Kafka設(shè)計(jì)原理詳解
Kafka核心總控制器Controller
在Kafka集群中會(huì)有一個(gè)或者多個(gè)broker,其中有一個(gè)broker會(huì)被選舉為控制器(Kafka Controller),它負(fù)責(zé)管理整個(gè)集群中所有分區(qū)和副本的狀態(tài)。
- 當(dāng)某個(gè)分區(qū)的leader副本出現(xiàn)故障時(shí),由控制器負(fù)責(zé)為該分區(qū)選舉新的leader副本。
- 當(dāng)檢測(cè)到某個(gè)分區(qū)的ISR集合發(fā)生變化時(shí),由控制器負(fù)責(zé)通知所有broker更新其元數(shù)據(jù)信息。
- 當(dāng)使用kafka-topics.sh腳本為某個(gè)topic增加分區(qū)數(shù)量時(shí),同樣還是由控制器負(fù)責(zé)讓新分區(qū)被其他節(jié)點(diǎn)感知到。
Controller選舉機(jī)制
在kafka集群?jiǎn)?dòng)的時(shí)候,會(huì)自動(dòng)選舉一臺(tái)broker作為controller來(lái)管理整個(gè)集群,選舉的過(guò)程是集群中每個(gè)broker都會(huì)嘗試在zookeeper上創(chuàng)建一個(gè) /controller 臨時(shí)節(jié)點(diǎn),zookeeper會(huì)保證有且僅有一個(gè)broker能創(chuàng)建成功,這個(gè)broker就會(huì)成為集群的總控器controller。 當(dāng)這個(gè)controller角色的broker宕機(jī)了,此時(shí)zookeeper臨時(shí)節(jié)點(diǎn)會(huì)消失,集群里其他broker會(huì)一直監(jiān)聽這個(gè)臨時(shí)節(jié)點(diǎn),發(fā)現(xiàn)臨時(shí)節(jié)點(diǎn)消失了,就競(jìng)爭(zhēng)再次創(chuàng)建臨時(shí)節(jié)點(diǎn),就是我們上面說(shuō)的選舉機(jī)制,zookeeper又會(huì)保證有一個(gè)broker成為新的controller。
- 監(jiān)聽broker相關(guān)的變化。為Zookeeper中的/brokers/ids/節(jié)點(diǎn)添加BrokerChangeListener,用來(lái)處理broker增減的變化。
- 監(jiān)聽topic相關(guān)的變化。為Zookeeper中的/brokers/topics節(jié)點(diǎn)添加TopicChangeListener,用來(lái)處理topic增減的變化;為Zookeeper中的/admin/delete_topics節(jié)點(diǎn)添加TopicDeletionListener,用來(lái)處理刪除topic的動(dòng)作。
從Zookeeper中讀取獲取當(dāng)前所有與topic、partition以及broker有關(guān)的信息并進(jìn)行相應(yīng)的管理。對(duì)于所有topic所對(duì)應(yīng)的Zookeeper中的/brokers/topics/[topic]節(jié)點(diǎn)添加PartitionModificationsListener,用來(lái)監(jiān)聽topic中的分區(qū)分配變化。
更新集群的元數(shù)據(jù)信息,同步到其他普通的broker節(jié)點(diǎn)中。
Partition副本選舉Leader機(jī)制
controller感知到分區(qū)leader所在的broker掛了(controller監(jiān)聽了很多zk節(jié)點(diǎn)可以感知到broker存活),controller會(huì)從每個(gè)parititon的 replicas 副本列表中取出第一個(gè)broker作為leader,當(dāng)然這個(gè)broker需要也同時(shí)在ISR列表里。
消費(fèi)者消費(fèi)消息的offset記錄機(jī)制
每個(gè)consumer會(huì)定期將自己消費(fèi)分區(qū)的offset提交給kafka內(nèi)部topic:__consumer_offsets,提交過(guò)去的時(shí)候,key是consumerGroupId+topic+分區(qū)號(hào),value就是當(dāng)前offset的值,kafka會(huì)定期清理topic里的消息,最后就保留最新的那條數(shù)據(jù),因?yàn)開_consumer_offsets可能會(huì)接收高并發(fā)的請(qǐng)求,kafka默認(rèn)給其分配50個(gè)分區(qū)(可以通過(guò)offsets.topic.num.partitions設(shè)置),這樣可以通過(guò)加機(jī)器的方式抗大并發(fā)。
消費(fèi)者Rebalance機(jī)制
消費(fèi)者rebalance就是說(shuō)如果consumer group中某個(gè)消費(fèi)者掛了,此時(shí)會(huì)自動(dòng)把分配給他的分區(qū)交給其他的消費(fèi)者,如果他又重啟了,那么又會(huì)把一些分區(qū)重新交還給他。
注意:rebalance只針對(duì)subscribe這種不指定分區(qū)消費(fèi)的情況,如果通過(guò)assign這種消費(fèi)方式指定了分區(qū),kafka不會(huì)進(jìn)行rebanlance。
如下情況可能會(huì)觸發(fā)消費(fèi)者rebalance
- consumer所在服務(wù)重啟或宕機(jī)了
- 動(dòng)態(tài)給topic增加了分區(qū)
- 消費(fèi)組訂閱了更多的topic
Rebalance過(guò)程
第一階段:選擇組協(xié)調(diào)器
組協(xié)調(diào)器GroupCoordinator:每個(gè)consumer group都會(huì)選擇一個(gè)broker作為自己的組協(xié)調(diào)器coordinator,負(fù)責(zé)監(jiān)控這個(gè)消費(fèi)組里的所有消費(fèi)者的心跳,以及判斷是否宕機(jī),然后開啟消費(fèi)者rebalance。
consumer group中的每個(gè)consumer啟動(dòng)時(shí)會(huì)向kafka集群中的某個(gè)節(jié)點(diǎn)發(fā)送 FindCoordinatorRequest 請(qǐng)求來(lái)查找對(duì)應(yīng)的組協(xié)調(diào)器GroupCoordinator,并跟其建立網(wǎng)絡(luò)連接。
組協(xié)調(diào)器選擇方式:通過(guò)如下公式可以選出consumer消費(fèi)的offset要提交到__consumer_offsets的哪個(gè)分區(qū),這個(gè)分區(qū)leader對(duì)應(yīng)的broker就是這個(gè)consumer group的coordinator
公式:hash(consumer group id) % __consumer_offsets主題的分區(qū)數(shù)
第二階段:加入消費(fèi)組JOIN GROUP
在成功找到消費(fèi)組所對(duì)應(yīng)的 GroupCoordinator 之后就進(jìn)入加入消費(fèi)組的階段,在此階段的消費(fèi)者會(huì)向 GroupCoordinator 發(fā)送 JoinGroupRequest 請(qǐng)求,并處理響應(yīng)。然后GroupCoordinator 從一個(gè)consumer group中選擇第一個(gè)加入group的consumer作為leader(消費(fèi)組協(xié)調(diào)器),把consumer group情況發(fā)送給這個(gè)leader,接著這個(gè)leader會(huì)負(fù)責(zé)制定分區(qū)方案。
第三階段( SYNC GROUP)
consumer leader通過(guò)給GroupCoordinator發(fā)送SyncGroupRequest,接著GroupCoordinator就把分區(qū)方案下發(fā)給各個(gè)consumer,他們會(huì)根據(jù)指定分區(qū)的leader broker進(jìn)行網(wǎng)絡(luò)連接以及消息消費(fèi)。
消費(fèi)者Rebalance分區(qū)分配策略
主要有三種rebalance的策略:range、round-robin、sticky。
Kafka 提供了消費(fèi)者客戶端參數(shù)partition.assignment.strategy 來(lái)設(shè)置消費(fèi)者與訂閱主題之間的分區(qū)分配策略。默認(rèn)情況為range分配策略。
假設(shè)一個(gè)主題有10個(gè)分區(qū)(0-9),現(xiàn)在有三個(gè)consumer消費(fèi):
- range策略:按照分區(qū)序號(hào)排序,假設(shè) n=分區(qū)數(shù)/消費(fèi)者數(shù)量 = 3, m=分區(qū)數(shù)%消費(fèi)者數(shù)量 = 1,那么前 m 個(gè)消費(fèi)者每個(gè)分配 n+1 個(gè)分區(qū),后面的(消費(fèi)者數(shù)量-m )個(gè)消費(fèi)者每個(gè)分配 n 個(gè)分區(qū)。比如分區(qū)0~3給一個(gè)consumer,分區(qū)4~6給一個(gè)consumer,分區(qū)7~9給一個(gè)consumer。
- round-robin策略:輪詢分配,比如分區(qū)0、3、6、9給一個(gè)consumer,分區(qū)1、4、7給一個(gè)consumer,分區(qū)2、5、8給一個(gè)consumer
- sticky策略:rebalance的時(shí)候,需要保證如下兩個(gè)原則。
- 分區(qū)的分配要盡可能均勻 。
- 分區(qū)的分配盡可能與上次分配的保持相同。
當(dāng)兩者發(fā)生沖突時(shí),第一個(gè)目標(biāo)優(yōu)先于第二個(gè)目標(biāo) 。這樣可以最大程度維持原來(lái)的分區(qū)分配的策略。
比如對(duì)于第一種range情況的分配,如果第三個(gè)consumer掛了,那么重新用sticky策略分配的結(jié)果如下:
- consumer1除了原有的0~3,會(huì)再分配一個(gè)7
- consumer2除了原有的4~6,會(huì)再分配8和9
producer發(fā)布消息機(jī)制剖析
1、寫入方式
producer 采用 push 模式將消息發(fā)布到 broker,每條消息都被 append 到 patition 中,屬于順序?qū)懘疟P(順序?qū)懘疟P效率比隨機(jī)寫內(nèi)存要高,保障 kafka 吞吐率)。
2、消息路由
producer 發(fā)送消息到 broker 時(shí),會(huì)根據(jù)分區(qū)算法選擇將其存儲(chǔ)到哪一個(gè) partition。其路由機(jī)制為:1. 指定了 patition,則直接使用; 2. 未指定 patition 但指定 key,通過(guò)對(duì) key 的 value 進(jìn)行hash 選出一個(gè) patition 3. patition 和 key 都未指定,使用輪詢選出一個(gè) patition。
3、寫入流程
計(jì)原理詳解")
- producer 先從 zookeeper 的 "/brokers/.../state" 節(jié)點(diǎn)找到該 partition 的 leader
- producer 將消息發(fā)送給該 leader
- leader 將消息寫入本地 log
- followers 從 leader pull 消息,寫入本地 log 后 向leader 發(fā)送 ACK
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 發(fā)送 ACK
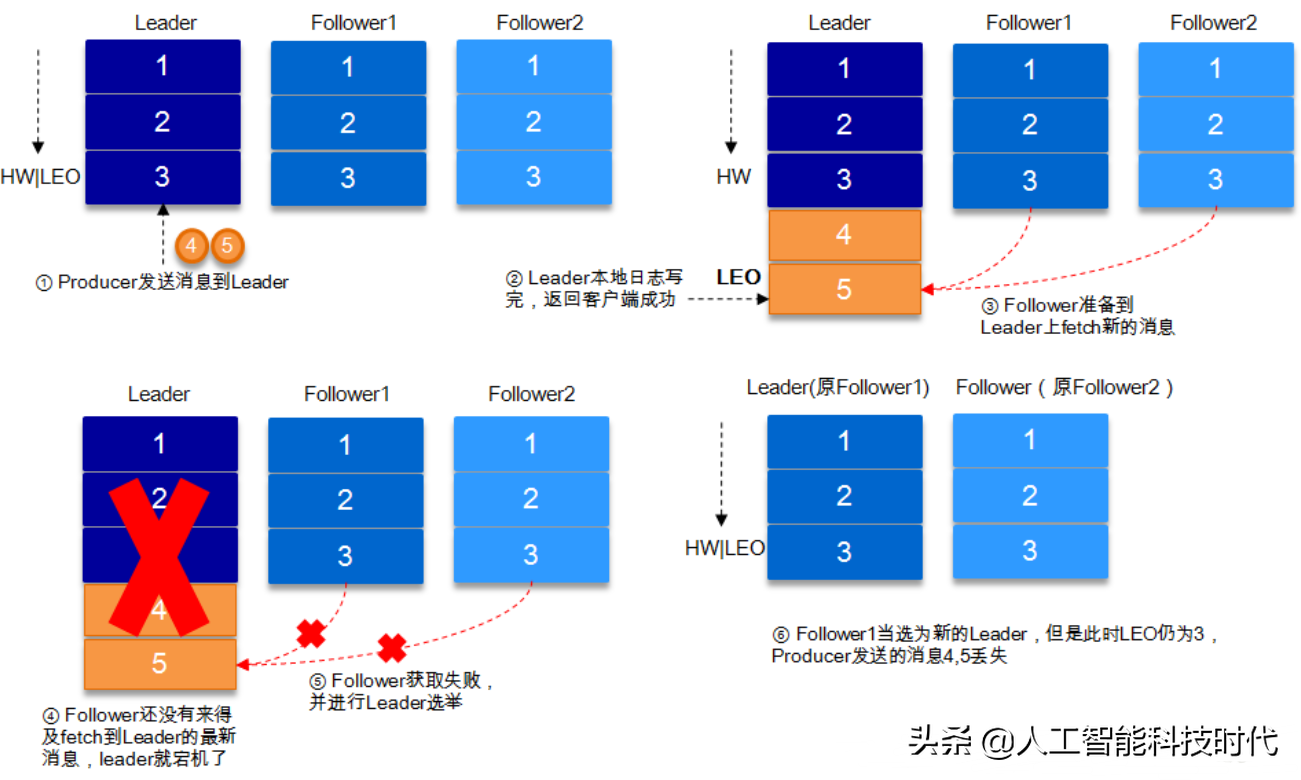
HW與LEO詳解
HW俗稱高水位,HighWatermark的縮寫,取一個(gè)partition對(duì)應(yīng)的ISR中最小的LEO(log-end-offset)作為HW,consumer最多只能消費(fèi)到HW所在的位置。另外每個(gè)replica都有HW,leader和follower各自負(fù)責(zé)更新自己的HW的狀態(tài)。對(duì)于leader新寫入的消息,consumer不能立刻消費(fèi),leader會(huì)等待該消息被所有ISR中的replicas同步后更新HW,此時(shí)消息才能被consumer消費(fèi)。這樣就保證了如果leader所在的broker失效,該消息仍然可以從新選舉的leader中獲取。對(duì)于來(lái)自內(nèi)部broker的讀取請(qǐng)求,沒有HW的限制。
舉例當(dāng)producer生產(chǎn)消息至broker后,ISR以及HW和LEO的流轉(zhuǎn)過(guò)程
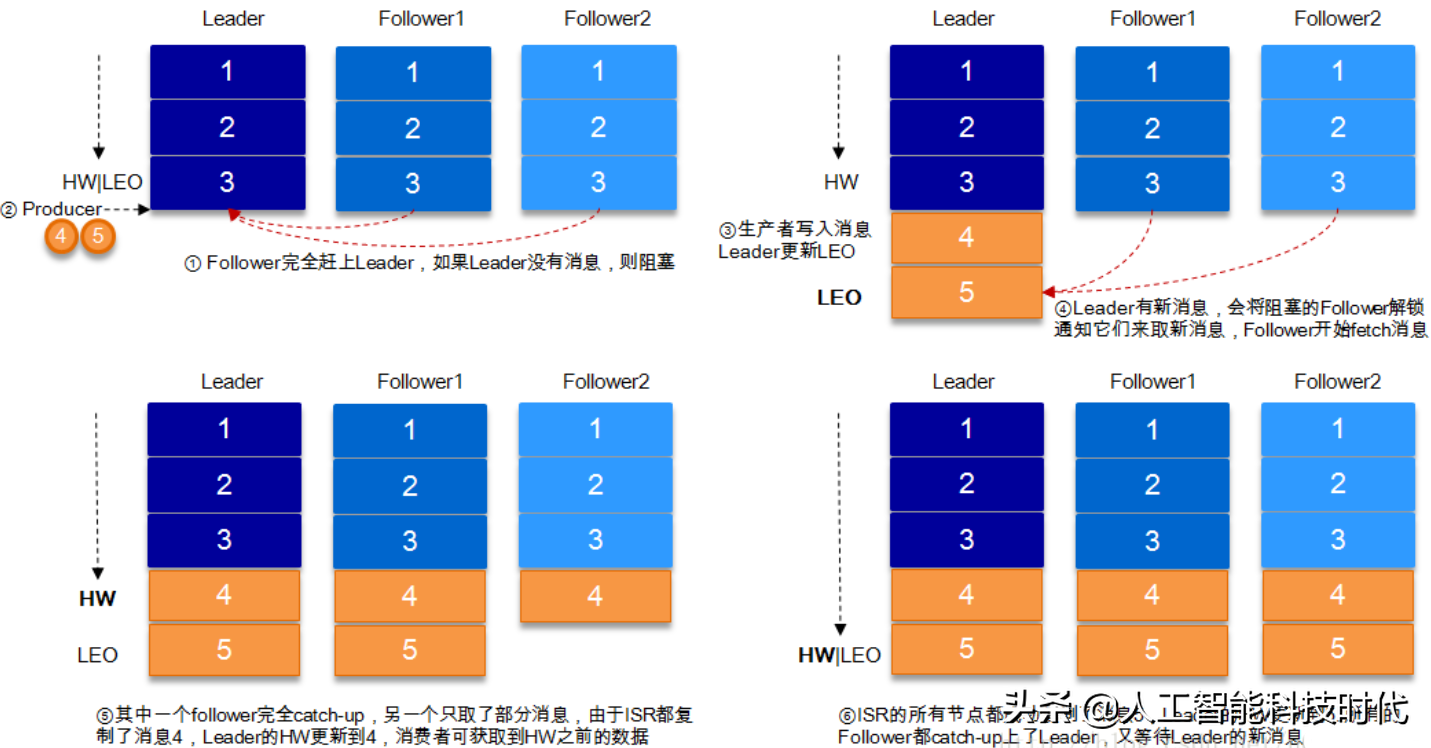
由此可見,Kafka的復(fù)制機(jī)制既不是完全的同步復(fù)制,也不是單純的異步復(fù)制。事實(shí)上,同步復(fù)制要求所有能工作的follower都復(fù)制完,這條消息才會(huì)被commit,這種復(fù)制方式極大的影響了吞吐率。而異步復(fù)制方式下,follower異步的從leader復(fù)制數(shù)據(jù),數(shù)據(jù)只要被leader寫入log就被認(rèn)為已經(jīng)commit,這種情況下如果follower都還沒有復(fù)制完,落后于leader時(shí),突然leader宕機(jī),則會(huì)丟失數(shù)據(jù)。而Kafka的這種使用ISR的方式則很好的均衡了確保數(shù)據(jù)不丟失以及吞吐率。
結(jié)合HW和LEO看下 acks=1的情況