踩坑記 | Flink Sql Count 還有這種坑!
本文轉載自微信公眾號「大數據羊說」,作者antigeneral了呀。轉載本文請聯系大數據羊說公眾號。
1.序篇
通過本文你可了解到
- 踩坑場景篇-這個坑是啥樣的
- 問題排查篇-坑的排查過程
- 問題原理解析篇-導致問題的機制是什么
- 避坑篇-如何避免這種問題
- 展望篇-有什么機制可以根本避免這種情況
先說下結論:在非窗口類 flink sql 任務中,會存在 retract 機制,即上游會向下游發送「撤回消息(做減法)」,**最新的結果消息(做加法)**兩條消息來計算結果,保證結果正確性。
而如果我們在上下游中間使用了映射類 udf 改變了**撤回消息(做減法)「的一些字段值時,就可能會導致」撤回消息(做減法)**不能被正常處理,最終導致結果的錯誤。
2.踩坑場景篇-這個坑是啥樣的
在介紹坑之前我們先介紹下我們的需求、實現方案的背景。
2.1.背景
在各類游戲中都會有一種場景,一個用戶可以從 A 等級升級到 B 等級,用戶可以不斷的升級,但是一個用戶同一時刻只會在同一個等級。需求指標就是當前分鐘各個等級的用戶數。
2.2.預期效果
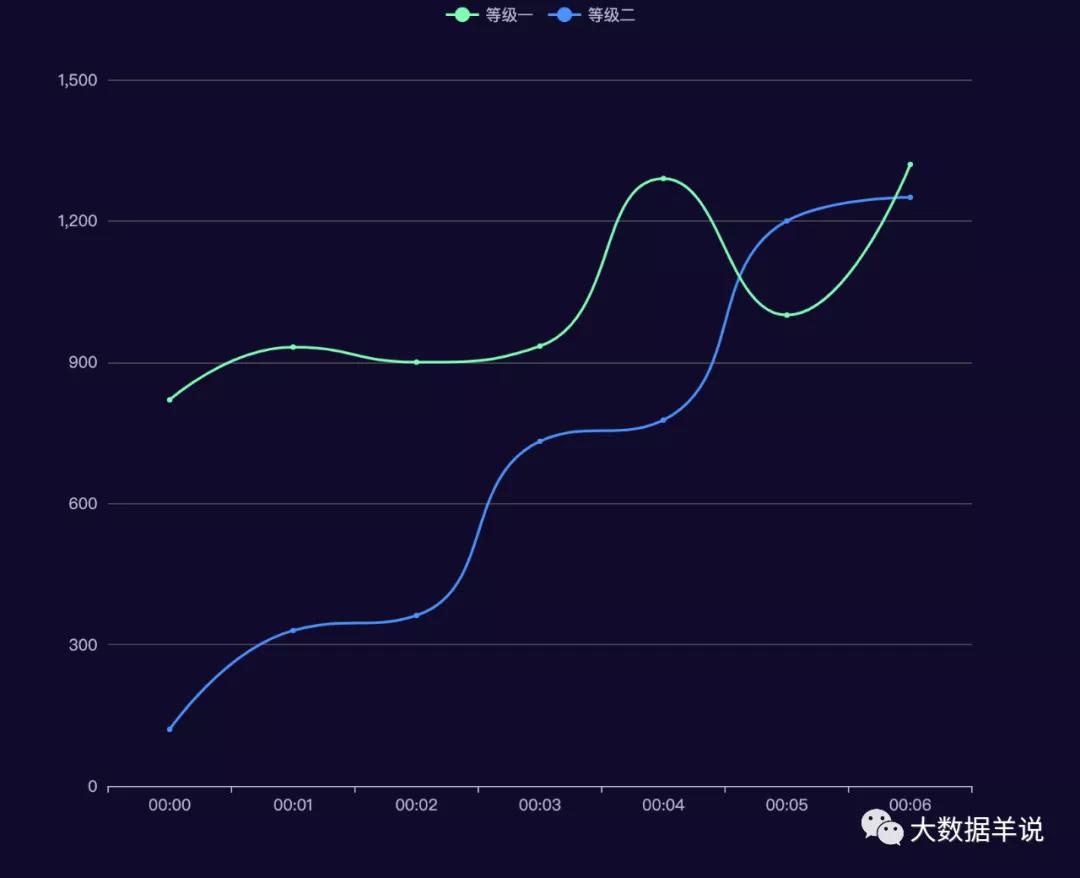
2
2.3.解決思路
獲取到當前所有用戶的最新等級
一個用戶同一時刻只會在一個等級,所以對每一個等級的用戶做 count 操作
2.4.解決方案
獲取到當前所有用戶的最新等級:flink sql row_number() 就可以實現,按照數據的 rowtime 進行逆序排序就可以獲取到用戶當前最新的等級
對每一個等級的用戶做 count 操作:對 row_number() 的后的明細結果進行 count 操作
2.4.1.sql
具體實現 sql 如下,非常簡單:
- WITH detail_tmp AS (
- SELECT
- 等級,
- id,
- `timestamp`
- FROM
- (
- SELECT
- 等級,
- id,
- `timestamp`,
- -- row_number 獲取最新狀態
- row_number() over(
- PARTITION by id
- ORDER BY
- `timestamp` DESC
- ) AS rn
- FROM
- source_db.source_table
- )
- WHERE
- rn = 1
- )
- SELECT
- DIM.中文等級 as 等級,
- sum(part_uv) as uv
- FROM
- (
- SELECT
- 等級,
- count(id) as part_uv
- FROM
- detail_tmp
- GROUP BY
- 等級,
- mod(id, 1024)
- )
- -- 上游數據的等級名稱是數字,需求方要求給轉換成中文,所以這里加了一個 udf 映射
- LEFT JOIN LATERAL TABLE(等級中文映射_UDF(等級)) AS DIM(中文等級) ON TRUE
- GROUP BY
- DIM.中文等級
2.4.2.參數配置
使用 minibatch 參數方式控制數據輸出頻率。
- table.exec.mini-batch.enabled : true
- -- 設定 60s 的觸發間隔
- table.exec.mini-batch.allow-latency : 60s
- table.exec.mini-batch.size : 10000000000
任務 plan。
1
2.5.問題場景
這段 SQL 跑了 n 年都沒有問題,但是有一天運營在配置【等級中文映射_UDF】時,不小心將一個等級的中文名給映射錯了,雖然馬上恢復了,但是當天的實時數據和離線數據對比后卻發現,實時產出的數值比離線大很多!!!而之前都是保持一致的。
3.問題排查篇-坑的排查過程
首先我們想一下,這個指標是算 uv 的,運營將等級中文名配置錯了,也應該是把原有等級的最終結果算少啊,怎么會算多呢???
然后我們將場景復現了下,來看看代碼:
任務代碼,大家可以直接 copy 到本地運行:
- public class Test {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
- EnvironmentSettings settings = EnvironmentSettings
- .newInstance()
- .useBlinkPlanner()
- .inStreamingMode().build();
- StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
- // 模擬輸入
- DataStream<Tuple3<String, Long, Long>> tuple3DataStream =
- env.fromCollection(Arrays.asList(
- Tuple3.of("2", 1L, 1627218000000L),
- Tuple3.of("2", 101L, 1627218000000L + 6000L),
- Tuple3.of("2", 201L, 1627218000000L + 7000L),
- Tuple3.of("2", 301L, 1627218000000L + 7000L)));
- // 分桶取模 udf
- tEnv.registerFunction("mod", new Mod_UDF());
- // 中文映射 udf
- tEnv.registerFunction("status_mapper", new StatusMapper_UDF());
- tEnv.createTemporaryView("source_db.source_table", tuple3DataStream,
- "status, id, timestamp");
- String sql = "WITH detail_tmp AS (\n"
- + " SELECT\n"
- + " status,\n"
- + " id,\n"
- + " `timestamp`\n"
- + " FROM\n"
- + " (\n"
- + " SELECT\n"
- + " status,\n"
- + " id,\n"
- + " `timestamp`,\n"
- + " row_number() over(\n"
- + " PARTITION by id\n"
- + " ORDER BY\n"
- + " `timestamp` DESC\n"
- + " ) AS rn\n"
- + " FROM source_db.source_table"
- + " )\n"
- + " WHERE\n"
- + " rn = 1\n"
- + ")\n"
- + "SELECT\n"
- + " DIM.status_new as status,\n"
- + " sum(part_uv) as uv\n"
- + "FROM\n"
- + " (\n"
- + " SELECT\n"
- + " status,\n"
- + " count(distinct id) as part_uv\n"
- + " FROM\n"
- + " detail_tmp\n"
- + " GROUP BY\n"
- + " status,\n"
- + " mod(id, 100)\n"
- + " )\n"
- + "LEFT JOIN LATERAL TABLE(status_mapper(status)) AS DIM(status_new) ON TRUE\n"
- + "GROUP BY\n"
- + " DIM.status_new";
- Table result = tEnv.sqlQuery(sql);
- tEnv.toRetractStream(result, Row.class).print();
- env.execute();
- }
- }
UDF 代碼:
- public class StatusMapper_UDF extends TableFunction<String> {
- public void eval(String status) {
- if (status.equals("1")) {
- collector.collect("等級1");
- } else if (status.equals("2")) {
- collector.collect("等級2");
- } else if (status.equals("3")) {
- collector.collect("等級3");
- }
- }
- }
在正確情況(模擬 UDF 沒有任何變動的情況下)的輸出結果:
- (true,等級2,1)
- (false,等級2,1)
- (true,等級2,2)
- (false,等級2,2)
- (true,等級2,3)
- (false,等級2,3)
- (true,等級2,4)
最終等級2 的 uv 數為 4,結果復合預期?。
模擬下用戶修改了 udf 配置之后,UDF 代碼如下:
- public class StatusMapper_UDF extends TableFunction<String> {
- private int i = 0;
- public void eval(String status) {
- if (i == 5) {
- collect("等級4");
- } else {
- if ("1".equals(status)) {
- collector.collect("等級1");
- } else if ("2".equals(status)) {
- collector.collect("等級2");
- } else if ("3".equals(status)) {
- collector.collect("等級3");
- }
- }
- i++;
- }
- }
得到的結果如下:
- (true,等級2,1)
- (false,等級2,1)
- (true,等級2,2)
- (false,等級2,2)
- (true,等級2,3)
- (false,等級2,3)
- (true,等級2,7)
最終等級2 的 uv 數為 7,很明顯這是錯誤結果?。
因此可以確定是由于這個 UDF 的處理邏輯變換而導致的結果出現錯誤。
下文就讓我們來分析下其中緣由。
問題原理解析篇-導致問題的機制是什么
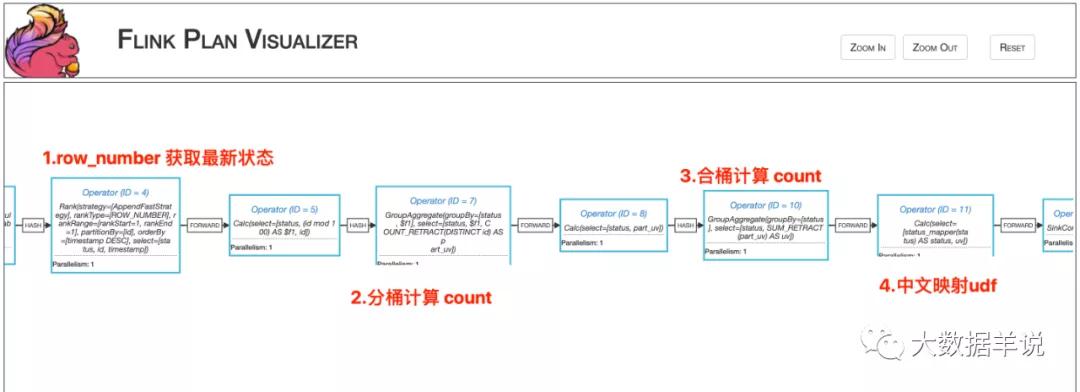
我們首先來分析下上述 SQL,可以發現整個 flink sql 任務是使用了 unbounded + minibatch 實現的,在 minibatch 觸發條件觸發時,上游算子會將之前的結果撤回,然后將最新的結果發出。
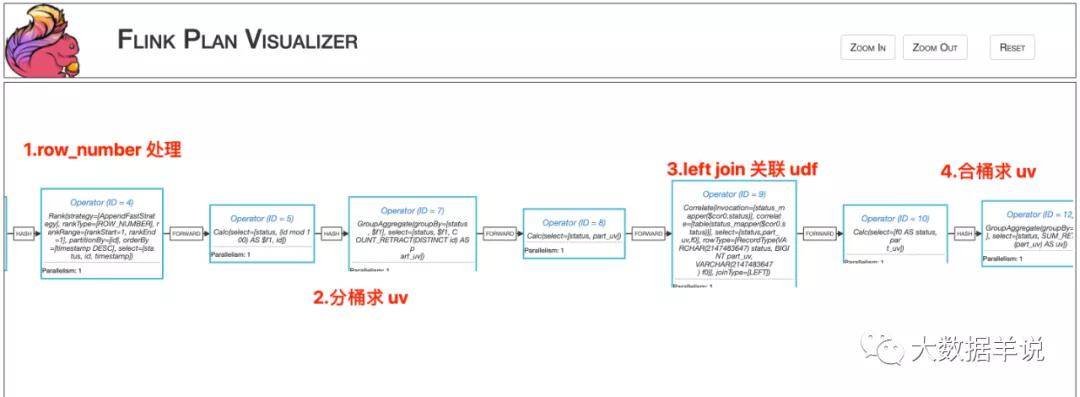
這個任務的 execution plan 如圖所示。
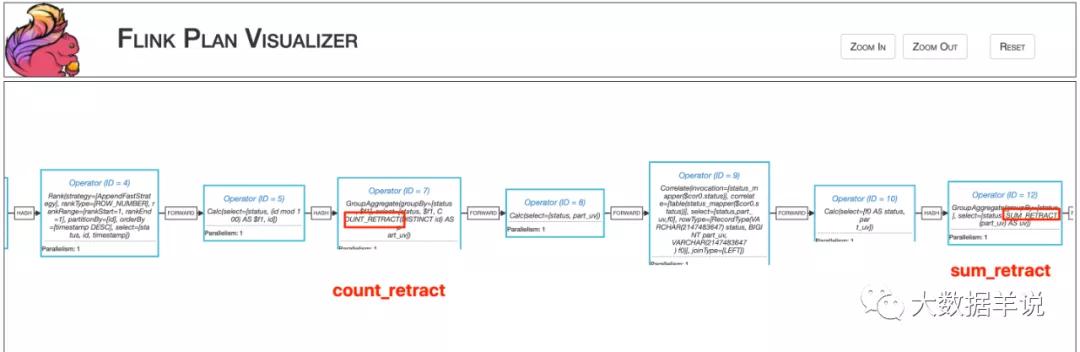
7
可以從算子圖中的一些計算邏輯可以看到,整個任務都是基于 retract 機制運行(count_retract、sum_retract 等)。
而涉及到 udf 的核心邏輯是在 Operator(ID = 7),和 Operator(ID = 12) 之間。當 Operator(ID = 7) GroupAggregate 結果發生改變之后,會發一條「撤回消息(做減法)」,一條**最新的結果消息(做加法)**到 Operator(ID = 12) GroupAggregate。
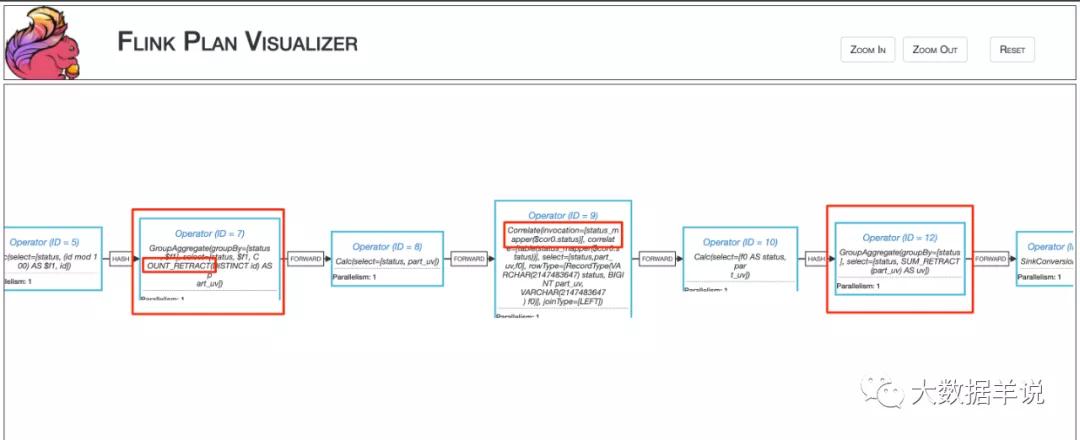
5
Notes:簡單解釋下上面說的「撤回消息(做減法)」,「最新的結果消息(做加法)」。舉個算 count 的例子:當整個任務的第一條數據來之后,之前沒有數據,所以不用撤回,結果就是 0(沒有數據) + 1(第一條數據) = 1(結果),當第二條結果來之后,就要將上次發的 1 消息(可以理解為是整個任務的一個中間結果)撤回,將最新的結果 2 發下去。那么計算方法就是 1(上次的結果) - 1(撤回) + 2(當前最新的結果消息)= 2(結果)。
通過算子圖可以發現,【中文名稱映射】UDF 是處于兩個 GroupAggregate 之間的。也就是說 Operator(ID = 7) GroupAggregate 發出的「撤回消息(做減法)」,**最新的結果消息(做加法)「都會執行這個 UDF,那么就有可能」撤回消息(做減法)「中的某個作為下游 GroupAggregate 算子 key 的字段會被更改成其他值,那么這條消息就不會發到原來下游 GroupAggregate 算子的原始 key 中,那么原來的 key 的歷史結果就撤回不了了。。。但是」最新的結果消息(做加法)**的字段沒有被更改時,那么這個消息依然被發到了下游 GroupAggregate 算子,這就會導致沒做減法,卻做了加法,就會導致結果增加,如下圖所示。
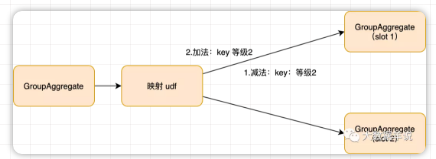
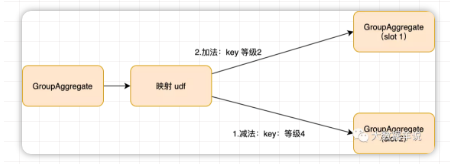
從這個角度出發,我們來分析下上面的 case,從內層發給外層的消息一條一條來分析。
內層消息怎么來看呢?其實就是將上面的 SQL 中的 left join 刪除,重新跑一遍就可以得到結果,結果如下:
- (true,等級2,1)
- (false,等級2,1)
- (true,等級2,2)
- (false,等級2,2)
- (true,等級2,3)
- (false,等級4,3)
- (true,等級2,4)
來分析下內層消息發出之后對應到外層消息的操作:
| 內層 | 外層 |
|---|---|
| (true,等級2,1) | (true,等級2,1) |
| (false,等級2,1) | (false,等級2,1) |
| (true,等級2,2) | (true,等級2,2) |
| (false,等級2,2) | (false,等級2,2) |
| (true,等級2,3) | (true,等級2,3) |
前五條消息不會導致錯誤,不用詳細說明。
| 內層 | 外層 |
|---|---|
| (true,等級2,1) | (true,等級2,1) |
| (false,等級2,1) | (false,等級2,1) |
| (true,等級2,2) | (true,等級2,2) |
| (false,等級2,2) | (false,等級2,2) |
| (true,等級2,3) | (true,等級2,3) |
| (false,等級4,3) |
第六條消息發出之后,經過 udf 的處理之后,中文名被映射成了【等級4】,而其再通過 hash partition 策略向下發送消息時,就不能將這條撤回消息發到原本 key 為【等級2】的算子中了,這條撤回消息也無法被處理了。
| 內層 | 外層 |
|---|---|
| (true,等級2,1) | (true,等級2,1) |
| (false,等級2,1) | (false,等級2,1) |
| (true,等級2,2) | (true,等級2,2) |
| (false,等級2,2) | (false,等級2,2) |
| (true,等級2,3) | (true,等級2,3) |
| (false,等級4,3) | |
| (true,等級2,4) | (false,等級2,3) (true,等級2,7) |
第七條消息 (true,等級2,4) 發出后,外層 GroupAggregate 算子首先會將上次發出的記過撤回,即(false,等級2,3),然后將(true,等級2,4)累加到當前的記過上,即 3(上次結果)+ 4(這次最新的結果)= 7(結果)。就導致了上述的錯誤結果。
定位到問題原因之后,我們來看看怎么避免上述錯誤。
6.避坑篇-如何避免這種問題
6.1.從源頭避免
udf 這種映射維度的 udf 盡量在上線前就固定下來,避免后續更改造成的數據錯誤。
6.2.替換為 ScalarFunction 進行映射
- WITH detail_tmp AS (
- SELECT
- status,
- id,
- `timestamp`
- FROM
- (
- SELECT
- status,
- id,
- `timestamp`,
- row_number() over(
- PARTITION by id
- ORDER BY
- `timestamp` DESC
- ) AS rn
- FROM
- (
- SELECT
- status,
- id,
- `timestamp`
- FROM
- source_db.source_table
- ) t1
- ) t2
- WHERE
- rn = 1
- )
- SELECT
- -- 在此處進行中文名稱映射
- 等級中文映射_UDF(status) as status,
- sum(part_uv) as uv
- FROM
- (
- SELECT
- status,
- count(distinct id) as part_uv
- FROM
- detail_tmp
- GROUP BY
- status,
- mod(id, 100)
- )
- GROUP BY
- status
還是剛剛的邏輯,剛剛的配方,我們先來看一下結果。
- public class StatusMapper_UDF extends ScalarFunction {
- private int i = 0;
- public String eval(String status) {
- if (i == 5) {
- i++;
- return "等級4";
- } else {
- i++;
- if ("1".equals(status)) {
- return "等級1";
- } else if ("2".equals(status)) {
- return "等級2";
- } else if ("3".equals(status)) {
- return "等級3";
- }
- }
- return "未知";
- }
- }
發現雖然依然會有 (false,等級4,3) 這樣的錯誤撤回數據(這是 udf 決定的,沒法避免),但是我們可以發現最終的結果是 (true,等級2,4),結果依然是正確的。
再來分析下問什么這種方式可以解決,如圖 plan。
6
發現映射 udf 算子所處的位置不在兩個 GroupAggregrate 之間了,因此在 retract 消息發送之后,不會被映射到錯誤其他 key 中,因此所有的 retract 消息都會正常處理。
7.展望篇-有什么機制可以根本避免這種情況
可以將「撤回消息(做減法)」,**最新的結果消息(做加法)**做成一個原子消息從上游發給下游,下游統一進行原子性處理,關聯 udf 時,也只對 group key 關聯一次即可。