架構師不會架構選型,能行嗎?
如果你在做選型方面的工作,或者想了解一些現在正在流行的技術,那么這篇文章正好適合你。
圖片來自 Pexels
本篇內容涵蓋 14 個方面,涉及上百個框架和工具。會有你喜歡的,大概也會有你所討厭的家伙。
這是我平常工作中打交道最多的工具,大小公司都適用。如果你有更好的,歡迎留言補充:
- 消息隊列
- 緩存
- 分庫分表
- 數據同步
- 通訊
- 微服務
- 分布式工具
- 監控系統
- 調度
- 入口工具
- OLT(A)P
- CI/CD
- 問題排查
- 本地工具
消息隊列
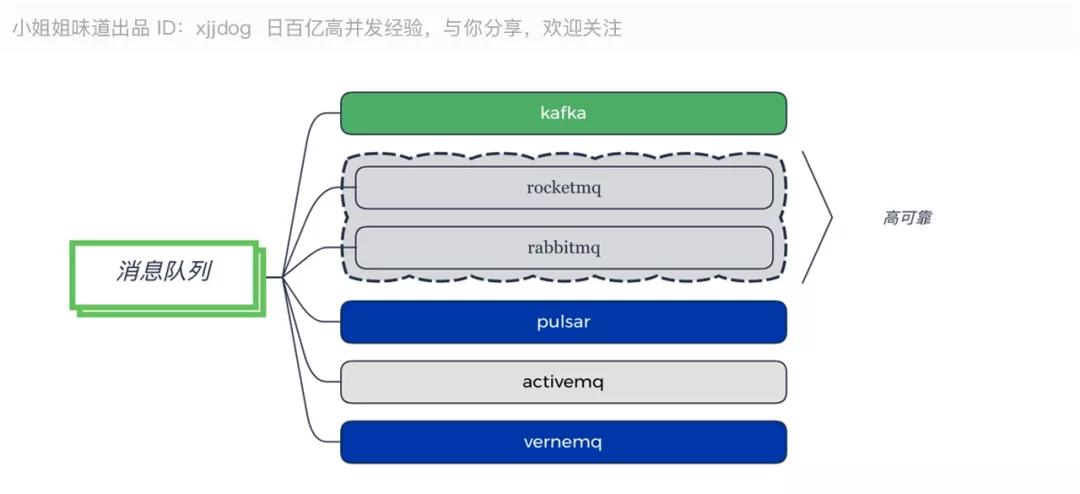
推薦:
- 吞吐量優先選擇 Kafka。
- 穩定性優先選擇 RocketMQ。
- 物聯網:VerneMQ。
一個大型的分布式系統,通常都會異步化,走消息總線。 消息隊列作為最主要的基礎組件,在整個體系架構中,有著及其重要的作用。異步通常意味著編程模型的改變,時效性會降低。
Kafka 是目前最常用的消息隊列,尤其是在大數據方面,有著極高的吞吐量。而 RocketMQ和 RabbitMQ,都是電信級別的消息隊列,在業務上用的比較多。
相比較而言,ActiveMQ 使用的最少,屬于較老一代的消息框架。Pulsar 是為了解決一些 Kafka 上的問題而誕生的消息系統,比較年輕,工具鏈有限。有些激進的團隊經過試用,反響不錯,但實際使用并不多。
MQTT 具體來說是一種協議,主要用在物聯網方面,能夠雙向通信,屬于消息隊列范疇,推薦使用 VerneMQ。
緩存
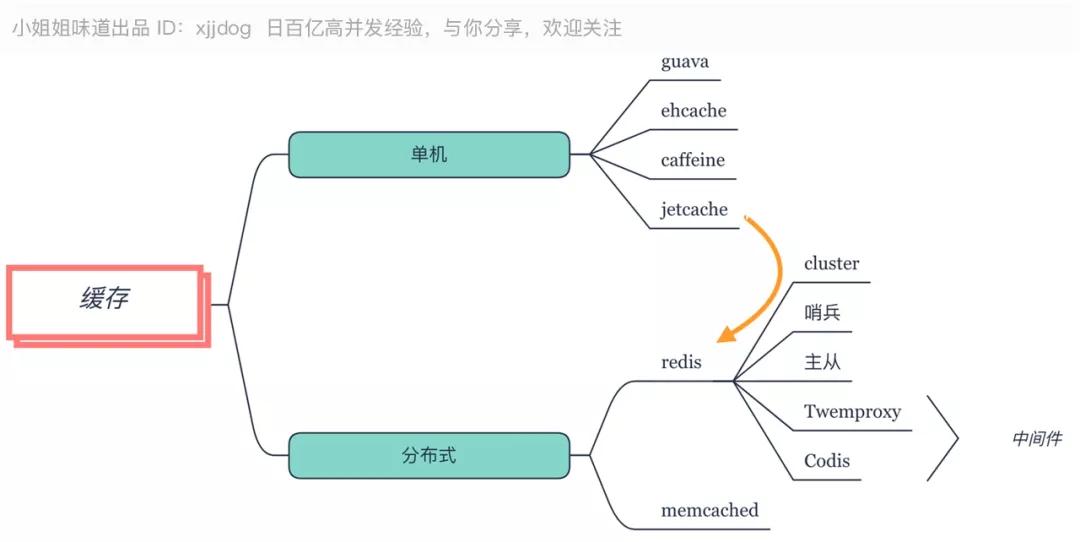
推薦:
- 堆內緩存使用默認的 Caffeine。
- 分布式緩存采用 Redis 的 Cluster 集群模式,但要注意使用限制。
數據緩存是減少數據庫壓力的有效途徑,有單機 Java 內緩存,和分布式緩存之分。
對于單機來說,Guava 的 LoadingCache 和 ehcache 都是些熟面孔,不過 SpringBoot 選擇了 Caffeine 作為它的默認堆內緩存,這是因為 Caffeine 的速度比較快的原因。
對于分布式緩存來說,優先選擇的就是 Redis,別猶豫。由于 Redis 是單線程的(6.0 支持多線程,但默認不開啟),并不適合高耗時操作。
所以對于一些數據量比較大的緩存,比如圖片、視頻等,使用老牌的 Memcached 效果會好的多。
JetCache 是一個基于 Java 的緩存系統封裝,提供統一的 API 和注解來簡化緩存的使用。類似 SpringCache,支持本地緩存和分布式緩存,也是簡化開發的利器。
分庫分表
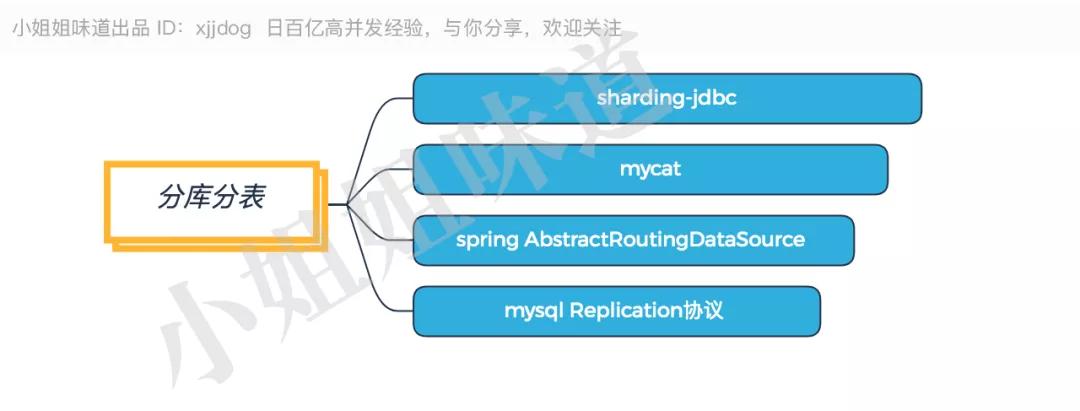
推薦:ShardingSphere 中的 Sharding-JDBC。
分庫分表,幾乎每一個上點規模的公司,都會有自己的方案。目前,推薦使用驅動層的 Sharding-JDBC(已經進入 Apache),或者代理層的 Mycat。如果你沒有額外的運維團隊,又不想花錢買其他機器,那么就選前者。
如果分庫分表涉及的項目不多,Spring 的動態數據源是一個非常好的選擇。它直接編碼在代碼里,直觀但不易擴展。
如果只需要讀寫分離 ,那么 MySQL 官方驅動里的 Replication 協議,是更加輕量級的選擇。
上面的分庫分表組件,都是大浪淘沙,最終的優勝品。這些組件不同于其他組件選型,方案一旦確定,幾乎無法回退,所以要慎之又慎。
分庫分表是小 Case,準備分庫分表的階段,才是重點:也就是數據同步。
數據同步
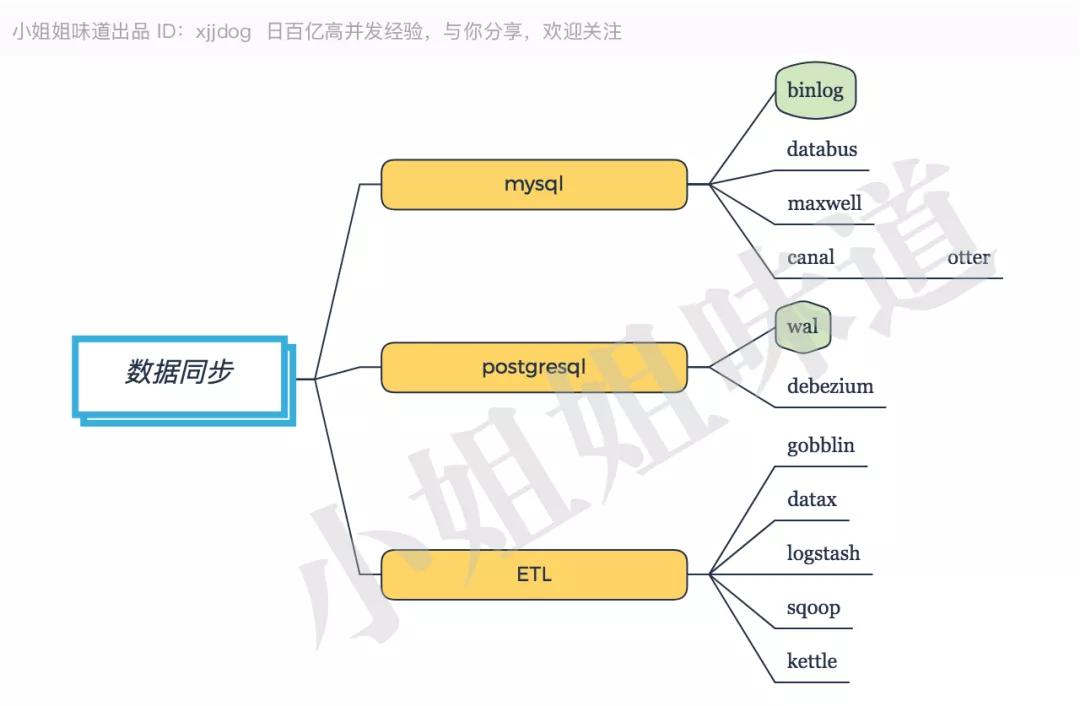
推薦:Canal。
國內使用 MySQL 的公司居多,但 PostgreSQL 憑借其優異的性能,使用率逐漸攀升。
不管什么數據庫,實時數據同步工具,都是把自己模擬成一個從庫,進行數據拉取和解析。
具體來說,MySQL 是通過 Binlog 進行同步;PostgreSQL 使用 Wal 日志進行同步。
對 MySQL 來說,Canal 是國內用的最多的方案;類似的 Databus 也是比較好用的工具。
現在,Canal、Maxwell 等工具,都支持將要同步的數據寫入到 MQ 中,進行后續處理,方便了很多。
對于 ETL(抽取、清洗、轉換)來說,基本上都是 Source、Task、Sink 路線,與前面的功能對應。Gobblin、Datax、Logstash、Sqoop 等,都是這樣的工具。
它們的主要工作,就是怎么方便的定義配置文件,編寫各種各樣的數據源適配接口等。
這些 ETL 工具,也可以作為數據同步(尤其是全量同步)的工具,通常是根據 ID,或者最后更新時間 等,進行處理。
Binlog 是實時增量工具,ETL 工具做輔助。通常一個數據同步功能,需要多個組件的參與,他們共同組成一個整體。
通訊
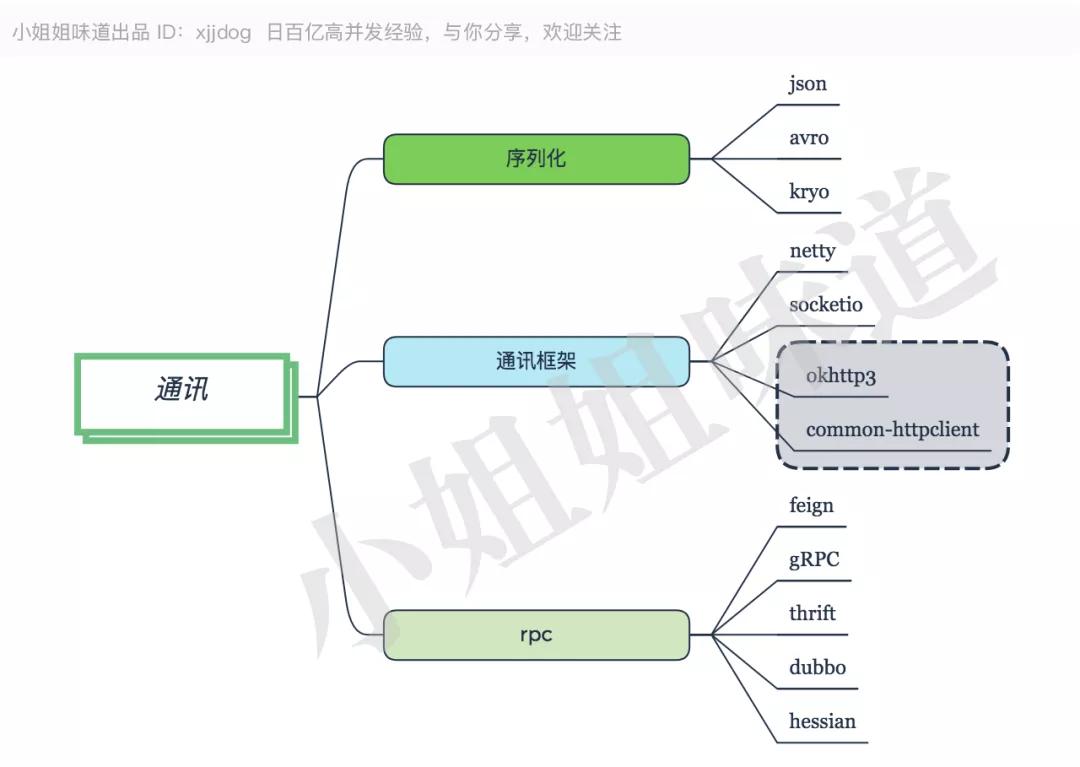
推薦:HTTP+Json,方便調試。高性能要求可選二進制協議。
Java 中,Netty 已經成為當之無愧的網絡開發框架,包括其上的 socketio(不要再和我提 mina 了)。
對于 HTTP 協議,有 common-httpclient,以及更加輕量級的工具 Okhttp 來支持。
對于一個 RPC 來說,要約定一個通訊方式和序列化方式。Json 是最常用的序列化方式,但是傳輸和解析成本大,XML 等文本協議與其類似,都有很多冗余的信息;Avro 和 Kryo 是二進制的序列化工具,沒有這些缺點,但調試不便。
RPC 是遠程過程調用的意思 ,其中,Thrift、Dubbo、gRPC 默認都是二進制序列化方式的 Socket 通訊框架;Feign、Hessian 都是 Onhttp 的遠程調用框架。
對了,gRPC 的序列化工具是 Protobuf,一個壓縮比很高的二進制序列化工具。
通常,服務的響應時間主要耗費在業務邏輯以及數據庫上,通訊層耗時在其中的占比很小。可以根據自己公司的研發水平和業務規模來選擇。
微服務
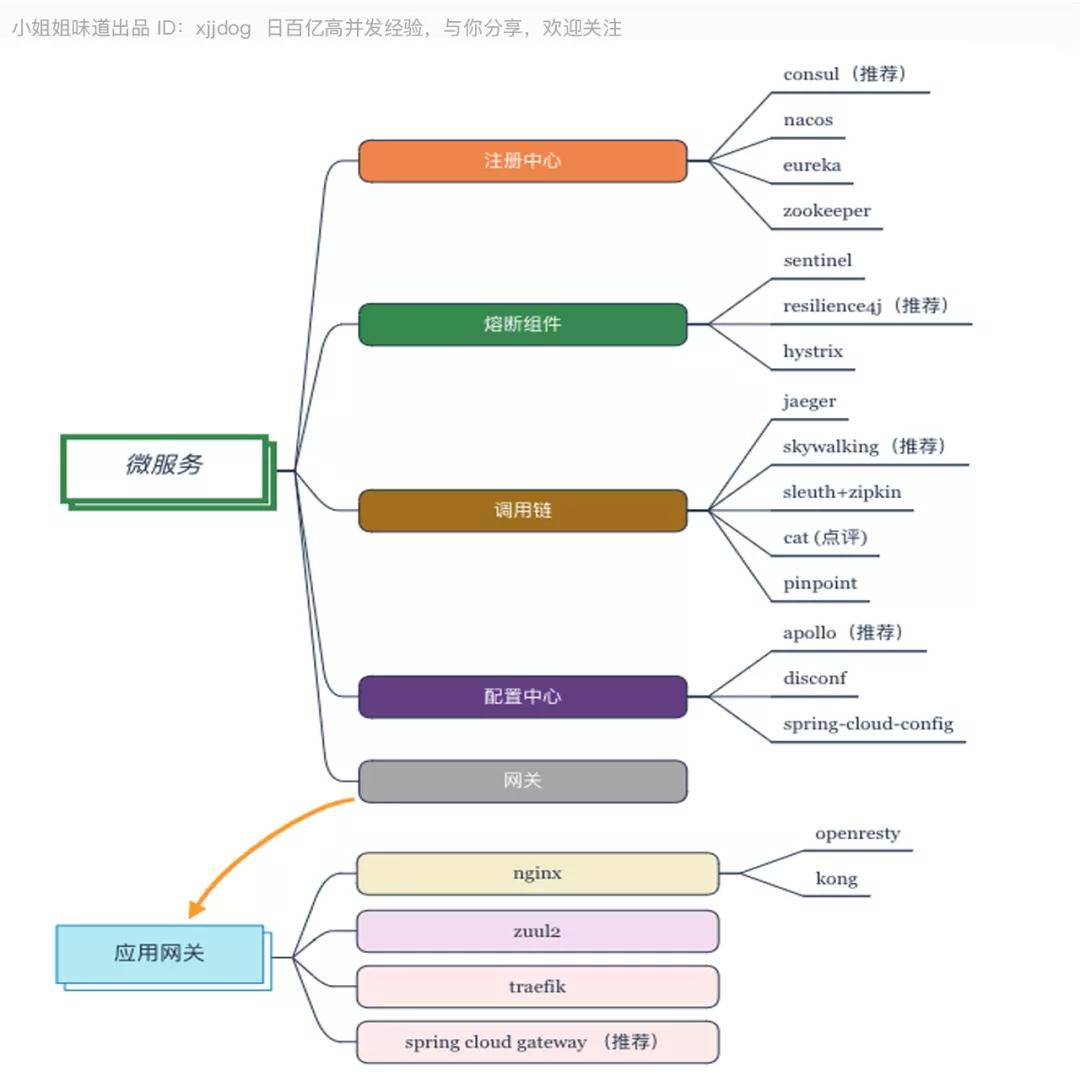
推薦:
- 注冊中心:Consul。
- 網關:Nginx+Gateway。
- 配置中心:Apollo。
- 調用鏈:Skywalking。
- 熔斷:Resilience4j。
我們不止一次說到微服務,這一次我們從圍繞它的一堆支持框架,來窺探一下這個體系。是的,這里依然是在說 Spring Cloud。
默認的注冊中心 Eureka 不再維護,Consul 已經成為首選,它使用 Raft 協議開發開箱即用。Nacos、Zookeeper 等,都可以作為備選方案。其中 Nacos 帶有后臺,比較適合國人使用習慣。
熔斷組件,官方的 Hystrix 也已經不維護了。推薦使用 Resilience4j,最近阿里的 Sentinel 也表現強勁。
對于調用鏈來說,由于 OpenTracing 的興起,有了很多新的面孔。推薦使用 Jaeger 或者 Skywalking。Spring Cloud 集成的 Sleuth+Zipkin 功能稍弱,甚至不如傳統侵入式的 Cat。
配置中心是管理多環境配置文件的利器,尤其在你不想重啟服務器的情況下進行配置更新。
目前,開源中做的最好的要數 Apollo,并提供了對 Spring Boot 的支持。
Disconf 使用也較為廣泛。相對來說,Spring Cloud Config 功能就局限了些,用的很少。
網關方面,使用最多的就是 Nginx,在 Nginx 之上,有基于 Lua 腳本的 Openrestry。由于 Openresty 的使用非常繁雜,所以有了 Kong 這種封裝級別更高的網關。
對于 Spring Cloud 來說,Zuul 系列推薦使用 Zuul2,Zuul1 是多線程阻塞的,有硬傷。
Spring-Cloud-Gateway 是 Spring Cloud 親生的,Spring Cloud 大力支持,基于 Spring 5.0 的新特性 WebFlux 進行開發。底層網絡通信框架采用的是 Netty,吞吐量高。
分布式工具

大家都知道分布式系統 Zookeeper 能用在很多場景,與其類似的還有基于 Raft 協議的 etcd 和 Consul。
由于它們能夠保證極高的一致性,所以用作協調工具是再好不過了。用途集中在:配置中心、分布式鎖、命名服務、分布式協調、Master 選舉等場所。
對于分布式事務方面,則有阿里的 Fescar 工具進行支持。但如非特別的必要,還是使用柔性事務,追尋最終一致性,比較好。
監控系統
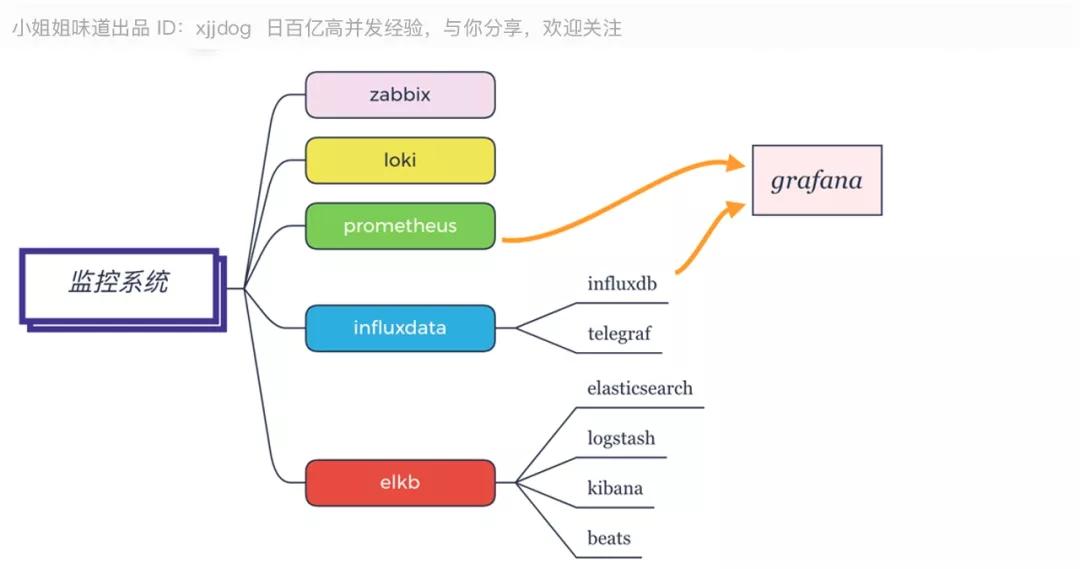
推薦:
- Prometheus+Grafana+Telegraf。
- 日志收集:大量 ELKB,小量 Loki。
監控系統組件種類繁多,目前,最流行的大概就是上面四類。Zabbix 在主機數量不多的情況下,是非常好的選擇。
Prometheus 來勢兇猛,大有一統天下的架勢。它也可以使用更加漂亮的 Grafana 進行前端展示。
Influxdata 的 Influxdb 和 Telegraf 組件,都比較好用,主要是功能很全。使用 ES 存儲的 ELKB 工具鏈,也是一個較好的選擇。我所知道的很多公司,都在用。
調度

推薦:XXL-Job。
大家可能都用過 Cron 表達式。這個表達式,最初就是來自 Linux 的 Crontab 工具。
Quartz 是 Java 中比較古老的調度方案,分布式調度采用數據庫鎖的方式,管理界面需要自行開發。
Elastic-Job-Cloud 應用比較廣泛,但系統運維復雜,學習成本較高。相對來說,XXL-Job 就更加輕量級一些。中國人開發的系統,后臺都比較漂亮。
入口工具
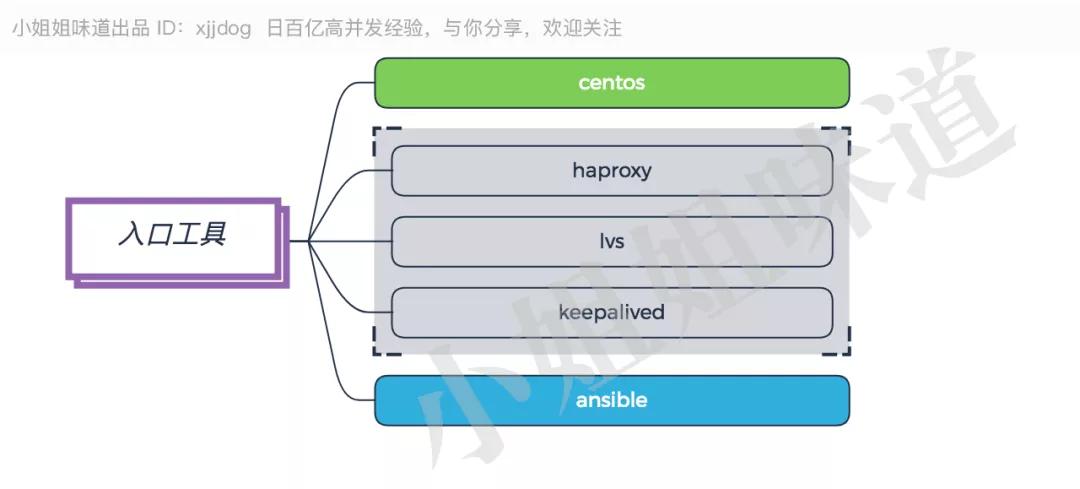
推薦:LVS。
為了統一用戶的訪問路口,一般會使用一些入口工具進行支持。其中,Haproxy、LVS、Keepalived 等,使用非常廣泛。
服務器一般采用穩定性較好的 Centos,并配備 Ansible 工具進行支持,那叫一個爽。
OLT(A)P
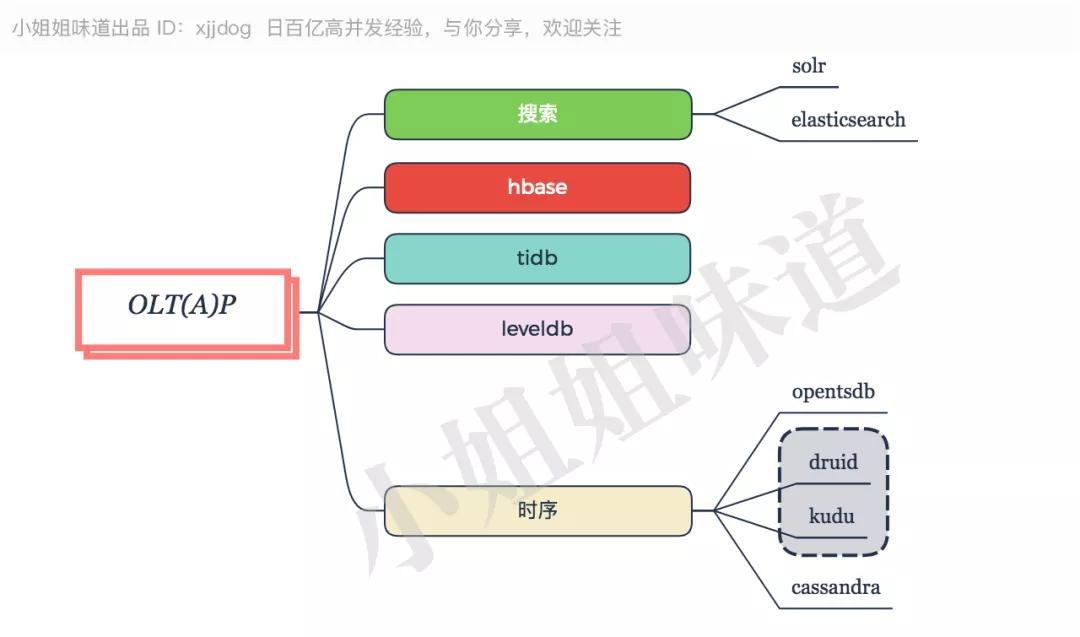
推薦:ES。
現在的企業,數據量都非常大,數據倉庫是必須的。搜索方面,Solr 和 Elasticsearch 比較流行,它們都是基于 Lucene 的。Solr 比較成熟,穩定性更好一些,但實時搜索方面不如 ES。
列式存儲方面,基于 Hadoop 的 Hbase,使用最是廣泛;基于 LSM 的 LevelDB 寫入性能優越,但目前主要是作為嵌入式引擎使用多一些。
TiDB 是國產新貴,兼容 MySQL 協議,公司通過培訓向外輸出 DBA,未來可期。
時序數據庫方面,OpentsDB 用在超大型監控系統多一些。Druid 和 Kudu,在處理多維度數據實時聚合方面,更勝一籌。
Cassandra在剛出現時火了一段時間,雖然有 Facebook 棄用的新聞,但生態已經形成,常年霸占數據庫引擎前 15 名。
CI/CD
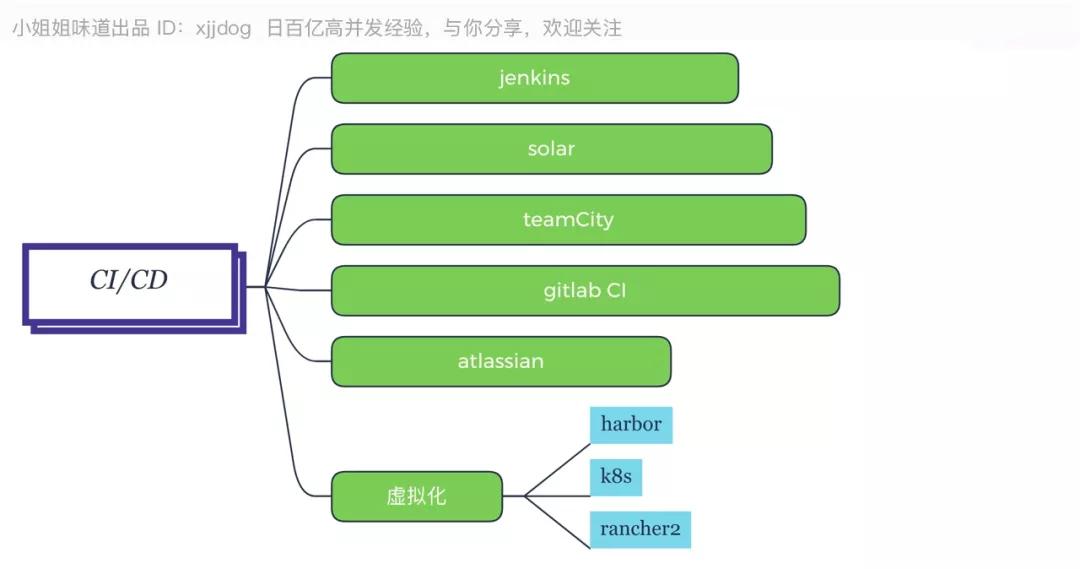
為了支持持續集成和虛擬化,除了耳熟能詳的 Docker,我們還有其他工具。
Jenkins 是打包發布的首選,畢竟這么多年了,一直是老大哥。當然,寫 Idea 的那家公司,還出了一個叫 TeamCity 的工具,操作界面非常流暢。
Solor 不得不說是一個神器,用了它之后,小伙伴們的代碼一片飄紅,我都快被吐沫星子給淹沒了。
對于公司內部來說,一般使用 Gitlab 搭建 Git 服務器。其實,它里面的 Gitlab CI,也是非常好用的。
Harbor,在 Docker Registry 基礎上擴展了權限控制,審計,鏡像同步,管理界面等治理 能力,推薦使用。
調度方面,K8s,Google 開源,社區的強力推動,有大量的落地方案。
Rancher 對 K8s 進行了功能的拓展,實現了和 K8s 集群交互的一些便捷工具,包括執行命令行,管理多個 K8s 集群,查看 K8s 集群節點的運行狀態等,推薦集成。
問題排查

Java 經常發生內存溢出問題。使用 Jmap 導出堆棧后,我一般使用 Mat 進行深入分析。
如果在線上實時分析,有 Arthas 和 Perf 兩款工具。當然,有大批量的 Linux 工具進行支持。
本地工具
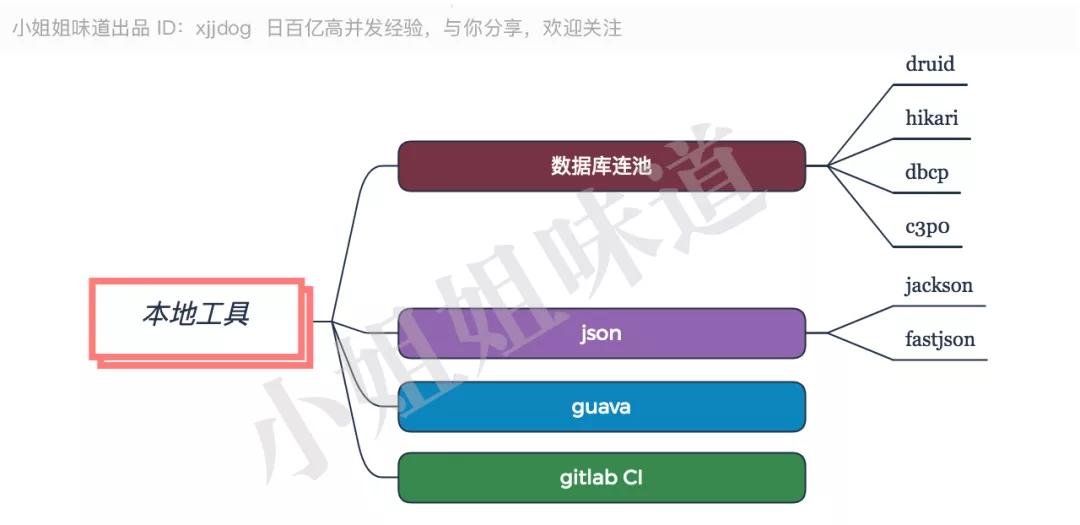
本地使用的 jar 包和工具,那就多了去了。下面僅僅提一下最最常用的幾個。
數據庫連接池方面,國內使用 Druid 最多。目前,有號稱速度最快的 Hikari 數據庫連接池,以及老掉牙的 dbcp 和 c3p0。
Json 方面,國內使用 Fastjson 最多,三天兩頭冒出個漏洞;國外則使用 Jackson 多一些。
它們的 API 都類似,Jackson 特性多一些,但 Fastjson 更加容易使用。工具包方面,雖然有各種 Commons 包,Guava 首選。
總結
架構選型,除了你本身對某項技術比較熟悉,用起來更放心。更多的是需要進行大量調研、對比,直到掌握。
技術日新月異,新瓶裝舊酒,名詞一籮筐,程序員很辛苦。唯有那背后的基礎原理,大道至簡的思想,經久不衰。
作者:小姐姐味道
簡介:一個不允許程序員走彎路的公眾號。聚焦基礎架構和 Linux。十年架構,日百億流量,與你探討高并發世界,給你不一樣的味道。
編輯:陶家龍
出處:轉載自公眾號小姐姐味道(ID:xjjdog)