人工智能對抗的場景探究
引言
人工智能技術已融入到各行各業(yè),從自動駕駛、人臉識別再到智能語音助手,人工智能就在身邊。人工智能帶來方便的同時,也引發(fā)了一定的安全問題。一方面攻擊者利用低門檻的人工智能技術實施非法行為,造成安全問題;另一方面,由于人工智能,特別是深度神經(jīng)網(wǎng)絡本身的技術不成熟性,使應用人工智能技術的系統(tǒng)很容易受到黑客攻擊。
深度神經(jīng)網(wǎng)絡的技術不成熟性主要在于模型的不可解釋性,從模型的訓練到測試階段都存在安全問題。訓練階段主要是數(shù)據(jù)投毒問題,通過在訓練數(shù)據(jù)中添加一些惡意的樣本來誤導模型的訓練結果。測試階段的安全問題主要是對抗樣本,在原始樣本中添加人眼不可察覺的微小擾動就能夠成功騙過分類器造成錯誤分類。
對抗樣本
自2013年起,深度學習模型在某些應用上已經(jīng)達到甚至超過了人類水平。特別是人臉識別、手寫數(shù)字識別等任務上。隨著神經(jīng)網(wǎng)絡模型的廣泛使用,其不可解釋特性被逐步擴大,出現(xiàn)了對抗樣本。類似于人類的「幻覺」,一張人眼看似旋轉的風車實質上是一張靜止的圖像(圖1a),一張馬和青蛙的圖片(圖1b)。既然「幻覺」可以騙過人的大腦,同樣地,對抗樣本也能騙過神經(jīng)網(wǎng)絡。
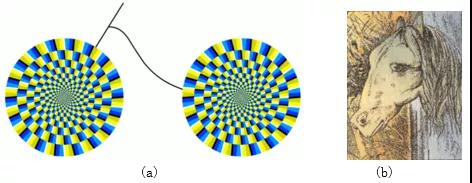
圖1 視覺幻覺圖
2014年,Szegedy等人[1]發(fā)現(xiàn)神經(jīng)網(wǎng)絡存在一些反直覺的特性,即對一張圖像添加不可察覺的微小擾動后,就能使分類器誤分類(圖2),并將這種添加擾動的樣本定義為對抗樣本。理論上來說,使用深度神經(jīng)網(wǎng)絡的模型,都存在對抗樣本。從此AI對抗開始成為了人工智能的一個熱點研究。
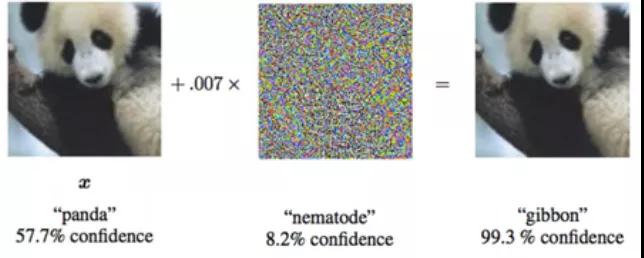
圖2 對抗樣本實例
應用場景
自對抗樣本被提出后,神經(jīng)網(wǎng)絡的安全性問題受到研究人員的格外重視。深度神經(jīng)網(wǎng)絡已經(jīng)在各個領域取得了令人矚目的成果,如果因神經(jīng)網(wǎng)絡本身的安全性給應用和系統(tǒng)帶來安全威脅,將造成巨大的損失。例如,在自動駕駛領域,車載模型被攻擊后將停車路標誤識別為限速標志,可能造成人身安全;垃圾郵件檢測模型被攻擊后,垃圾郵件或者惡意郵件將不會被攔截。目前對抗樣本的研究已經(jīng)存在于圖像、文本、音頻、推薦系統(tǒng)等領域。
1.計算機視覺
(1)圖像分類/識別
Szegedy首次發(fā)現(xiàn)深度神經(jīng)網(wǎng)絡存在對抗樣本是在圖像分類的背景下,對原始圖片添加微小的像素擾動,就能導致圖像分類器誤分類,且該微小擾動對人眼是不可察覺的。目前對抗攻擊在圖像分類領域已較為成熟,不僅提出了針對單一圖像的攻擊算法,還提出針對任意圖像的通用擾動方法,并且針對攻擊的防御方法也大量涌現(xiàn)。
L-BFGS:2013年,Szegedy等人[1]提出了L-BFGS簡單有界約束算法,尋找一個與原始樣本擾動距離最小又能夠使分類器誤分類的對抗樣本。
FGSM(Fast Gradient Sign Method)[2]:該算法是由Goodfellow等人提出的,一種經(jīng)典的對抗樣本生成方法,在預知模型本身參數(shù)的前提下,在原始圖片的梯度下降方向添加擾動以生成對抗樣本。
JSMA(Jacobian-based saliency map attack)[3]:該算法是由Papernot等人提出的,建立在攻擊者已知模型相關信息的前提下,根據(jù)分類器的結果反饋只修改輸入圖片中對輸出影響最大的關鍵像素,以欺騙神經(jīng)網(wǎng)絡。
One Pixel Attack[4]:該方法于2017年被提出,只需要修改輸入圖像的一個像素點就能夠成功欺騙深度神經(jīng)網(wǎng)絡,One Pixel攻擊不僅簡單,而且不需要訪問模型的參數(shù)和梯度信息。
C&W算法[5]:是一種基于優(yōu)化的攻擊方法,生成的對抗樣本和原始樣本之間的距離最短,且攻擊強度最大。算法在迭代過程中,將原始樣本和對抗樣本之間的可區(qū)分性相結合作為新的優(yōu)化目標。
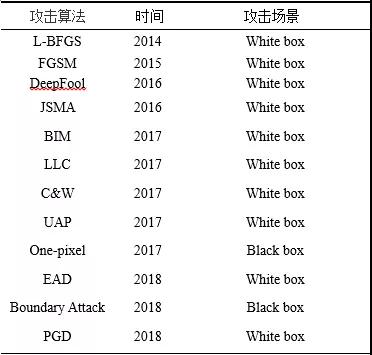
其他的攻擊算法包括DeepFool、UAP、BIM、PGD等,如表1所示。
表1圖像攻擊算法
(2)人臉識別
人臉識別系統(tǒng)越來越廣泛,其應用領域多數(shù)涉及隱私,因此人臉識別模型的安全性至關重要。2018年,Rozsa等人[6]探索了人臉識別中的深度學習模型在對抗樣本中的穩(wěn)定性,通過“Fast Flipping Attribute”方法生成的對抗樣本攻擊深度神經(jīng)網(wǎng)絡分類器,發(fā)現(xiàn)對抗攻擊有效地改變了人臉圖片中目標屬性標簽。如圖3所示,添加微小擾動的“女性”圖片被人臉識別模型判別為“男性”。
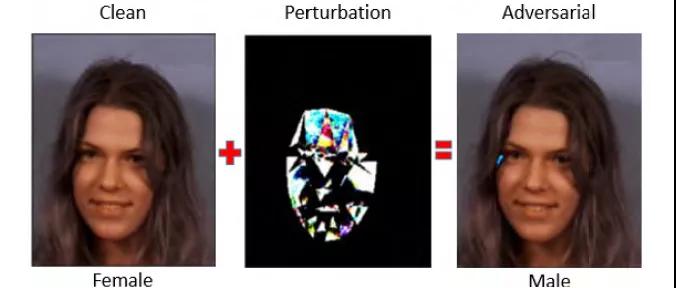
圖3 人臉識別對抗樣本實例
(3)圖像語義分割
圖像語義分割是建立在圖像目標分類的基礎上,對目標區(qū)域或者像素進行分類。語義分割的對抗攻擊考慮是否能夠在一組像素的基礎上優(yōu)化損失函數(shù),從而生成對抗樣本。Xie等人[11]基于每個目標都需要經(jīng)歷一個單獨的分類過程而提出了一種密度對抗生成網(wǎng)絡DAG,是一種經(jīng)典的語義分割和目標檢測的攻擊方法。該方法同時考慮所有目標并優(yōu)化整體損失函數(shù),只需要為每個目標指定一個對抗性標簽,并迭代執(zhí)行梯度反向傳播獲取累積擾動。
(4)目標檢測
目標檢測作為計算機視覺的核心任務也受到了對抗攻擊[7]-[10]。目前,目標檢測模型主要分為兩類:基于提議的和基于回歸的模型,這種機制使目標檢測的對抗攻擊相比于圖像分類更復雜。文獻[7]提出了一種針對兩種模型可遷移且高效的目標檢測的對抗樣本生成方法UEA(圖4),該方法利用條件GAN來生成對抗樣本,并在其上多加幾個損失函數(shù)來監(jiān)督生成器的生成效果。
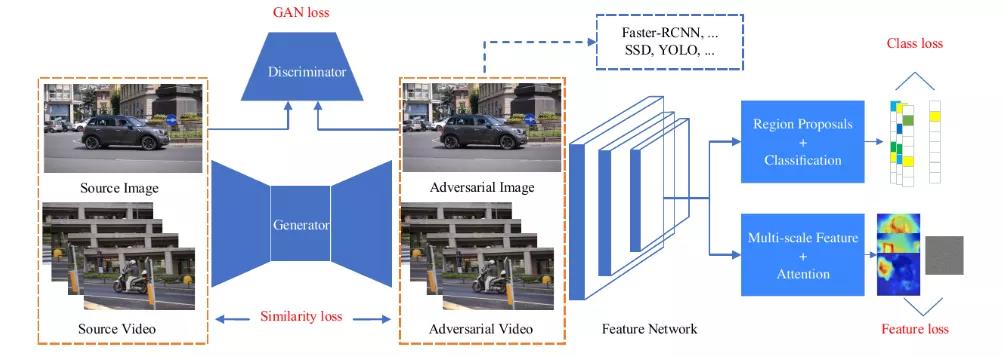
圖4 UEA對抗攻擊訓練框架
(5)自動駕駛
自動駕駛汽車由多個子系統(tǒng)構成,包括負責場景識別、根據(jù)場景預測汽車運動以及控制發(fā)動機完成汽車駕駛的子系統(tǒng)。而目前,這三方面都逐漸使用深度學習模型搭建,給出較優(yōu)決策結果的同時也引發(fā)了物理場景的對抗攻擊問題。Evtimov等人[21]提出了一種物理場景的對抗攻擊算法RF2,使各種路標識別器識別失敗。在原始路標圖像上添加涂鴉或黑白塊, “STOP”路標就能識別成限速路標,右轉路標誤識別為“STOP”路標或添加車道路標。

圖5 路標對抗樣本
2.自然語言處理
自然語言處理是除計算機視覺外人工智能應用最為廣泛的領域之一,因此人工智能本身的脆弱性也將導致自然語言處理任務出現(xiàn)安全隱患。但又不同于計算機視覺中對圖像的攻擊方式,自然語言處理領域操作的是文本序列數(shù)據(jù),主要難點在于:①圖像是連續(xù)數(shù)據(jù),通過擾動一些像素仍然能夠維持圖片的完整性,而文本數(shù)據(jù)是離散的,任意添加字符或單詞將導致句子缺失語義信息;②圖像像素的微小擾動對人眼是不可察覺的,而文本的細微變化很容易引起察覺。目前,自然語言處理在情感分類、垃圾郵件分類、機器翻譯等領域都發(fā)現(xiàn)了對抗樣本的攻擊[12]-[15],攻擊方法除了改進計算機視覺中的攻擊算法,還有一部分針對文本領域新提出的攻擊算法。
(1)文本分類
在情感分析任務中,分類模型根據(jù)每條影評中的詞判別語句是積極或消極。但若在消極語句中擾動某些詞將會使情感分類模型誤分類為積極情感。Papernot等人[13]將計算機視覺領域的JSMA算法遷移到文本領域,利用計算圖展開技術來評估與單詞序列的嵌入輸入有關的前向導數(shù),構建雅可比矩陣,并借鑒FGSM的思想計算對抗擾動。
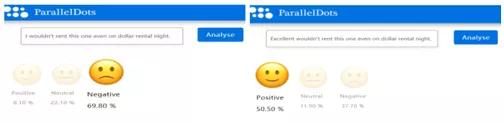
圖6 情感分析任務中的對抗樣本
在垃圾郵件分類任務中,如果模型受到對抗樣本的攻擊,垃圾郵件發(fā)布者就可以繞過模型的攔截。文獻[16]提出了一種基于GAN式的對抗樣本生成方法,為了解決GAN不能直接應用到離散的文本數(shù)據(jù)上的問題,提出采用增強學習任務(REINFORCE)獎勵能夠同時滿足使目標判別器誤分類和具有相似語義的對抗樣本。
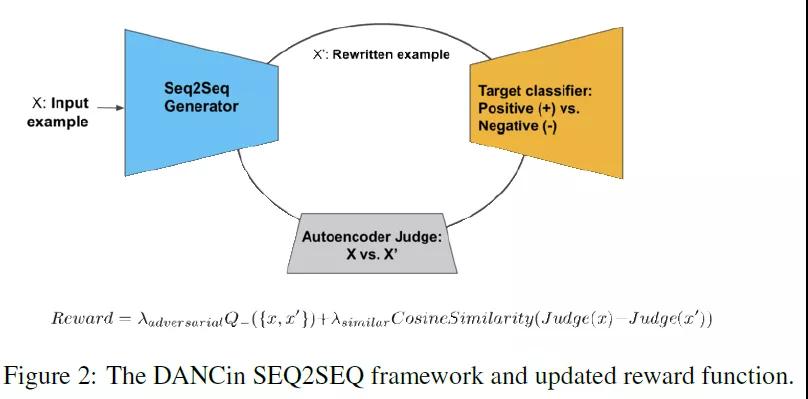
圖7 基于增強學習的GAN
(2)機器翻譯/文本摘要
不同于文本分類任務輸出空間是有限的類別結果,機器翻譯任務的輸出空間是無限的。Cheng等人[15]提出了一種針對seq2seq模型的對抗樣本生成方法,對于離散輸入空間帶來的問題,提出使用一種結合group lasso和梯度正則化的投影梯度法,針對輸出空間是序列數(shù)據(jù)的問題,設計了新穎的損失函數(shù)來實現(xiàn)無重疊和目標關鍵詞攻擊。
3.網(wǎng)絡安全
網(wǎng)絡安全領域已廣泛使用深度學習模型自動檢測威脅情報,如果將對抗攻擊轉移到對安全更加敏感的應用,如惡意軟件探測方面,這可能在樣本生成上提出重大的挑戰(zhàn)。同時,失敗可能給網(wǎng)絡遺留嚴重漏洞。目前,對抗攻擊在惡意軟件檢測、入侵檢測等方向已展開對抗研究[16]-[18]。
(1)惡意軟件檢測
相較于之前的計算機視覺問題,惡意軟件應用場景有如下限制:①輸入不是連續(xù)可微的,而是離散的,且通常是二分數(shù)據(jù);②不受約束的視覺不變性需要用同等的函數(shù)替代。Grosse等人[16]驗證了對抗攻擊在惡意軟件識別領域的可行性,將惡意軟件用二進制特征向量表示,并借鑒Papernot等人[13]采用的JSMA算法實施攻擊,實驗證明了對抗攻擊在惡意軟件探測領域確實存在。
(2)惡意域名檢測
惡意域名中的DGA家族因頻繁變換和善偽裝等特點,使機器學習模型在識別階段魯棒性不高。Hyrum等人[17]提出了一種基于GAN的惡意域名樣本生成方法DeepDGA,利用生成的惡意域名進行對抗性訓練來增強機器模型來提高DGA域名家族的識別準確度,結果表明,由GAN生成的惡意域名能夠成功地躲避隨機森林分類器的識別,并且加入對抗樣本訓練后的隨機森林對DGA家族的識別準確度明顯高于對抗訓練的結果。

圖8 DeepDGA生成的惡意域名
(3)DDoS攻擊
在DDoS攻擊領域,Peng等人[18]提出了改進的邊界攻擊方法生成DDoS攻擊的對抗樣本,通過迭代地修改輸入樣本來逼近目標模型的決策邊界。
4.語音識別
目前,語音識別技術的落地場景較多,如智能音箱、智能語音助手等。雖然語音識別技術發(fā)展良好,但因深度學習模型本身的脆弱性,語音識別系統(tǒng)也不可避免地受到對抗樣本的攻擊。2018年,伯克利人工智能研究員Carlini 和Wagner發(fā)明了一種針對語音識別的新型攻擊方法,該方法也是首次針對語音識別系統(tǒng)的攻擊,通過生成原始音頻的基線失真噪音來構造對抗音頻樣本,能夠欺騙語音識別系統(tǒng)使它產(chǎn)生任何攻擊者想要的輸出[19]。
5.推薦系統(tǒng)
在推薦系統(tǒng)領域,如果推薦模型被攻擊,下一個推薦的item將是人為設定的廣告。基于協(xié)同過濾(CF)的潛在因素模型,由于其良好的性能和推薦因素,在現(xiàn)代推薦系統(tǒng)中得到了廣泛的應用。但事實表明,這些方法易受到對抗攻擊的影響,從而導致不可預測的危害推薦結果。目前,推薦系統(tǒng)常用的攻擊方法是基于計算機視覺的攻擊算法FGSM、C&W、GAN等[20]。目前該領域的對抗攻擊仍存在挑戰(zhàn):①由于推薦系統(tǒng)的預測是依賴一組實例而非單個實例,導致對抗攻擊可能出現(xiàn)瀑布效應,對某個單一用戶的攻擊可能影響到相鄰用戶;②相比于圖像的連續(xù)數(shù)據(jù),推薦系統(tǒng)的原始數(shù)據(jù)是離散的用戶/項目ID和等級,直接擾動離散的實體將導致輸入數(shù)據(jù)的語義信息發(fā)生改變。并且如何保持推薦系統(tǒng)對抗樣本的視覺不可見性依然有待解決。
小 結
目前該領域的研究方向和攻擊算法眾多,一種攻擊算法被提出后就會出現(xiàn)一種應對的防御方法,接著針對該防御方法再提出新的攻擊方法,但在類似的攻防循環(huán)中還缺乏評判攻擊是否有效的評估方法,此外有一些領域存在對抗攻擊的情況但目前仍未被研究和發(fā)現(xiàn)。
參考文獻…
[1] Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[J]. arXiv preprint arXiv:1312.6199, 2013.
[2] I. Goodfellow, J. Shlens, C. Szegedy. Explaining and Harnessing Adversarial Examples[C]. ICLR, 2015.
[3] N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, A. Swami. The Limitations of Deep Learning in Adversarial Settings[C]// Proceedings of IEEE European Symposium on Security and Privacy. IEEE, 2016.
[4] J. Su, D. V. Vargas, S. Kouichi. One pixel attack for fooling deep neural networks[J]. IEEE Transactions on Evolutionary Computation, 2017.
[5] N. Carlini, D. Wagner. Towards Evaluating the Robustness of Neural Networks [C]// Proceedings of IEEE Symposium on Security and Privacy (SP). IEEE, 2017: 39-57.
[6] Rozsa A, Günther M, Rudd E M, et al. Facial attributes: Accuracy and adversarial robustness[J]. Pattern Recognition Letters, 2019, 124: 100-108.
[7] Wei X, Liang S, Chen N, et al. Transferable adversarial attacks for image and video object detection[J]. arXiv preprint arXiv:1811.12641, 2018.
[8] Cihang Xie, Jianyu Wang, Zhishuai Zhang, Yuyin Zhou, Lingxi Xie, and Alan Yuille. Adversarial examples for semantic segmentation and object detection.
[9] Shang-Tse Chen, Cory Cornelius, Jason Martin, and Duen Horng Chau. Robust physical adversarial attack on faster r-cnn object detector. arXiv preprint arXiv:1804.05810, 2018.
[10] Yuezun Li, Daniel Tian, Xiao Bian, Siwei Lyu, et al. Robust adversarial perturbation on deep proposal-based models. arXiv preprint arXiv:1809.05962, 2018.
[11] Xie C, Wang J, Zhang Z, et al. Adversarial examples for semantic segmentation and object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 1369-1378.
[12] J. Li, S. Ji, T. Du, B. Li, and T. Wang, “Textbugger: Generating adversarial text against real-world applications,” in the Network and Distributed System Security Symposium, 2019.
[13] Nicolas Papernot, Patrick McDaniel, Ananthram Swami, and Richard Harang. 2016. Crafting Adversarial Input Sequences for Recurrent Neural Networks. In Military Communications Conference(MILCOM). IEEE, 2016: 49–54
[14] Wong C. Dancin seq2seq: Fooling text classifiers with adversarial text example generation[J]. arXiv preprint arXiv:1712.05419, 2017.
[15] Cheng M, Yi J, Chen P Y, et al. Seq2Sick: Evaluating the Robustness of Sequence-to-Sequence Models with Adversarial Examples[C]//AAAI. 2020: 3601-3608.
[16] Grosse K, Papernot N, Manoharan P, et al. Adversarial perturbations against deep neural networks for malware classification[J]. arXiv preprint arXiv:1606.04435, 2016.
[17] Anderson H S, Woodbridge J, Filar B. DeepDGA: Adversarially-tuned domain generation and detection[C]//Proceedings of the 2016 ACM Workshop on Artificial Intelligence and Security. 2016: 13-21.
[18] Peng X, Huang W, Shi Z. Adversarial Attack Against DoS Intrusion Detection: An Improved Boundary-Based Method[C]//2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 2019: 1288-1295.
[19] Carlini N, Wagner D. Audio adversarial examples: Targeted attacks on speech-to-text[C]//2018 IEEE Security and Privacy Workshops (SPW). IEEE, 2018: 1-7.
[20] Deldjoo Y, Di Noia T, Merra F A. Adversarial Machine Learning in Recommender Systems: State of the art and Challenges[J]. arXiv preprint arXiv:2005.10322, 2020.
[21] Eykholt K, Evtimov I, Fernandes E, et al. Robust physical-world attacks on deep learning visual classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 1625-1634.

【本文為51CTO專欄作者“中國保密協(xié)會科學技術分會”原創(chuàng)稿件,轉載請聯(lián)系原作者】