













one-hot encoding不是萬能的,這些分類變量編碼方法你值得擁有
one-hot encoding 是一種被廣泛使用的編碼方法,但也會造成維度過高等問題。因此,medium 的一位博主表示,在編碼分類變量方面,我們或許還有更好的選擇。
one-hot 編碼(one-hot encoding)類似于虛擬變量(dummy variables),是一種將分類變量轉(zhuǎn)換為幾個二進制列的方法。其中 1 代表某個輸入屬于該類別。
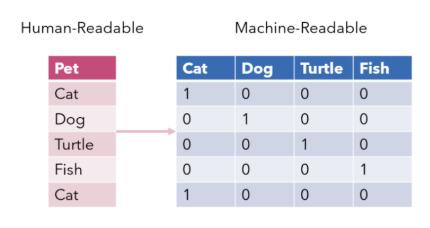
從機器學(xué)習(xí)的角度來看,one-hot 編碼并不是一種良好的分類變量編碼方法。
眾所周知,維數(shù)越少越好,但 one-hot 編碼卻增加了大量的維度。例如,如果用一個序列來表示美國的各個州,那么 one-hot 編碼會帶來 50 多個維度。
one-hot 編碼不僅會為數(shù)據(jù)集增加大量維度,而且實際上并沒有太多信息,很多時候 1 散落在眾多零之中,即有用的信息零散地分布在大量數(shù)據(jù)中。這會導(dǎo)致結(jié)果異常稀疏,使其難以進行優(yōu)化,對于神經(jīng)網(wǎng)絡(luò)來說尤其如此。
更糟糕的是,每個信息稀疏列之間都具有線性關(guān)系。這意味著一個變量可以很容易地使用其他變量進行預(yù)測,導(dǎo)致高維度中出現(xiàn)并行性和多重共線性的問題。

最優(yōu)數(shù)據(jù)集由信息具有獨立價值的特征組成,但 one-hot 編碼創(chuàng)建了一個完全不同的環(huán)境。
當然,如果只有三、四個類,那么 one-hot 編碼可能不是一個糟糕的選擇。但是隨著類別的增加,可能還有其他更合適的方案值得探索。本文作者列舉了幾個方案供讀者參考。
目標編碼
目標編碼(Target encoding)是表示分類列的一種非常有效的方法,并且僅占用一個特征空間,也稱為均值編碼。該列中的每個值都被該類別的平均目標值替代。這可以更直接地表示分類變量和目標變量之間的關(guān)系,并且也是一種很受歡迎的技術(shù)方法(尤其是在 Kaggle 比賽中)。
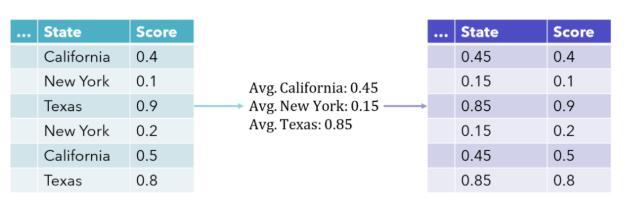
但這種編碼方法也有一些缺點。首先,它使模型更難學(xué)習(xí)均值編碼變量和另一個變量之間的關(guān)系,僅基于列與目標的關(guān)系就在列中繪制相似性。
而最主要的是,這種編碼方法對 y 變量非常敏感,這會影響模型提取編碼信息的能力。
由于該類別的每個值都被相同的數(shù)值替換,因此模型可能會過擬合其見過的編碼值(例如將 0.8 與完全不同的值相關(guān)聯(lián),而不是 0.79),這是把連續(xù)尺度上的值視為嚴重重復(fù)的類的結(jié)果。
因此,需要仔細監(jiān)控 y 變量,以防出現(xiàn)異常值。要實現(xiàn)這個目的,就要使用 category_encoders 庫。由于目標編碼器是一種有監(jiān)督方法,所以它同時需要 X 和 y 訓(xùn)練集。
- from category_encoders import TargetEncoder
- enc = TargetEncoder(cols=['Name_of_col','Another_name'])
- training_set = enc.fit_transform(X_train, y_train)
留一法編碼
留一法(Leave-one-out)編碼試圖通過計算平均值(不包括當前行值)來彌補對 y 變量的依賴以及值的多樣性。這使異常值的影響趨于平穩(wěn),并創(chuàng)建更多樣化的編碼值。

由于模型不僅要面對每個編碼類的相同值,還要面對一個范圍值,因此它可以更好地泛化。
在實現(xiàn)方面,可以使用 category_encoders 庫中的 LeaveOneOutEncoder。
- from category_encoders import LeaveOneOutEncoder
- enc = LeaveOneOutEncoder(cols=['Name_of_col','Another_name'])
- training_set = enc.fit_transform(X_train, y_train)
實現(xiàn)類似效果的另一種策略是將正態(tài)分布的噪聲添加到編碼分數(shù)中,其中標準差是可以調(diào)整的參數(shù)。
貝葉斯目標編碼
貝葉斯目標編碼(Bayesian Target Encoding)是一種使用目標作為編碼方法的數(shù)學(xué)方法。僅使用均值可能是一種欺騙性度量標準,因此貝葉斯目標編碼試圖結(jié)合目標變量分布的其他統(tǒng)計度量。例如其方差或偏度(稱為高階矩「higher moments」)。
然后通過貝葉斯模型合并這些分布的屬性,從而產(chǎn)生一種編碼,該編碼更清楚類別目標分布的各個方面,但是結(jié)果的可解釋性比較差。
證據(jù)權(quán)重
證據(jù)權(quán)重(Weight of Evidence,簡稱 WoE)是另一種關(guān)于分類自變量和因變量之間關(guān)系的方案。WoE 源自信用評分領(lǐng)域,曾用于區(qū)分用戶是違約拖欠還是已經(jīng)償還貸款。證據(jù)權(quán)重的數(shù)學(xué)定義是優(yōu)勢比的自然對數(shù),即:
- ln (% of non events / % of events)
WoE 越高,事件發(fā)生的可能性就越大。「Non-events」是不屬于某個類的百分比。使用證據(jù)權(quán)重與因變量建立單調(diào)關(guān)系,并在邏輯尺度上確保類別,這對于邏輯回歸來說很自然。WoE 是另一個衡量指標「Information Value」的關(guān)鍵組成部分。該指標用來衡量特征如何為預(yù)測提供信息。
- from category_encoders import WOEEncoder
- enc = WOEEncoder(cols=['Name_of_col','Another_name'])
- training_set = enc.fit_transform(X_train, y_train)
這些方法都是有監(jiān)督編碼器,或者是考慮目標變量的編碼方法,因此在預(yù)測任務(wù)中通常是更有效的編碼器。但是,當需要執(zhí)行無監(jiān)督分析時,這些方法并不一定適用。
非線性 PCA
非線性 PCA(Nonlinear PCA)是一種使用分類量化來處理分類變量的主成分分析(PCA)方法。它會找到對類別來說的最佳數(shù)值,從而使常規(guī) PCA 的性能(可解釋方差)最大化。



















