Kubernetes探針踩坑記
本文轉載自微信公眾號「Dotnet Plus」,可以通過以下二維碼關注。轉載本文請聯系Dotnet Plus公眾號。

1. 荒腔走板
最近一兩個月生產K8s集群頻繁出現短時503 Service Temporarily Unavailable,還不能主動復現,相當郁悶,壓力山大。

HTTP 5xx響應狀態碼用于定義服務端錯誤。
- 500 Internal Server Error:所請求的服務器遇到意外的情況并阻止其執行請求,通常針對單個請求,整個站點有時還是提供服務。
- 502 Bad Gateway Error 暗示連接鏈路中某個服務器下線或者不可用;
- 503 Service Unavailable 意味著托管您的應用程序的實際Web服務器上存在問題。
2. 排查記錄
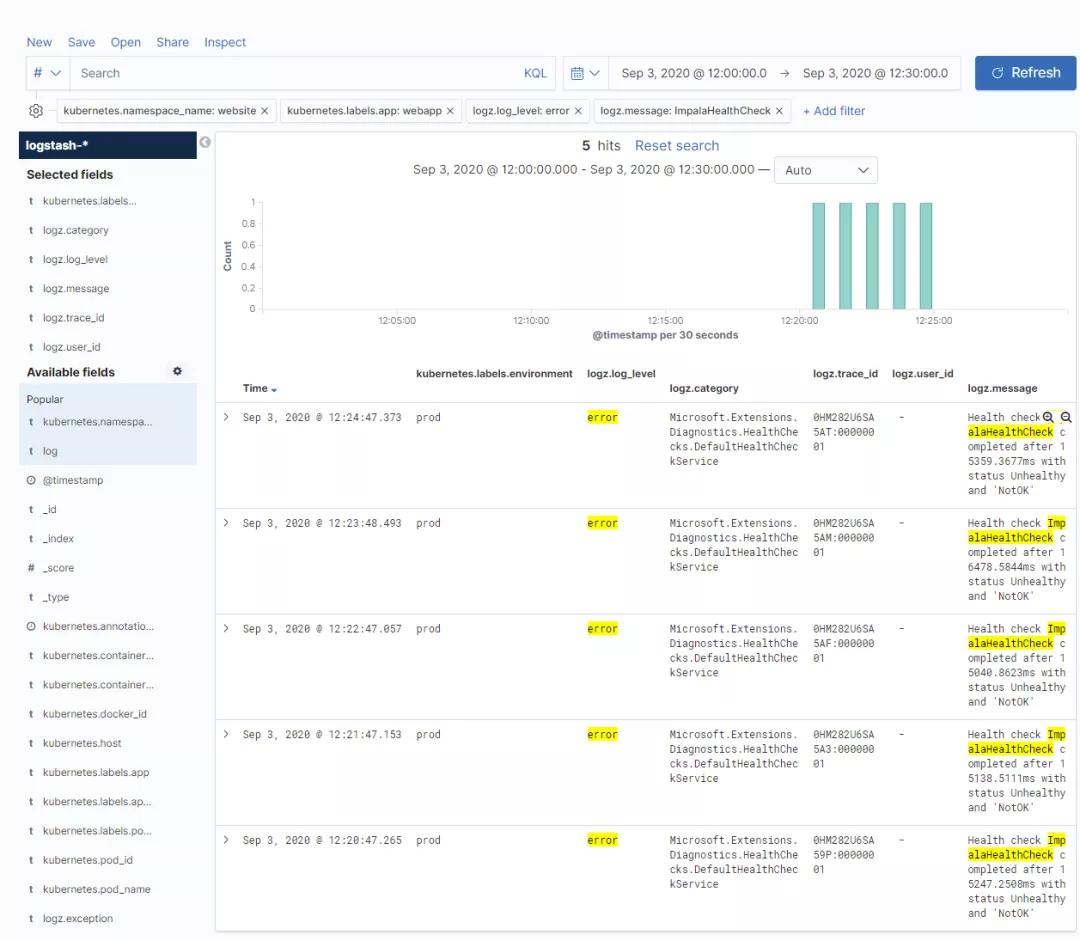
- 基本上每隔2-3天出現一次,每次2-3分鐘,此時整站503;
- 因為不能主動復現,8月26日排查相應時間段的EFK日志: impala連接問題,大數據運維同事排查到webapp發起impala的請求與impala集群時鐘未對齊,導致webapp impalaODBC Driver連不上impala集群;
進入k8s集群節點,確實部分節點的時鐘對齊服務未啟動,不定時出現比北京時間慢2,3分鐘的情況,這個確實可以解釋時間差導致的impala連接認證失敗。
- 8月26日同步所有k8s節點的時鐘,之后接近一周,并未出現問題;
- 9月3日又出現一次短時503無服務,EFK日志顯示依舊是impala連接問題,此處大數據同事未能定位具體原因,暫時定義為偶發/抖動?
3.思考和推演
故障現場每次只有impala連接問題,我也搞不懂impala連接問題竟然會導致webapp service下線。
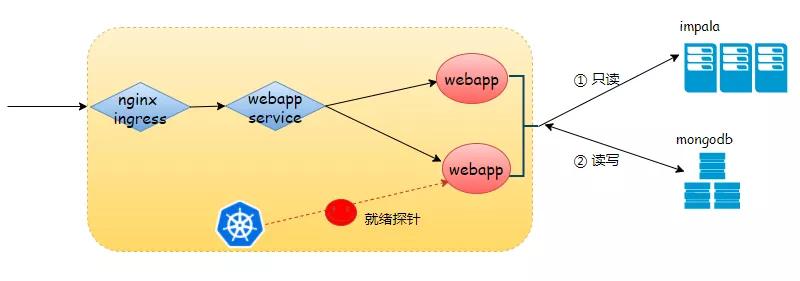
我們的webapp兼具toB和toC業務,站點強依賴mongodb、弱依賴于impala:impala即使連不上,只是不能查,站點sso+訂單相關的寫入操作應該還可用。
回想起前幾天看到的k8s探針,糟糕,我們的就緒探針好像探測了impala
- // ASP.NetCore上暴露的的探測邏輯:impala && mongodb
- services.AddHealthChecks()
- .AddCheck<ImpalaHealthCheck>(nameof(ImpalaHealthCheck), tags: new[] { "readyz" })
- .AddCheck<MongoHealthCheck>(nameof(MongoHealthCheck), tags: new[] { "readyz" });
- app.UseHealthChecks("/readyz", new HealthCheckOptions
- {
- Predicate = (check) => check.Tags.Contains("readyz")
- });
強烈推測:就緒探針3次探測impala失敗, Pod將會被標記為Unready, 該Pod將從webapp服務負載均衡器移除, 不再分配流量,導致nginx無實際意義的后端服務,站點503。
迅速找一個beta環境,斷開impala連接,驗證猜想。

4.問題回顧
bugfix不是我正向推斷出來的,而是純靠經驗推演出來的,倒不是有明確推斷思路,也算給大家提前踩坑了。
docker的健康檢查只能探測,Kubernetes存活、就緒探針不僅有探測,還有決策能力。
這里我們的k8s就緒探測使用策略出現了問題:
探測到webapp弱依賴impala有問題,就下線了整個webapp服務,應該只探測強依賴,強依賴有問題,才表明容器未就緒,這也是就緒探針的初衷。