間排序,具有良好的擴展性,支持高吞吐量(每個節點每毫秒最多生成 4096 個 ID)。
- 缺點:需要節點間時間同步。
- 適用場景:常用于分布式系統,如微服務或訂單管理系統。
(3) 數據庫序列
數據庫系統通常提供自增 ID 生成(例如 MySQL 的 AUTO_INCREMENT 或 PostgreSQL 的 SERIAL)。
- 優點:簡單且可靠,適用于小型集中式系統。
- 缺點:無法很好地擴展到分布式系統,會引入單點故障。
- 適用場景:適用于無需高擴展性的簡單應用。
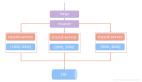
(4) KSUID(K-可排序的唯一標識符)
128 位 ID,嵌入時間戳和隨機部分。
- 優點:ID 按生成時間可排序(字典序),比 UUID 更小。
- 缺點:稍微比 UUID 復雜,空間效率不如 Snowflake。
- 適用場景:適用于需要字典序排序和較長生命周期的場景,如日志聚合系統。
(5) Redis / MongoDB 的序列生成器
像 Redis 或 MongoDB 這樣的系統可以通過原子操作充當集中式的 ID 生成器。
- 優點:提供集中控制,并且具有高吞吐量。
- 缺點:存在單點故障,依賴 Redis/MongoDB 的可用性。
- 適用場景:適用于分布式系統,中央節點可以在沒有高可用性要求的情況下生成 ID。
選擇解決方案的考慮因素
- 吞吐量需求:如果系統需要每秒生成數百萬個 ID,Snowflake 或 Redis-based 方案比 UUID 更合適。
- 有序還是隨機:如果 ID 需要按時間排序,可以考慮 Snowflake、KSUID。
- 存儲限制:與 KSUID 相比,Snowflake ID 更小,如果存儲大小至關重要,可以選擇更緊湊的格式。
- 元數據:如果需要在ID中包含元數據,Snowflake ID 或自定義哈希方案可以編碼時間戳或機器 ID 等信息。
每種解決方案適合不同的用例,具體選擇取決于擴展性、排序和存儲大小等因素。Snowflake 和 UUID 是現代分布式系統中最常采用的方案。
責任編輯:趙寧寧
來源:
ByteByteGo