從數(shù)據(jù)到大數(shù)據(jù),數(shù)據(jù)技術&工具的演變
編輯導語:大數(shù)據(jù)近些年來是一個十分火熱的話題,關于大數(shù)據(jù)的文章也是數(shù)不勝數(shù)。本文作者通過梳理自己看過的大數(shù)據(jù)相關的資料和書籍,為我們介紹了從“小數(shù)據(jù)”演化為“大數(shù)據(jù)”的過程是怎樣的?并且分享了一些數(shù)據(jù)技術以及工具。
對于大數(shù)據(jù),叮當一直都很感興趣,最近正好在看數(shù)據(jù)相關的書和資料,就把這些東西梳理了一下。本文將用4張邏輯圖為主線,簡單介紹一個產(chǎn)品從“小數(shù)據(jù)”演化為“大數(shù)據(jù)”的過程,及可能用到的工具。
本文核心邏輯:
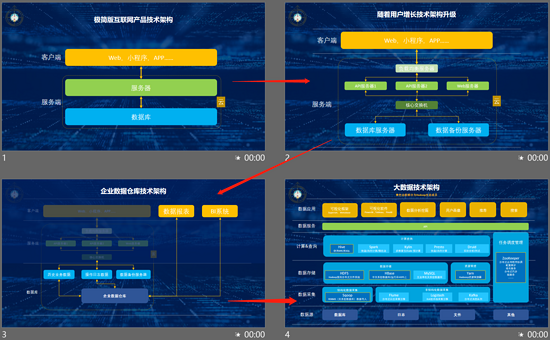
一、一個簡陋版互聯(lián)技術架構
假設我們要搭建一個小網(wǎng)站,在不使用成熟SaaS產(chǎn)品的前提下,我們的產(chǎn)品里面最少要有以下兩個部分:
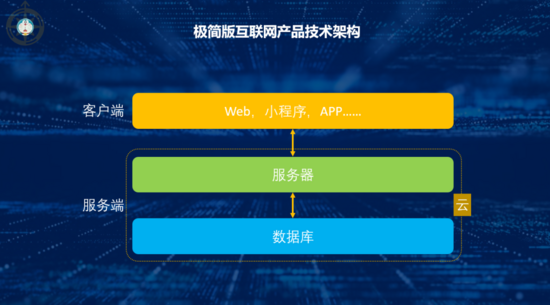
1. 客戶端
可以是APP,小程序,甚至是一個Web網(wǎng)站,作為入口給我們的用戶訪問。
2. 服務端
服務端包括應用服務器和數(shù)據(jù)庫,應用服務器用來部署應用端程序,處理前端請求,并進行服務響應;數(shù)據(jù)庫用來存儲數(shù)據(jù),服務器通過專門與數(shù)據(jù)庫交互的程序對數(shù)據(jù)庫進行讀寫操作(如:SQL)。
1. 我們是如何與技術系統(tǒng)交互的?
假設一個場景:張三打開了一個小網(wǎng)站,打開后出現(xiàn)了登錄界面,張三輸入自己的賬號和密碼之后點擊“登錄”,這時客戶端會發(fā)送給服務端一個請求,查詢一下數(shù)據(jù)庫里有沒有張三的賬號信息。
如果數(shù)據(jù)庫有的話張三就能登錄成功,可以使用小網(wǎng)站了;如果數(shù)據(jù)庫沒有張三的賬號信息,可能就會引導張三先進行注冊,注冊成功后數(shù)據(jù)庫中的用戶表中就會新增一條張三的信息,張三就能愉快的使用小網(wǎng)站了。
我們通過客戶端入口與這個系統(tǒng)交互,我們通過操作客戶端界面,對服務端進行請求拉取服務器&數(shù)據(jù)庫中的信息,給予我們反饋。
2. 服務器與數(shù)據(jù)庫有什么區(qū)別?
一般我們常稱為“服務器”的全稱叫“應用服務器”,數(shù)據(jù)庫全稱叫“數(shù)據(jù)庫服務器”,它們都是服務器,只是由于應用環(huán)境的不同,需要的性能不同做了區(qū)分。
數(shù)據(jù)庫服務器的處理器性能要求比較高,因為其要進行頻繁的操作,內(nèi)存要求大,加快數(shù)據(jù)存取速度,應用服務器相對而言要求低一些。
3. 常用數(shù)據(jù)庫有哪些?
常用數(shù)據(jù)庫主要有“關系型數(shù)據(jù)庫”和“非關系型數(shù)據(jù)庫”:
1)關系型數(shù)據(jù)庫
折射現(xiàn)實中的實體關系,將現(xiàn)實中的實體關系拆分維度,通過關系模型表達出來(表及表與表之間的關系),常用的有MySQL(開源數(shù)據(jù)庫)、SQL Server(微軟家的)、Oracle(甲骨文家的,有完善的數(shù)據(jù)管理功能可以實現(xiàn)數(shù)據(jù)倉庫操作)。
2)非關系型數(shù)據(jù)庫
一種相對松散且可以不按嚴格結構規(guī)范進行存儲的數(shù)據(jù)庫,一邊叫NoSQL(常用的有mongoDB、 CouchDB,在MongoDB中使用鍵值對的方式表示和存儲數(shù)據(jù),鍵值類似關系型數(shù)據(jù)庫表中的字段名對應的值,在MngoDB中,使用JSON格式的數(shù)據(jù)進行數(shù)據(jù)表示和存儲)。
二、隨著用戶增長技術架構的升級
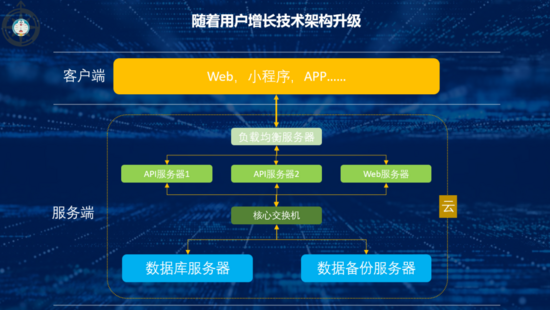
小網(wǎng)站的用戶逐漸越來越多,小網(wǎng)站變成了大網(wǎng)站,單個服務器的負載很快就到了極限,這時就需要增加多臺服務器,組成服務器組,同時引入負載均衡服務器,對流量進行動態(tài)分配。
由于數(shù)據(jù)是互聯(lián)網(wǎng)產(chǎn)品的核心資產(chǎn),為了保證系統(tǒng)數(shù)據(jù)的安全性,還需要增加數(shù)據(jù)備份服務器,多臺數(shù)據(jù)庫服務器同時運行,這樣哪怕一個數(shù)據(jù)庫出問題了,也不會影響業(yè)務正常運轉。
三、數(shù)據(jù)倉庫的誕生
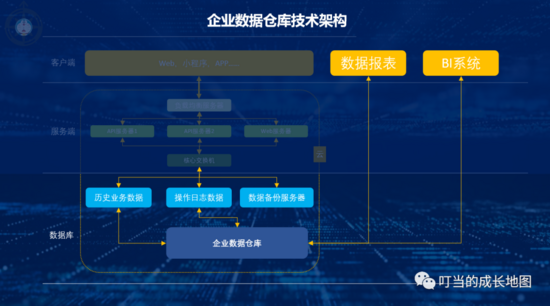
隨著產(chǎn)品用戶量越來越大,市場競爭也更加激烈,迫切需要更加準確的戰(zhàn)略決策信息,數(shù)據(jù)庫中的數(shù)據(jù)雖然對于產(chǎn)品的運營非常有用,但由于結構復雜,數(shù)據(jù)臟亂,難以理解,缺少歷史,大規(guī)模查詢等問題對商業(yè)決策和目標制定的作用甚微。
在更好的發(fā)揮數(shù)據(jù)價值,1990數(shù)據(jù)倉庫之父比爾·恩門(Bill Inmon)提出了“數(shù)據(jù)倉庫”的概念,構建一種對歷史數(shù)據(jù)進行存儲和分析的數(shù)據(jù)系統(tǒng),支撐企業(yè)的商業(yè)分析與戰(zhàn)略決策。
1. 數(shù)據(jù)倉庫的實現(xiàn)原理是什么?
數(shù)據(jù)倉庫的數(shù)據(jù)來源通常是歷史業(yè)務數(shù)據(jù)(訂單數(shù)據(jù)、商品數(shù)據(jù)、用戶數(shù)據(jù)、操作日志、行為數(shù)據(jù)……),這些數(shù)據(jù)統(tǒng)一匯總存儲至企業(yè)數(shù)據(jù)倉庫,通過對倉庫里的綜合數(shù)據(jù)進行有目的的分析支撐業(yè)務決策。
2. 數(shù)據(jù)庫與數(shù)據(jù)倉庫有什么區(qū)別?
數(shù)據(jù)庫是對實時數(shù)據(jù)進行存儲和事務性處理的系統(tǒng),而數(shù)據(jù)倉庫則是為了分析而設計。
3. 數(shù)據(jù)倉庫與大數(shù)據(jù)倉庫有什么區(qū)別?
數(shù)據(jù)倉庫與大數(shù)據(jù)倉庫的區(qū)別:大數(shù)據(jù)=海量數(shù)據(jù)+處理技術+平臺工具+場景應用,數(shù)據(jù)倉庫是一個數(shù)據(jù)開發(fā)過程,其區(qū)別主要體現(xiàn)在:商業(yè)價值、處理對象、生產(chǎn)工具三個方面。
1)商業(yè)價值
都是業(yè)務驅動的,有明確的業(yè)務場景需求,通過海量數(shù)據(jù)分析為業(yè)務提供決策依據(jù),“傳統(tǒng)數(shù)倉”出現(xiàn)更早,場景單一保守(報表,BI);而大數(shù)據(jù)技術更成熟成本更低,應用場景更多(用戶畫像、推薦、風控、搜索……)
2)處理對象
都是對數(shù)據(jù)進行獲取、加工、管理、治理、應用處理,但大數(shù)據(jù)處理數(shù)據(jù)類型更多樣化,傳統(tǒng)數(shù)倉基本只擅長處理結構化和半結構化的數(shù)據(jù)。
3)生產(chǎn)工具
“傳統(tǒng)數(shù)倉”一般采購國外知名廠商成熟方案,價格昂貴可拓展性差,“大數(shù)據(jù)”則有成套的開源技術。
建設方法:大數(shù)據(jù)技術沿用了“傳統(tǒng)數(shù)倉的數(shù)據(jù)建設理論,但由于在處理技術上新增了非結構化數(shù)據(jù),生產(chǎn)工具上新增了流式計算(比實時計算要稍微遲鈍些,但比離線計算又實時的多)。
四、大數(shù)據(jù)技術架構
1. 什么是大數(shù)據(jù)?
一種規(guī)模大到在獲取、存儲、管理、分析方面大大超出了傳統(tǒng)數(shù)據(jù)庫軟件工具能力范圍的數(shù)據(jù)集合,具有海量的數(shù)據(jù)規(guī)模(一般以TB為起始單位)、快速的數(shù)據(jù)流轉、多樣的數(shù)據(jù)類型和價值密度低四大特征——麥肯錫全球研究
根據(jù)“海量的數(shù)據(jù)規(guī)模”、“快速的數(shù)據(jù)流轉”、“多樣的數(shù)據(jù)類型”、“價值密度低”去看,符合這些特點的大都是平臺型公司,有海量用戶產(chǎn)生內(nèi)容。
Facebook基礎設施工程副總裁杰·帕里克(Jay Parikh)曾透露,F(xiàn)acebook每天處理的數(shù)據(jù)量多達500TB(1TB=1000GB)。
2. 什么是分布式計算?
看完上面,你可能會想,像Facebook每天500TB的數(shù)據(jù)量要用什么樣的技術才能處理呢?
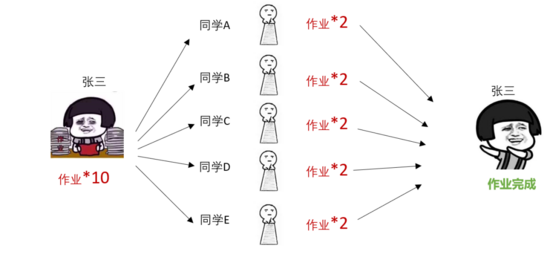
這就要引入“分布式計算”了,既然單個數(shù)據(jù)庫的計算能力有限,那我們就把大量的數(shù)據(jù)分割成多個小塊,由多臺計算機分工完成,然后將結果匯總,這些執(zhí)行分布式計算的計算機叫做集群。
如果還不理解的話我們舉個栗子:假期要結束了張三還有有10份作業(yè)沒寫,他找了5個同學,每個同學寫2份,最后匯總給張三。
大數(shù)據(jù)時代存儲計算的經(jīng)典模型,Apache基金會名下的Hadhoop系統(tǒng),核心就是采用的分布式計算架構,也是Yahoo、IBM、Facebook、亞馬遜、阿里巴巴、華為、百度、騰訊等公司,都采用技術架構(下方邏輯圖中黃框部分都是Hadoop生態(tài)的成員)。
3. 大數(shù)據(jù)架構與模塊主要有哪些?
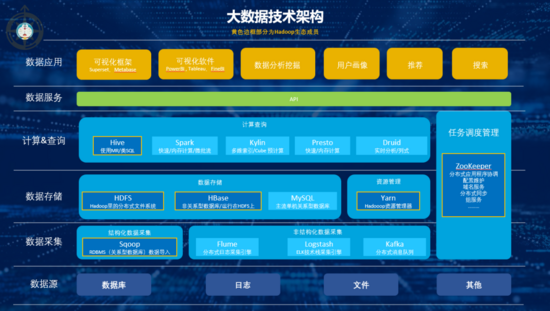
大數(shù)據(jù)架構主要可以分為:數(shù)據(jù)采集,數(shù)據(jù)存儲,計算查詢,數(shù)據(jù)服務,數(shù)據(jù)應用5個環(huán)節(jié)。
1)數(shù)據(jù)采集
通過采集工具把結構化數(shù)據(jù)進行采集、分發(fā)、校驗、清洗轉換;非結構化數(shù)據(jù)通過爬取,分詞,信息抽取,文本分類,存入數(shù)據(jù)倉庫中。
2)數(shù)據(jù)存儲
一般分3層,最底層的式ODS(操作數(shù)據(jù))層,直接存放業(yè)務系統(tǒng)抽取過來的數(shù)據(jù),將不同業(yè)務系統(tǒng)中的數(shù)據(jù)匯聚在一起;中間是DW(數(shù)據(jù)倉庫)層,存放按照主題建立的各種數(shù)據(jù)模型;最上層是DM(數(shù)據(jù)集市)層,基于DW層上的基礎數(shù)據(jù)整合匯總成分析某一個主題域的報表數(shù)據(jù)。
3)計算查詢
根據(jù)具體的需求選擇對應的解決方案:離線、非實時、靜態(tài)數(shù)據(jù)的可以用批處理方案;非離線、實時、動態(tài)數(shù)據(jù)、低延遲的場景可用流處理方案。
4)數(shù)據(jù)服務
通過API把數(shù)倉中海量的數(shù)據(jù)高效便捷的開放出去支撐業(yè)務,發(fā)揮數(shù)據(jù)價值。
5)數(shù)據(jù)應用
基于數(shù)據(jù)倉庫中結構清晰的數(shù)據(jù)高效的構建BI系統(tǒng)支撐業(yè)務決策;根據(jù)海量的數(shù)據(jù)構建以標簽樹為核心的用戶畫像系統(tǒng),為個性化推薦、搜索等業(yè)務模塊提供支撐。
4. 大數(shù)據(jù)采集模塊

一般應用于公司日志平臺,將數(shù)據(jù)緩存在某個地方,供后續(xù)的計算流程進行使用 針對不同數(shù)據(jù)源(APP,服務器,日志,業(yè)務表,各種API接口,數(shù)據(jù)文件……)有各自的采集方式。
目前市面上針對日志采集的有 Flume、Logstash、Kafka……
1)Flume
是一款 Cloudera 開發(fā)的實時采集日志引擎,主打高并發(fā)、高速度、分布式海量日志采集,支持在日志系統(tǒng)中定制各類數(shù)據(jù)發(fā)送,支持對數(shù)據(jù)簡單處理并寫給各種數(shù)據(jù)接受方,主要特點:
- 側重數(shù)據(jù)傳輸,有內(nèi)部機制確保不會丟數(shù)據(jù),用于重要日志場景;
- 由java開發(fā),沒有豐富的插件,主要靠二次開發(fā);
- 配置繁瑣,對外暴露監(jiān)控端口有數(shù)據(jù)。最初定位是把數(shù)據(jù)傳入HDFS中,跟側重于數(shù)據(jù)傳輸和安全,需要更多二次開發(fā)配置。
2)Logstash
是 Elastic旗下的一個開源數(shù)據(jù)收集引擎,可動態(tài)的統(tǒng)一不同的數(shù)據(jù)源的數(shù)據(jù)至目的地,搭配 ElasticSearch 進行分析,Kibana 進行頁面展示,主要特點:
- 內(nèi)部沒有一個persist queue(存留隊列),異常情況可能會丟失部分數(shù)據(jù);
- 由ruby編寫,需要ruby環(huán)境,插件很多;
- 配置簡單,偏重數(shù)據(jù)前期處理,分析方便 側重對日志數(shù)據(jù)進行預處理為后續(xù)解析做鋪墊,搭配ELK技術棧使用簡單。
3)Kafka
最初是由領英開發(fā),2012 年開源由Apache Incubato孵化出站。以為處理實時數(shù)據(jù)提供一個統(tǒng)一、高吞吐、低延遲的平臺,適合作為企業(yè)級基礎設施來處理流式數(shù)據(jù) (本質(zhì)是:按照分布式事務日志架構的大規(guī)模發(fā)布/訂閱消息隊列)。
4)Sqoop
與上面的日志采集工具不同,Sqoop的主要功能是為 Hadoop 提供了方便的 RDBMS(關系型數(shù)據(jù)庫)數(shù)據(jù)導入功能,使得傳統(tǒng)數(shù)據(jù)庫數(shù)據(jù)向 HBase 中遷移變的非常方便。
5. 大數(shù)據(jù)存儲&資源管理模塊

在數(shù)據(jù)量小的時候一般用單機數(shù)據(jù)庫(如:MySQL) 但當數(shù)據(jù)量大到一定程度就必須采用分布式系統(tǒng)了,Apache基金會名下的Hadhoop系統(tǒng)是大數(shù)據(jù)時代存儲計算的經(jīng)典模型。
1)HDFS
是 Hadoop里的分布式文件系統(tǒng),為HBase 和 Hive提供了高可靠性的底層存儲支持。
2)HBase
是Hadoop數(shù)據(jù)庫,作為基于非關系型數(shù)據(jù)庫運行在HDFS上,具備HDFS缺乏的隨機讀寫能力,比較適合實時分析。
3)Yarn
是一種新的 Hadoop 資源管理器,它是一個通用資源管理系統(tǒng),可為上層應用提供統(tǒng)一的資源管理和調(diào)度,它的引入為集群在利用率、資源統(tǒng)一管理和數(shù)據(jù)共享等方面帶來了巨大好處。
6. 大數(shù)據(jù)計算查詢模塊
這里首先要介紹一下批處理和流處理的區(qū)別:
- 批計算:離線場景、靜態(tài)數(shù)據(jù)、非實時、高延遲(場景:數(shù)據(jù)分析,離線報表……)
- 流計算:實時場景,動態(tài)數(shù)據(jù),實時,低延遲(場景:實時推薦,業(yè)務監(jiān)控……)
大數(shù)據(jù)常用的計算查詢引擎主要有:Hive、Spark、Presto、Presto、Kylin、Druid……

1)Hive
是基于Hadoop的一個數(shù)據(jù)倉庫工具,可以將結構化的數(shù)據(jù)文件映射為一張數(shù)據(jù)庫表,并提供完整的sql查詢功能,可以將sql語句轉換為MapReduce任務進行運行,其優(yōu)點是學習成本低。
2)Spark
Spark是加州大學伯克利分校AMP實驗室所開源的專門用于大數(shù)據(jù)量下的迭代式計算,是為了跟 Hadoop 配合:
- 批處理模式下的類Hadoop MapReduce的通用并行框架,Spark 與 MapReduce 不同,它將數(shù)據(jù)處理工作全部在內(nèi)存中進行,提高計算性能;
- 流處理模式下,Spark 主要通過 Spark Streaming 實現(xiàn)了一種叫做微批(Micro-batch)的概念可以將數(shù)據(jù)流視作一系列非常小的“批”,借此即可通過批處理引擎的原生語義進行處理;
- Spark適合多樣化工作負載處理任務的場景,在批處理方面適合眾數(shù)吞吐率而非延遲的工作負載,SparkSQL兼容可以把Hive作為數(shù)據(jù)源spark作為計算引擎。
3)Presto
由 Facebook 開源,是一個分布式數(shù)據(jù)查詢框架,原生集成了 Hive、Hbase 和關系型數(shù)據(jù)庫。但背后的執(zhí)行模式跟Spark類似,所有的處理都在內(nèi)存中完成,大部分場景下要比 Hive 快一個數(shù)量級。
4)Kylin
Cube 預計算技術是其核心,基本思路是預先對數(shù)據(jù)作多維索引,查詢時只掃描索引而不訪問原始數(shù)據(jù)從而提速。劣勢在于每次增減維度必須對 Cube 進行歷史數(shù)據(jù)重算追溯,非常消耗時間。
5)Druid
由 MetaMarket 開源,是一個分布式、面向列式存儲的準實時分析數(shù)據(jù)存儲系統(tǒng),延遲性最細顆粒度可到 5 分鐘。它能夠在高并發(fā)環(huán)境下,保證海量數(shù)據(jù)查詢分析性能,同時又提供海量實時數(shù)據(jù)的查詢、分析與可視化功能。
7. 數(shù)據(jù)可視化模塊

1)可視化框架
開源可視化框架:業(yè)界比較有名的式Superset和Metabase
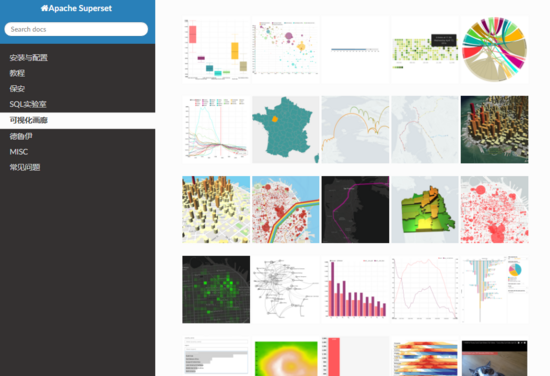
Superset的方案更加完善,支持聚合不同數(shù)據(jù)源形成對應的指標,再通過豐富的圖表類型進行可視化,在時間序列分析上比較出色,與Druid深度集成,可快速解析大規(guī)模數(shù)據(jù)集;但不支持分組管理和圖表下鉆及聯(lián)動功能,權限管理不友好。
Metabase比較重視非技術人員的使用體驗,界面更加美觀,權限管理上做的比較完善,無需賬號也可以對外共享圖表和數(shù)據(jù)內(nèi)容;但在時間序列分析上 不支持不同日期對比,還需要自動逸SQL實現(xiàn),每次查詢只能針對一個數(shù)據(jù)庫,操作比較繁瑣。
2)可視化軟件
商用軟件主流的主要有:PowerBI 、Tableau、FineBI
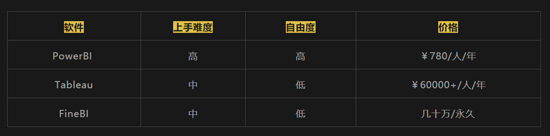
Tableau:操作簡單,可視化,基本所有的功能都可以拖拽實現(xiàn),但價格貴,且數(shù)據(jù)清洗功能一般,需要有較好的數(shù)據(jù)倉庫支持 ;
FineBI:操作簡單,與Tableau類似,但數(shù)據(jù)清洗能力比Tableau要好,付費方式采用按功能模塊收費,永久買斷;
PowerBI:可以做復雜報表,篩選、計算邏輯清晰,可自定義,但很多功能要用DAX編程序,托拉拽能實現(xiàn)的功能很有限,不易入門。