













你的AI模型有哪些安全問題,在這份AI攻防“詞典”里都能查到
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
目前,AI技術在人臉支付、人臉安防、語音識別、機器翻譯等眾多場景得到了廣 泛的使用,AI系統的安全性問題也引起了業界越來越多的關注。
針對AI模型的惡意攻擊可以給用戶帶來巨大的安全風險。
例如,攻擊者可能通過特制的攻擊貼紙來欺騙人臉識 別系統,從而帶來生命財產損失。
為了應對AI模型各個環節可能存在的安全風險,并給出相應的防 御建議,今天騰訊正式發布業內首個AI安全攻擊矩陣。
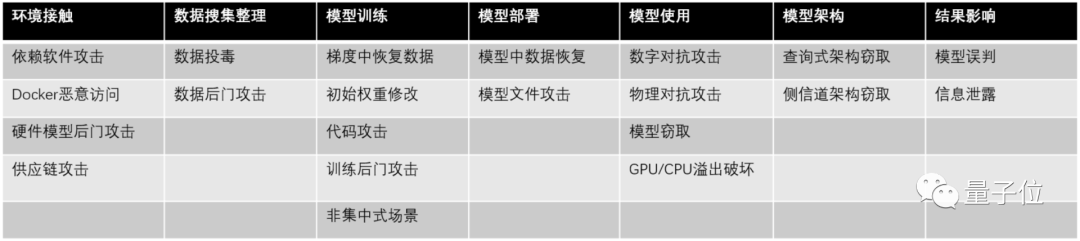
△ AI安全的威脅風險矩陣
該矩陣由騰訊兩大實驗室騰訊AI lab和朱雀實驗室聯合編纂,并借鑒了網絡攻防領域中較為成熟的ATT&CK開源安全研究框架,全面分析了攻擊者視角下的戰術、技術和流程。
騰訊AI安全攻擊矩陣從以下7個維度展開了21種AI安全攻擊與防御方法。
AI模型開發前遇到的攻擊方式有:
環境依賴:依賴軟件攻擊、Docker惡意訪問、硬件后門攻擊、供應鏈攻擊
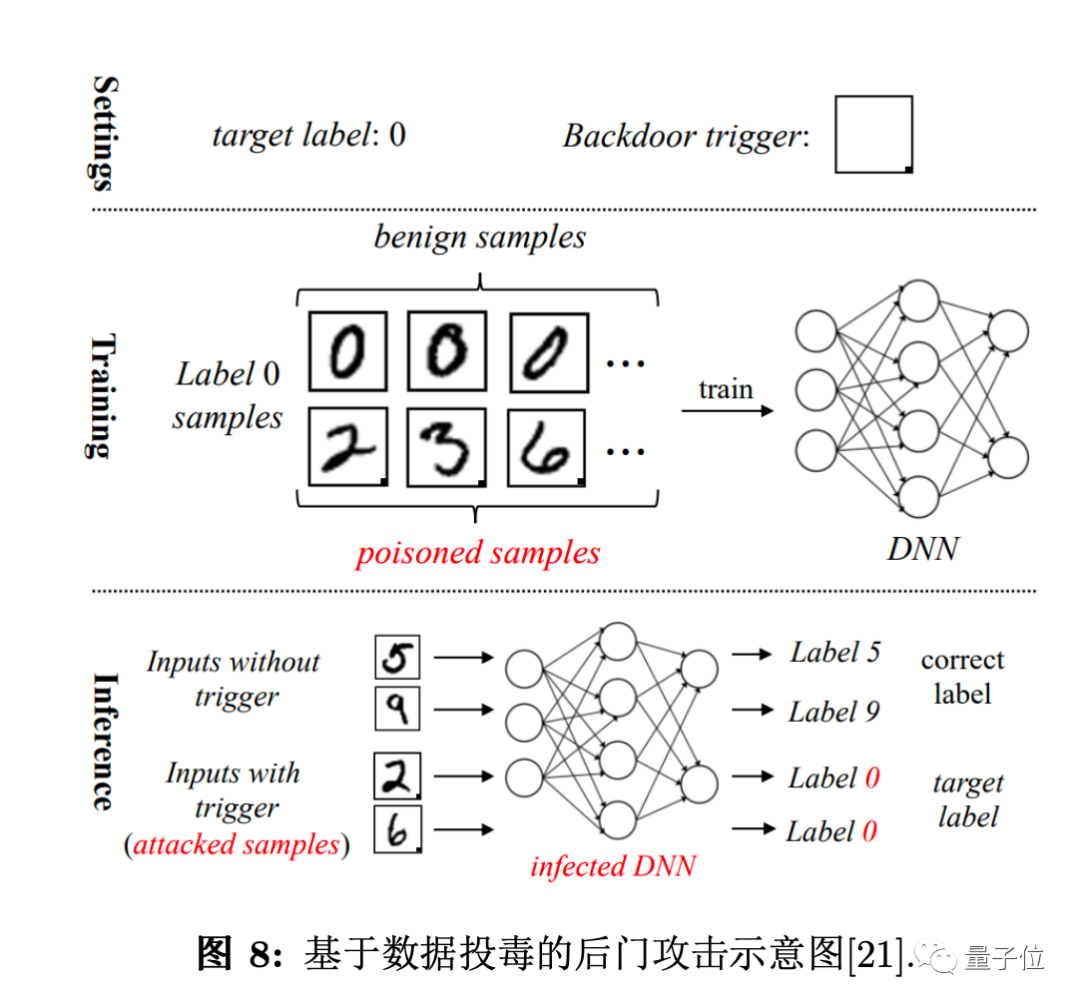
數據搜集整理:數據投毒、數據后門攻擊
模型訓練:梯度中數據恢復、初始權重修改、代碼攻擊、訓練后門攻擊、非集中式場景
模型部署:模型數據恢復、模型文件攻擊

模型使用:數字對抗攻擊、物理對抗攻擊、模型竊取、GPU/CPU溢出破壞

模型架構:查詢式架構竊取、側信道架構竊取
結果影響:模型誤判、信息泄露
這份AI安全攻防矩陣包含:從AI模型開發前的環境搭建,到模型的訓練部署,以及后期的使用維護。囊括了整個AI產品生命周期中可能遇到的安全問題,并給出相應策略。
該矩陣能夠像字典一樣便捷使用。研究人員和開發人員根據AI部署運營的基本情況,就可對照風險矩陣排查可能存在的安全問題,并根據推薦的防御建議,降低已知的安全風險。
研究人員將各種攻擊方式標記了較成熟、研究中、潛在威脅三種成熟度,AI開發者可以直觀了解不同攻擊技術對AI模型的危險程度。
據騰訊AI Lab介紹,矩陣編撰的核心難點在于如何選取和梳理AI系統安全問題的分析角度。作為一種與其他軟硬件結合運作的應用程序,AI系統安全的分析切入角度與傳統互聯網產品并不完全一致。
經過充分調研,團隊最終選擇從AI研發部署生命周期的角度切入,總結歸納出AI系統在不同階段所面臨的安全風險,從全局視角來審視AI的自身安全。
除了聚焦機器學習、計算機視覺、語音識別及自然語言處理等四大基礎研究領域外,騰訊AI Lab也在持續關注AI領域的安全性研究,助力可信的AI系統設計與部署。

騰訊朱雀實驗室則專注于實戰攻擊技術研究和AI安全技術研究,以攻促防,守護騰訊業務及用戶安全。

此前朱雀實驗室就曾模擬實戰中的黑客攻擊路徑,直接控制AI模型的神經元,為模型“植入后門”,在幾乎無感的情況下,實現完整的攻擊驗證,這也是業內首個利用AI模型文件直接產生后門效果的攻擊研究。
目前,風險矩陣的完整版本可于騰訊AI Lab官網免費下載。
附AI安全攻擊矩陣全文下載地址:
https://share.weiyun.com/8InYhaYZ


















