摳圖精細到發絲,Adobe處理6000×6000高分辨率圖像
很多深度學習方法實現了不錯的摳圖效果,但它們無法很好地處理高分辨率圖像。而現實世界中需要使用摳圖技術的圖像通常是分辨率為 5000 × 5000 甚至更高的高分辨率圖像。如何突破硬件限制,將摳圖方法應用于高分辨率圖像?來自 UIUC、Adobe 研究院和俄勒岡大學的研究者提出了一種新方法。
摳圖是圖像和視頻編輯與合成的關鍵技術。通常,深度學習方法會以整個輸入圖像和相關的 trimap 作為輸入,使用卷積神經網絡來推斷前景蒙版(alpha matte)。這種方法在圖像摳圖領域實現了 SOTA 結果。但是,由于硬件限制,這些方法在實際的摳圖應用中可能會失敗,因為現實世界中需要摳圖的輸入圖像大多具備很高的分辨率。
近日,來自伊利諾伊大學香檳分校(UIUC)、Adobe 研究院和俄勒岡大學的研究者提出了一種名為 HDMatt 的新方法,這是首個處理高分辨率輸入圖像的深度學習摳圖方法。
早在 2017 年,Adobe 等機構就發表論文《Deep Image Matting》,采用大規模數據集與深度神經網絡學習圖像的自然結構,進一步分離圖像的前景與背景。而那篇論文的一作 Ning Xu 正是這篇論文的第二作者。只不過,研究者這次將矛頭對準了高分辨率圖像。
論文地址:https://arxiv.org/pdf/2009.06613.pdf
具體來說,HDMatt 方法使用新型模塊設計,以基于 patch 的剪裁 - 拼接方式(crop-and-stitch)為高分辨率輸入圖像進行摳圖,進而解決不同 patch 之間的語境依賴性和一致性問題。基于 patch 的原版推斷方法單獨計算每個 patch,而該研究提出了新的模塊——CrossPatch Contextual module (CPC),該模塊由給定的 trimap 指導,對跨 patch 語境依賴性進行建模。
大量實驗表明了該方法的有效性及其對于高分辨率輸入圖像的必要性。HDMatt 方法在 Adobe Image Matting 和 AlphaMatting 基準上均實現了新的 SOTA 性能,并且在更真實的高分辨率圖像上獲得了優秀的效果。
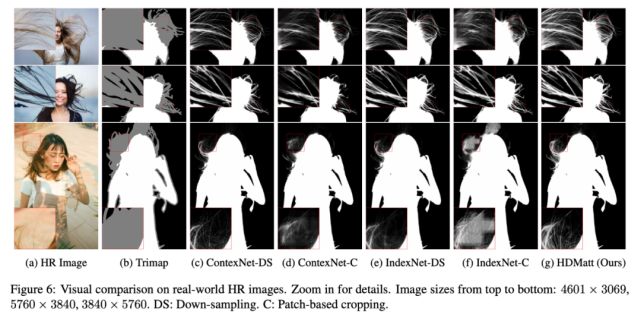
下圖展示了,在處理高分辨率圖像時,HDMatt 方法與之前最優方法 ContextNet 的對比結果:

ContextNet 分別應用了下采樣 (DS) 和剪裁 (C) 策略。從圖中可以看出,DS 導致細節模糊,剪裁則導致跨 patch 不一致問題。
而該研究提出的 HDMatt 方法解決了這兩個缺陷,摳圖效果與真值(上圖 c)最接近,這說明該方法能夠擬合精細細節。
該研究的主要貢獻有:
這是首個基于深度學習的高分辨率圖像摳圖方法,在硬件資源限制下使現實世界中的高質量 HR 摳圖成為現實。
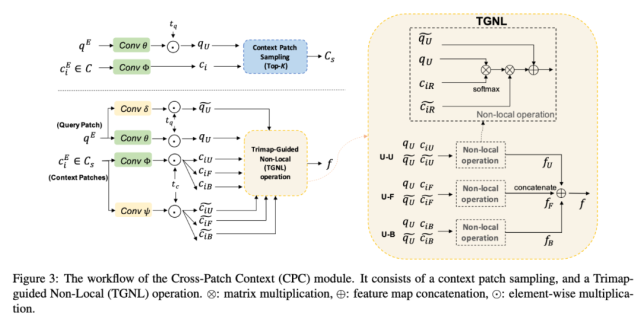
提出一種新型模塊 CPC,用來捕獲 patch 之間的長程語境依賴性。在 CPC 內部,新提出的 Trimap-Guided Non-Local(TGNL)操作旨在高效傳播來自 reference patch 不同區域的信息。
在定量和定性實驗方面,HDMatt 方法在 Adobe Image Matting (AIM)、AlphaMatting 基準和真實高分辨率圖像數據集上均實現了新的 SOTA 性能。
HDMatt 方法
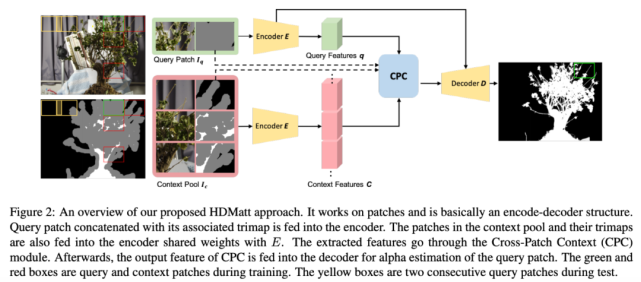
為了解決高分辨率圖像的摳圖問題,該研究提出 HDMatt 方法,該方法首先將輸入圖像和 trimap 剪裁為 patch,然后估計每個 patch 的 alpha 值。僅使用一個 patch 的信息會導致信息損失以及不同 patch 之間的預測不一致問題。因此,該研究提出新型 Cross-Patch Context Module (CPC) 模塊,高效利用每個 query patch 的跨 patch 信息。最后,將每個 patch 的估計 alpha 值連接,輸出整個圖像最終的前景蒙版。
下圖 2 展示了 HDMatt 方法的整體框架:
下圖 3 展示了 CPC 模塊的工作流程:
實驗
Adobe Image Matting 基準數據集
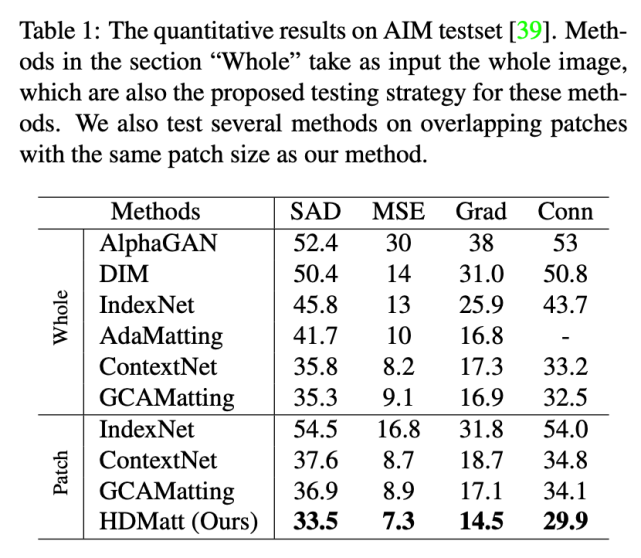
下表 1 展示了 HDMatt 方法與其他 SOTA 方法在 Adobe Image Matting 測試集上的性能對比結果。HDMatt 方法在所有評估度量指標上均優于其他方法。
研究人員還對這些方法(包括 IndexNet 和 ContextNet)的實際效果進行了對比,如下圖 4 所示:
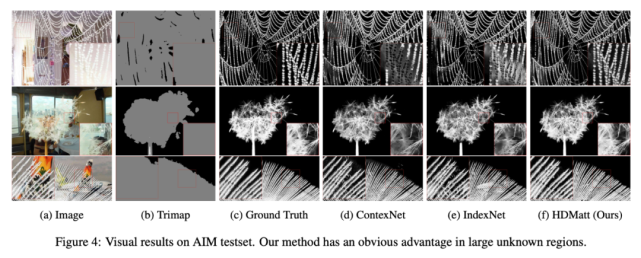
從中可以看出,HDMatt 方法能夠更好地處理大型未知區域(即極少前景或背景信息的區域)。
AlphaMatting 基準數據集
表 2 列出了在 AlphaMatting 基準數據集上 SAD 指標表現最優的四個方法,HDMatt 方法在具備較大或用戶 trimap 的圖像上表現優異。這進一步證實了,當 trimap 中存在大量未知區域時,HDMatt 方法可以有效捕獲長程語境依賴性。

下圖展示了不同方法在 AlphaMatting 測試集上的摳圖結果,自左向右分別是輸入圖像、Trimap、AdaMatting [1]、SampleNet [35]、GCA Matting [24] 和 HDMatt。從圖中可以看出,最右一列 HDMatt 方法的摳圖效果最精細。

真實圖像
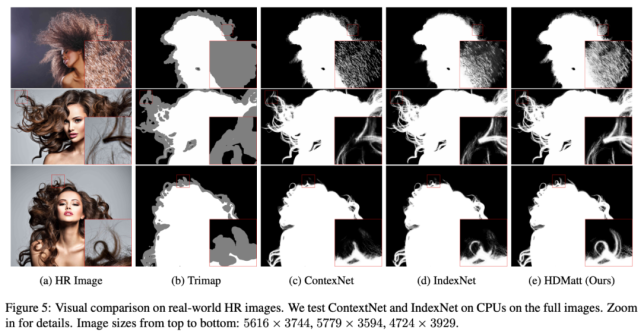
除了這些數據集以外,研究人員還在網上收集了一些分辨率最高可達 6000 × 6000 的高分辨率圖像,并在這些真實圖像上進行測試。
下圖 5 展示了將整張圖像作為輸入時,IndexNet、ContextNet 和 HDMatt 方法的性能。從結果中可以看到,HDMatt 方法能夠提取更精細精確的細節,同時推斷速度也更快。不過,該方法仍丟失了一些最精微的細節。
基于 Context Patch 的注意力可視化
下圖 7 展示了在給定 query patch 上基于選定 context patch 的注意力圖:

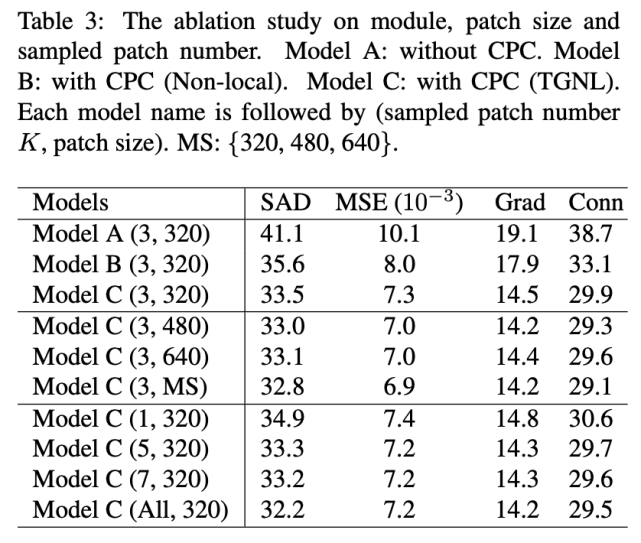
控制變量研究
下表展示了控制變量研究的結果: